目录
基于PyGame实现FlappyBird中的强化学习(基于DQN),自动玩游戏。
禁止转载,侵权必究!Update 2020.12.2
前言
PyGame是一个2D的游戏环境,已经有20年的历史了,目前还在维护中。任何Python程序员可以基于它的基础库开发小游戏。但是本章用到的环境是基于它,为强化学习定制开发的模拟器。这个模拟器叫PyGame-Learning-Environment。PLE主要为DQN算法提供接口,比如实时状态,游戏是否结束,当前得分。
环境安装
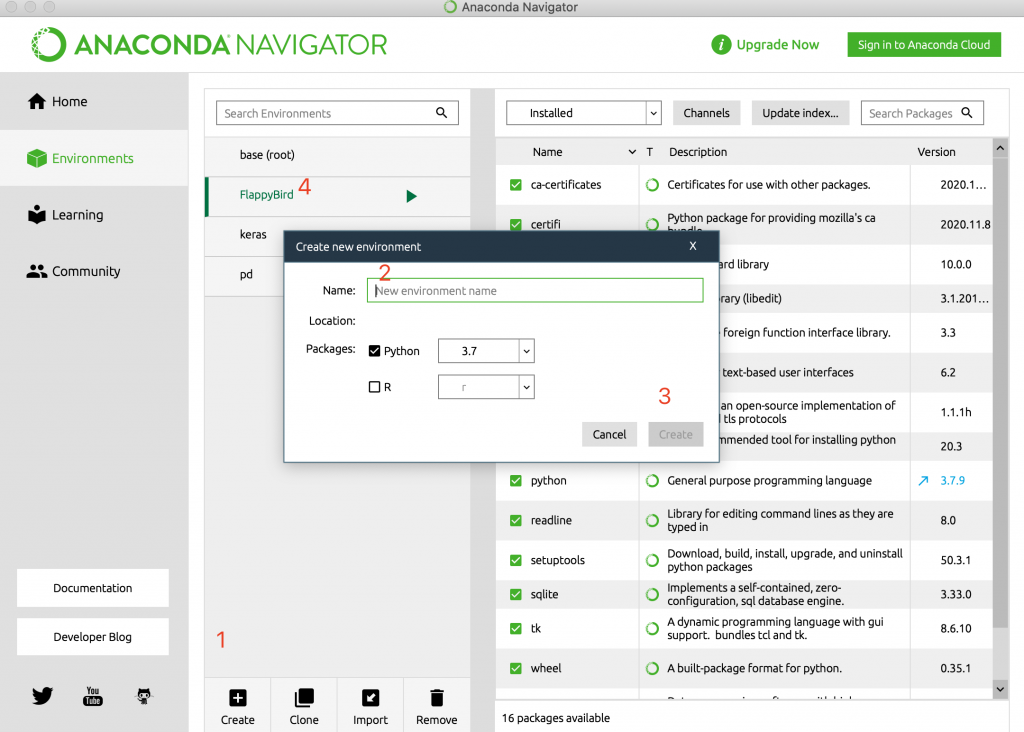
1. 在ANACONDA中创建独立编程环境
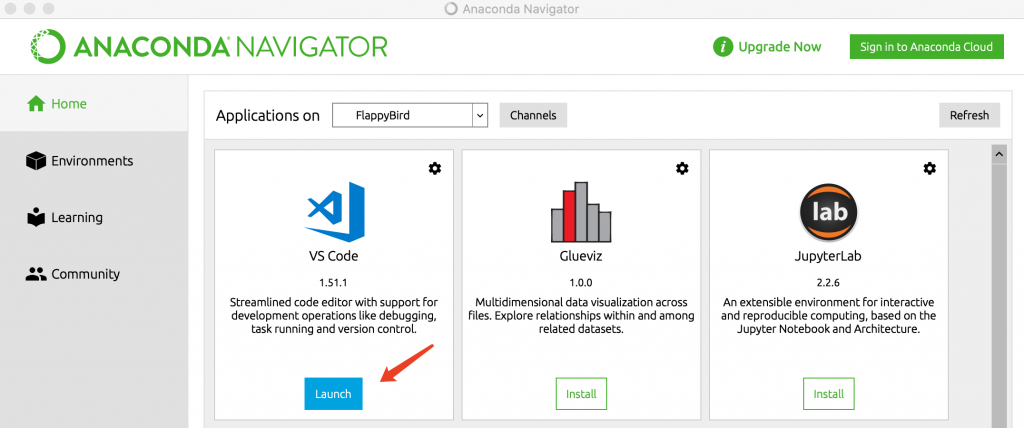
2.在ANACONDA中启动VS Code
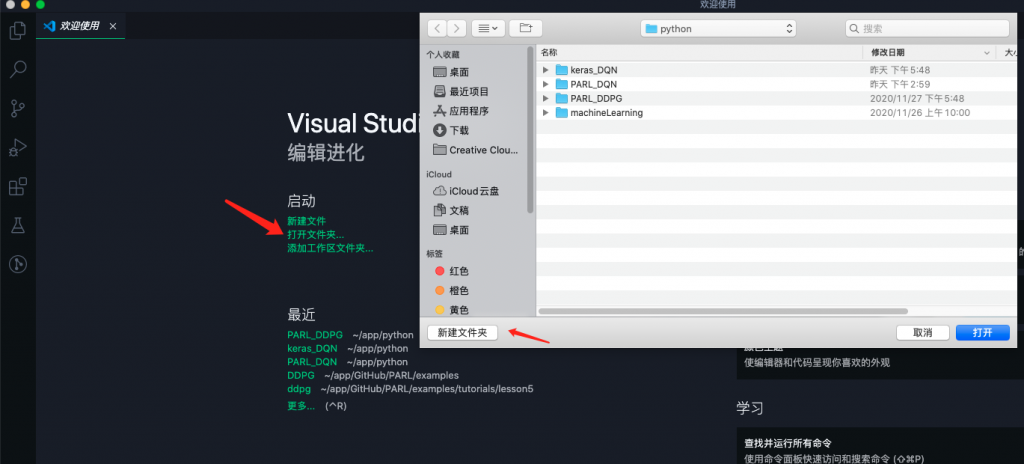
3.创建FlappyBird项目
4.安装项目依赖包
菜单–>终端–>新终端,打开窗口后输入以下命令:
(base) ➜ FlappyBird_DQN conda env list
# conda environments:
#
base * /opt/anaconda3
FlappyBird /opt/anaconda3/envs/FlappyBird
keras /opt/anaconda3/envs/keras
pd /opt/anaconda3/envs/pd
(base) ➜ FlappyBird_DQN conda activate FlappyBird
(FlappyBird) ➜ FlappyBird_DQN 5.安装百度飞桨PaddlePaddle和它的依赖库
(FlappyBird) ➜ FlappyBird_DQN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple paddlepaddle==1.8.2因为paddlepaddle已经升级到了2.0rc, 为了避免版本兼容性问题,指定了版本1.8.2
6.安装PARL强化学习库
(FlappyBird) ➜ FlappyBird_DQN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple parl7.安装PyGame库
(FlappyBird) ➜ FlappyBird_DQN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pygame8.安装PyGame强化学习模拟器环境
git clone https://github.com/ntasfi/PyGame-Learning-Environment.git
cd PyGame-Learning-Environment/
pip install -e .9.查看安装结果:
(FlappyBird) ➜ FlappyBird_DQN pip list | grep ple
ple 0.0.1 /Users/ouyang/app/GitHub/PyGame-Learning-Environment
(FlappyBird) ➜ FlappyBird_DQN python
Python 3.7.9 (default, Aug 31 2020, 07:22:35)
[Clang 10.0.0 ] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import ple
pygame 2.0.0 (SDL 2.0.12, python 3.7.9)
Hello from the pygame community. https://www.pygame.org/contribute.html
couldn't import doomish
Couldn't import doom
>>> 编码
1.Model
class Model(parl.Model):
def __init__(self, act_dim):
hid1_size = 128
hid2_size = 128
self.fc1 = layers.fc(size=hid1_size, act='relu')
self.fc2 = layers.fc(size=hid2_size, act='relu')
self.fc3 = layers.fc(size=act_dim, act=None)
def value(self, obs):
h1 = self.fc1(obs)
h2 = self.fc2(h1)
Q = self.fc3(h2)
return Q2.Agent
import numpy as np
import paddle.fluid as fluid
import parl
from parl import layers
class Agent(parl.Agent):
def __init__(self, algorithm, obs_dim, act_dim, e_greed=0.1, e_greed_decrement=0):
assert isinstance(obs_dim, int)
assert isinstance(act_dim, int)
self.obs_dim = obs_dim
self.act_dim = act_dim
super(Agent, self).__init__(algorithm)
self.global_step = 0
self.update_target_steps = 200
self.e_greed = e_greed
self.e_greed_decrement = e_greed_decrement
def build_program(self):
self.pred_program = fluid.Program()
self.learn_program = fluid.Program()
with fluid.program_guard(self.pred_program):
obs = layers.data(name='obs', shape=[self.obs_dim], dtype='float32')
self.value = self.alg.predict(obs)
with fluid.program_guard(self.learn_program):
obs = layers.data(name='obs', shape=[self.obs_dim], dtype='float32')
action = layers.data(name='act', shape=[1], dtype='int32')
reward = layers.data(name='reward', shape=[], dtype='float32')
next_obs = layers.data(name='next_obs', shape=[self.obs_dim], dtype='float32')
terminal = layers.data(name='terminal', shape=[], dtype='bool')
self.cost = self.alg.learn(obs, action, reward, next_obs, terminal)
def sample(self, obs):
sample = np.random.rand()
if sample < self.e_greed:
act = np.random.randint(self.act_dim)
else:
act = self.predict(obs)
self.e_greed = max(0.2, self.e_greed - self.e_greed_decrement)
return act
def predict(self, obs):
obs = np.expand_dims(obs, axis=0)
pred_Q = self.fluid_executor.run(
self.pred_program,
feed={'obs': obs.astype('float32')},
fetch_list=[self.value])[0]
pred_Q = np.squeeze(pred_Q, axis=0)
act = np.argmax(pred_Q)
return act
def learn(self, obs, act, reward, next_obs, terminal):
if self.global_step % self.update_target_steps == 0:
self.alg.sync_target()
self.global_step += 1
act = np.expand_dims(act, -1)
feed = {
'obs': obs.astype('float32'),
'act': act.astype('int32'),
'reward': reward,
'next_obs': next_obs.astype('float32'),
'terminal': terminal,
}
cost = self.fluid_executor.run(
self.learn_program, feed=feed, fetch_list=[self.cost])[0]
return cost3.ReplayMemory
import random
import collections
import numpy as np
class ReplayMemory(object):
def __init__(self, max_size):
self.buffer = collections.deque(maxlen=max_size)
def append(self, exp):
self.buffer.append(exp)
def sample(self, batch_size):
mini_batch = random.sample(self.buffer, batch_size)
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], []
for experience in mini_batch:
s, a, r, s_p, done = experience
obs_batch.append(s)
action_batch.append(a)
reward_batch.append(r)
next_obs_batch.append(s_p)
done_batch.append(done)
return np.array(obs_batch).astype('float32'), \
np.array(action_batch).astype('float32'), np.array(reward_batch).astype('float32'),\
np.array(next_obs_batch).astype('float32'), np.array(done_batch).astype('float32')
def __len__(self):
return len(self.buffer)4.训练
前面的代码是跟DQN算法相关,基本不变。而下面的代码训练代码跟具体的环境就很相关了,本章用了PLE环境,我们仔细看看跟CartPole有什么不同。
环境交互代码:
game = FlappyBird()
env = PLE(game, fps=30, display_screen=False)
env_test = PLE(game, fps=30, display_screen=False)
obs_dim = len(env.getGameState())
action_dim = 2 # 只能是up键,还有一个其它,所以是2因为FlappyBird只有一个向上飞的动作,因此action_dim有且只有2个。
训练代码:
def run_episode(agent, env, rpm):
total_reward = 0
env.init() #不同
step = 0
while True:
if step == 0: #不同
reward = env.act(None)
done = False
else:
obs = list(env.getGameState().values()) #不同
action = agent.sample(obs)
if action == 1: #不同
act = actions["up"]
else:
act = None
reward = env.act(act) #不同
isOver = env.game_over() #不同
next_obs = list(env.getGameState().values()) #不同
rpm.append((obs, action, reward, next_obs, isOver))
# train model
if (len(rpm) > MEMORY_WARMUP_SIZE) and (step % LEARN_FREQ == 0):
(batch_obs, batch_action, batch_reward, batch_next_obs,
# batch_isOver) = rpm.sample_batch(BATCH_SIZE)
batch_isOver) = rpm.sample(BATCH_SIZE)
train_loss = agent.learn(batch_obs, batch_action, batch_reward,
batch_next_obs, batch_isOver)
total_reward += reward
if isOver :
env.reset_game() # 重置游戏 #不同
break
step += 1
return total_reward主要不同点都在env对象,也就是初始化中的PLE(game, fps=30, display_screen=False)