目录
讲解reward如何设计。
禁止转载,侵权必究!Update 2020.12.14
前言
前面系列教程,我们用gym,PLE各种现成的基准环境来训练DQN,DDPG等算法。那如果我们要在生产中实践强化学习。怎么获取reward?reward取值多少?同理,怎么叫gameover?如何定义gameover。是不是随便定义?
Reward Shaping
1.在游戏最后拿到奖励时给予reward+1是否可行?
答案:不行,如果游戏需要100万帧才可能达到reward+1,那么算法收敛会异常的困难,编程中是不可行的。学术称为稀疏问题。
2.专家能否设计完美的reward?
举个例子:专家希望设定一个Reward让机器人能够找一条尽量障碍比较少的道路拿到一坛金币,他设定得到金币是+10分,走小路-1分,走草丛-2分,他认为训练出的机器人应该会优先选择走小路去拿到金币。但是在设计的过程中,他没有想到现实世界中会存在熔岩道路的情况,对于这种情况理应设计-100的Reward,但是被专家忽略了,那最终的机器人在现实场景中就会选择直接穿过熔岩,自然也就完蛋了。
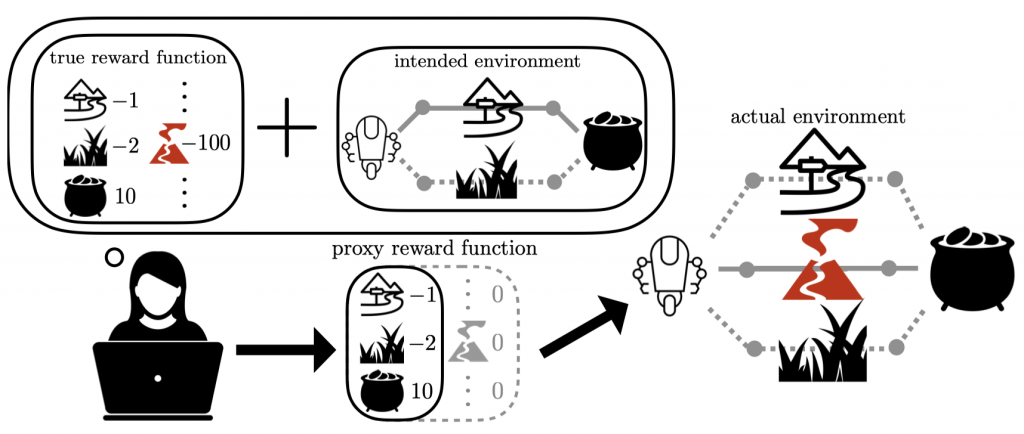
有专门的论文讲Inverse Reward Design,承认在没有完美的reward设计方法时,如何解决reward的设计。
3. “刷分”问题
为了避免稀疏问题,我们设计了一个过程,每走一步就+1分,直到我们的目标结果。这个想法看起来很美好,一切视乎会按照我们设想去走。但是聪明的智能体很快就会找到算法,跟专家对抗!比如每一步+1分,算法会一直循环这一步,这样它就可以拿到更多分。这样的设计反而会浪费工程师大量的时间。
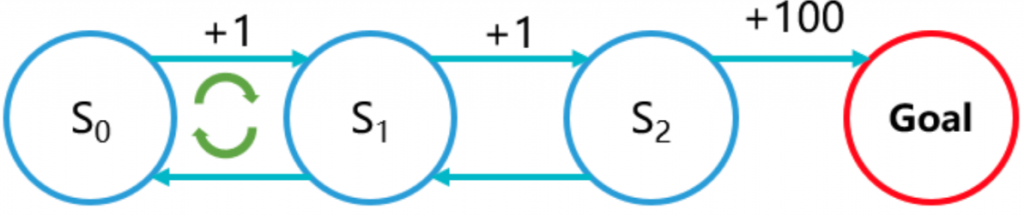
4.势能函数
1999年,吴恩达在论文中提出Potential-based reward shaping(PBRS),也就是所谓势能函数。我们直观认为目标是一个洼地,强化学习的任务是从起点(高处)走到洼地。只要是海拔更低的位置,我们就可以认为是势能增加,给与reward+1,如果智能体走到海拔更高的位置,那么势能减少,给与reward-1,这样智能体就不能“刷分”了。
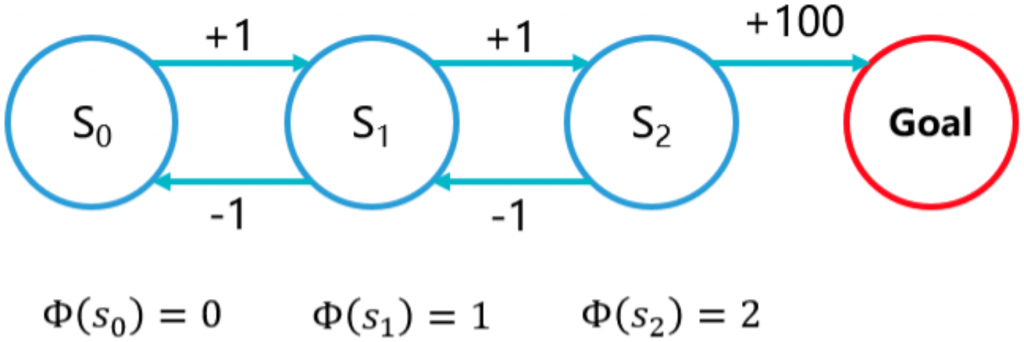
Wiewiora大神在2003年已经用数学证明,势能函数等价于给值函数增加初始值。
Reward算法
1.通过minicap抓取游戏图片
2.图片标注(人工)

3.图片分类算法
构建神经网络
import numpy as np
import argparse
import ast
import paddle
import paddle.fluid as fluid
from paddle.fluid.layer_helper import LayerHelper
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, BatchNorm, Linear
from paddle.fluid.dygraph.base import to_variable
from paddle.fluid import framework
import math
import sys
from paddle.fluid.param_attr import ParamAttr
class ConvBNLayer(fluid.dygraph.Layer):
...
class BottleneckBlock(fluid.dygraph.Layer):
...
class ResNet(fluid.dygraph.Layer):
# 根据状态定义输出的分类数class_dim,跟实际业务要匹配
def __init__(self, name_scope, layers=50, class_dim=12):
super(ResNet, self).__init__(name_scope)
...
# 定义前向计算
def forward(self, inputs, label=None):
...
划分数据集
# 受限神经网络,这里的label只能定义为0~N
if subDir == '1-7':
label = 0
elif subDir == 'bad':
label = 1
elif subDir == 'checkpoint_1-7':
label = 2
elif subDir == 'login':
label = 3
elif subDir == 'main_screen':
label = 4
elif subDir == 'other':
label = 5
elif subDir == 'play_begin':
label = 6
elif subDir == 'play_end':
label = 7
elif subDir == 'playing':
label = 8
elif subDir == 'post_login':
label = 9
elif subDir == 'pre_login':
label = 10
elif subDir == 'zuozhan':
label = 11
else:
raise('label dir error!')图片预处理
为了提升运算速度,对图片缩小100倍(1920×1080–>192×108)并处理为灰度图。
# 对读入的图像数据进行预处理
def transform_img(img):
# 将图片尺寸缩放道 192x108
img = cv2.resize(img, (192, 108))
# 读入的图像数据格式是[H, W, C]
# 使用转置操作将其变成[C, H, W]
img = np.transpose(img, (2,0,1))
img = img.astype('float32')
# 将数据范围调整到[-1.0, 1.0]之间
img = img / 255.
img = img * 2.0 - 1.0
return img算法步骤
# 定义启动点
with fluid.dygraph.guard():
model = ResNet('resnet', 50)
train(model)# 定义训练过程
def train(model):
with fluid.dygraph.guard():
print('start training ... ')
model.train()
epoch_num = 10
# 定义优化器
opt = fluid.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameter_list=model.parameters())
# 定义数据读取器,训练数据读取器和验证数据读取器
train_loader = data_loader(DATADIR, batch_size=10)
# valid_loader = valid_data_loader(VALDATADIR, batch_size=10)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
# print("batch:" + str(batch_id) + " image shape=" + str(x_data.shape) + " label shape=" + str(y_data.shape))
img = fluid.dygraph.to_variable(x_data)
# print(img.shape)
label = fluid.dygraph.to_variable(y_data)
label.stop_gradient = True
# 运行模型前向计算,得到预测值
out, acc = model(img,label)
# 进行loss计算
loss = fluid.layers.cross_entropy(out, label)
avg_loss = fluid.layers.mean(loss)
if batch_id % 10 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, avg_loss.numpy(), acc.numpy()))
# 反向传播,更新权重,清除梯度
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
# save params of model
fluid.save_dygraph(model.state_dict(), 'arknights')
# save optimizer state
fluid.save_dygraph(opt.state_dict(), 'arknights')示例源码
4.势能函数
为了简化算法,我们用PBRS方法构造state数组。
| 数据下标 | id | name | 说明 |
| s[0] | 1000 | pre_login | 预登录 |
| s[1] | 990 | login | 登录表单(保存账号) |
| s[2] | 980 | post_login | 登录后 |
| s[3] | 970 | main_screen | 主屏幕 |
| s[4] | 960 | zuozhan | 作战界面 |
| s[5] | 950 | checkpoint_1-7 | 1-7选择界面 |
| s[6] | 940 | 1-7 | 1-7开始 |
| s[7] | 930 | play_begin | 游戏开始 |
| s[8] | 920 | playing | 游戏进行中 |
| s[9] | 910 | play_end | 一局游戏结束 |
| s[10] | 0 | other | 其他过场图片 |
| s[11] | 9000 | bad | 不想agent进入的图片 |
给每个分类不同的初始势能值。根据状态转移获得reward。
假定状态转移是s[0]–>s[9],reward应该是多少呢?
直接用势能值相减,比如:s[0]–>s[1]–>s[2]–>s[3]–>s[4]–>s[5]–>s[6]–>s[7]–>s[8]–>s[9] = 90分
转移到State[other],State[other]的势能为0,相减reward为0。转移到State[bad],势能为9000,直接reward -9000,游戏结束。
注意:PARL库中的强化学习算法会把reward归一化到(-1, 1)之间。所以不要浪费时间在纠结奖励多少分!!!
5.gameover
为了简化逻辑,gameover:s[9]、s[11]、势能函数为负数、step>MAX,执行adb shell 命令结束游戏进程。
6. 明日方舟-A2C模拟器中的真实实现:
def getScore(self, s1):
# 状态没变扣一分
if s1[0] == self.stateCode:
return -1
return 1
def gameOver(self):
code = self.stateCode
# if (code == 910 or code == 1010):
# for debug 让算法快速收敛
if (code == 965):
return True
return False参考资料
常见的三种reward函数求解方法。
- Reward Shaping
- Intrinsically Motivated Reinforcement Learning
- Optimal Rewards and Reward Design