目录
本教程讲解多智能体强化学习的理论基础。
可随意转载!
多智能体强化学习的由来?
理论上使用马尔科夫决策过程(MDP)可以解决多智能强化学习的问题。本质上只是单智能体的单Action变成了多智能体的联合多Action。单智能体的Policy变成了多智能体的联合多Policy。编码上是类似的,难度不大。
为啥要搞出一套理论来做多智能体强化学习呢?
因为在很多场景下,智能体和智能体之前是不可见的 异或 是协作的。比如说agent1和agent2互相是不可见的,如果训练的时候,把他们的参数放到一起,本质上,算法认定它们是可见的,因此训练出来的效果肯定跟实际情况肯定不一样。反之,agent1和agent2是协作的,如果不把他们的参数放到一起,训练的结果必然是两个agent各干各的,也不符合实际情况。因此,用MDP开发多智能体强化学习算法,必定会落入两难的境地。
多智能体决策原理
一、部分可观察马尔科夫决策过程POMDP
假定七元组(S, A, T, R, Ω, O, γ):
其中:
S 状态
A 动作
T 状态转移S概率 T(s1, a, s2) = P(s2|s1, a)
R 奖励
Ω 观察,包含很多o
O 观察Ω的概率 O(s, a, o) = P(o|s,a) 其中o就是观察Ω中包含的对应observation
γ 衰减因子
其中(S, A, R, γ)是单智能体强化学习常见概念,就不讲了。剩下(T, Ω, O)三元组,我们来理解一下它们的含义:
在POMDP的假设中,Agent从状态S0开始,以状态转移概率函数T为指导,概率执行动作A,执行完毕后,它无法知道自己的状态,只能根据观察Ω(Partially Observation),此观察Ω来自概率函数O,来得到belief(觉得自己应该在哪个S)。
belief是什么呢?它是一个维度等于总状态空间数的one-hot向量。表示从概率上看目前应该是在哪个状态。
那么问题来了,状态概率函数T怎么算?观察概率函数O怎么算?在数学上这是很难的。
二、分散控制的马尔科夫决策过程DEC-POMDP
把Dec-POMDP表示为:M = <I, S, {Ai}, P, R, {Ωi}, O, h >
- I, agent集合
- S, 状态集合
- Ai, 某个agent i的所有动作集合
- P, 状态转移函数: P(s’ | s, a)
- R, 全局奖励函数: R(s, a)
- Ωi, 某个agent i观察到的状态o的集合, 所有agent的值汇总就是:Ω
- O, 观察的概率函数: O(o| s, a), agent观察到o的概率
- h, 步数,比如:infinite horizon表示无限步
- 无限步时,γ表示衰减, 0 ≤ γ < 1
三、算法复杂度分析

从图上我们可以看到Dec-POMDP问题是其他几个问题的泛化,在数学上有个专门的名字叫Reducibility,中文叫做“归约”或者“约化”。所以只要我们能用算法解决Dec-POMDP问题,那么其他问题都是可解决的。
简述论文结论:
- 有限步h,m个agent(m≥2)条件下,Dec-POMDP算法复杂度为NEXP-complete
- 有限步h,m个agent(m≥3)条件下,Dec-MDP算法复杂度也是NEXP-complete
NEXP-complete问题是NEXP问题的归约,我们可以先看NEXP问题的复杂度是多少?
NEXP= NTIME,也就是(2n )。
常见的NP问题复杂度是多少呢?
P问题表示在图灵多项式范围内可解。NP问题表示在每个非确定图灵多项式范围内可解。结论:NP问题已经是非常著名的难以求解的数学问题。
NP问题和NEXP问题的相对难度是怎么样的呢?
所以,在数学理论上,Dec-POMDP问题是通常是无解的。只能求近似解。
四、从IQL算法到QMIX算法
1. IQL算法
IQL(independent Q-learning)算法非常简单暴力地给每个智能体执行一个Q-learning算法。IQL把单智能体Q-learning算法直接应用在多智能体学习领域,各个智能体是各自为政的。这是此类算法的一个极端。

2. COMA算法
COMA (counterfactual multi-agent) 使用一个集中式的critic网络计算优势函数A,统一给Agenti计算对应的actioni分别去执行。所谓CTDE(central training decentralize execution)。COMA是把Actor-critic单智能体算法直接应用在多智能体学习领域,各个智能体按照集中的critic网络指令行事,它们是完全协作关系。这是此类算法的另一个极端。

因此多智能体强化学习算法必然都是在两个算法之间做平衡。Agent既不能完全独立行事,也不能完全按中心节点指令行事。比如DeepMind的经典算法VDN以及QMIX算法。
那么这些算法都在解决什么问题呢?
只要模型共享Qtot值函数,团队奖励值ri有可能仅仅是某几个智能体获得的,其它智能体并没有做贡献但缺获得了奖励值ri。这就是所谓多智能体信用分配(credit assignment)问题。
在COMA算法中,为了解决多智能体信用分配问题,提出了优势函数A(遍历Agenti动作空间μi里的所有动作,而保持其它Agent的动作空间μ–不变,计算每个Agenti的参数值。)
这个思想来自difference reward。difference reward的思想是:保持其他智能体的联合动作不动,把当前智能体的action替换为一个default action,检查值函数Q是否有变化,如果没有,代表当前智能体的action是无贡献的action,因为奖励r不是当前智能体的action获得的。但是difference reward思想有个问题,default action选谁???无法选择!!!为了解决这个问题,COMA定义了优势函数A,解决了多智能体信用分配问题。如果仔细看算法的A函数公式,它其实就是AC算法中常用的优势函数A在多智能体领域的扩展而已。
3. VDN算法
VDN:value decomposition networks。VDN算法假定:Qtot是每个智能体的Qi的算术加和。对于智能体Agenti来说,它只用最大化Qtot函数的子项Qi函数即可。如下图:


VDN的作者假定如下等式:

这个等式要成立需要满足下面的条件:

算法作者的想法是:团队的整体奖励应由所有智能体各自的奖励函数求和得到。但是真实的恒等式应该是如下:

恒等式中:子函数Qi 的输入应该是全局状态集合s,和全局动作集合α,但是VDN的实际输入为局部观察Oi 和局部动作集合αi。因此VDN要求算法满足以下条件:

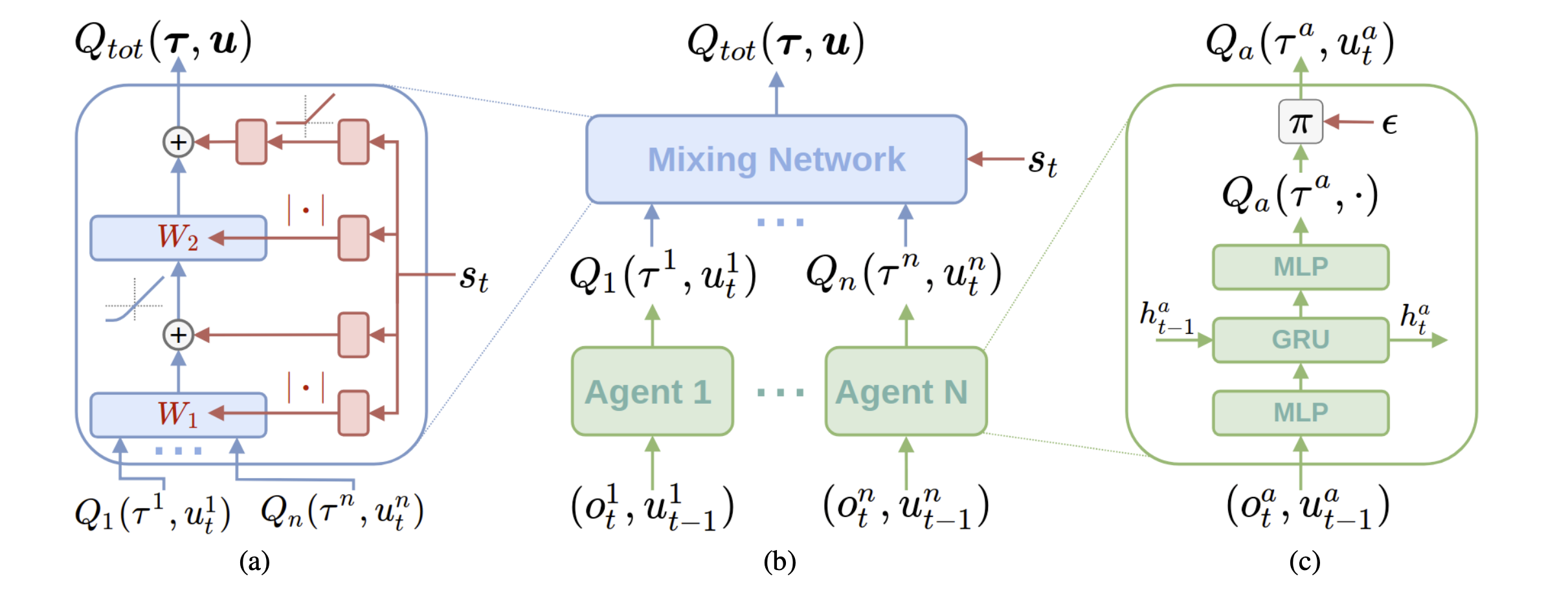
4. QMIX算法
QMIX算法作者经过研究发现:在VDN算法中上述argmax等式约束条件过于严格了。经过研究他提出了更为合理的约束条件(Q函数单调性约束)如下:

根据上述单调性理论,算法作者巧妙的设计了神经网络Mixing Network,将全局状态s引入到网络中,我们来看看这个Mixing Network:

蓝色网络(Mixing Network):单调网络(注意W1 和W2 中间偏左的单调函数示意图)
蓝色网络输入:所有agent自己的Qi序列
蓝色网络输出:Qtot
红色网络:蓝色网络的超参数生成网络,输入为全局状态s。红色网络的参数可以为正为负,只要保证输出为正数即可。(QMIX算法作者在论文中解释了,不直接将状态s作为超参数传入蓝色网络的原因,他认为这本质也增加了过度约束。)最终QMIX算法的网络结构如下:
五、PARL源码阅读 – QMIX的实现
1.加载sc2游戏环境
# 加载smac环境,使用配置scenario指定的地图,游戏难度设置为”难“
env = StarCraft2Env(
map_name=config['scenario'], difficulty=config['difficulty'])
# 类似其他强化学习环境,定义了PARL对游戏的标准封装,比如step函数,reset函数
env = SC2EnvWrapper(env)2.初始化经验回放池
rpm = EpisodeReplayBuffer(config['replay_buffer_size'])3.初始化模型(老三样之一)
根据QMIX理论部分介绍,我们清楚知道QMIX算法有2个网络,一个是DRNN网络;一个是Mixing网络。
# DRNN网络,agent用的网络
agent_model = RNNModel(config['obs_shape'], config['n_actions'],
config['rnn_hidden_dim'])
# Mixing网络,Q网络
qmixer_model = QMixerModel(
config['n_agents'], config['state_shape'], config['mixing_embed_dim'],
config['hypernet_layers'], config['hypernet_embed_dim'])4.初始化算法(老三样之二)
# PARL官方实现的QMIX算法
algorithm = QMIX(agent_model, qmixer_model, config['double_q'],
config['gamma'], config['lr'], config['clip_grad_norm'])5.初始化agent(老三样之三)
qmix_agent = QMixAgent(
algorithm, config['exploration_start'], config['min_exploration'],
config['exploration_decay'], config['update_target_interval'])6.训练
# 训练的主要逻辑跟DQN没有差别
def run_train_episode(env, agent, rpm, config):
...
# 初始化环境
state, obs = env.reset()
...
while not terminated:
# 获得动作
actions = agent.sample(obs, available_actions)
# env标准封装的step
next_state, next_obs, reward, terminated = env.step(actions)
...
...
if rpm.count > config['memory_warmup_size']:
for _ in range(2):
# 从经验回放池取batch
s_batch, a_batch, r_batch, t_batch, obs_batch, available_actions_batch,\
filled_batch = rpm.sample_batch(config['batch_size'])
# learn方法
loss, td_error = agent.learn(s_batch, a_batch, r_batch, t_batch,
obs_batch, available_actions_batch,
filled_batch)
...
...其中available_actions是来自smac提供的游戏接口。
7. Agent的sample方法
# 也是一样的e-greedy算法
def sample(self, obs, available_actions):
...
epsilon = np.random.random()
if epsilon > self.exploration:
actions = self.predict(obs, available_actions)
else:
actions = AvailableActionsSampler(available_actions).sample()
...8.env的step方法
def step(self, actions):
# smac的step
reward, terminated, _ = self.env.step(actions)
# 从smac获取最新全局状态
next_state = np.array(self.env.get_state())
last_actions_one_hot = self._get_actions_one_hot(actions)
# 获取局部观察o
next_obs = np.array(self.env.get_obs())
next_obs = np.concatenate(
[next_obs, last_actions_one_hot, self.agents_id_one_hot], axis=-1)
return next_state, next_obs, reward, terminated这里跟DQN不同了,因为这里有局部观察o和全局状态s了。而DQN算法里面state和observation是一个意思。
9.QMIX网络的实现
# 红色网络(超参数网络)定义 linear-->ReLu-->linear
self.hyper_w_1 = nn.Sequential(
nn.Linear(self.state_shape, hypernet_embed_dim), nn.ReLU(),
nn.Linear(hypernet_embed_dim, self.embed_dim * self.n_agents))
self.hyper_w_2 = nn.Sequential(
nn.Linear(self.state_shape, hypernet_embed_dim), nn.ReLU(),
nn.Linear(hypernet_embed_dim, self.embed_dim))# 红色网络输入为全局状态s
# abs使得红色网络输出为正数
w1 = paddle.abs(self.hyper_w_1(states))
w2 = paddle.abs(self.hyper_w_2(states))# 蓝色网络(Mixing Network)定义
# 蓝色网络输入为agent Q,输出为Qtot
...
# bmm:矩阵乘法
hidden = F.elu(paddle.bmm(agent_qs, w1) + b1)
y = paddle.bmm(hidden, w2) + b2
q_total = y.reshape(shape=(batch_size, -1, 1))
return q_total这里用到了elu激活函数,我们看下它的特性:

10.QMIX learn方法
...
chosen_action_global_qs = self.qmixer_model(chosen_action_local_qs,
state_batch[:, :-1, :])
target_global_max_qs = self.target_qmixer_model(
target_local_max_qs, state_batch[:, 1:, :])
# 经典的DQN Reward计算公式
target = reward_batch + self.gamma * (
1 - terminated_batch) * target_global_max_qs
td_error = target.detach() - chosen_action_global_qs
masked_td_error = td_error * mask
mean_td_error = masked_td_error.sum() / mask.sum()
loss = (masked_td_error**2).sum() / mask.sum()
...
# 这个反向传播的loss来源是:loss<--masked_td_error<--td_error
# 所以这个td-error在QMIX中是用到了的,不同于DQN
loss.backward()六、训练基于QMIX的星际争霸微操
在Win10本机训练的时候,游戏训练过程中,会意外报错:找不到显卡,因此放到AIStudio上训练,只开CPU版本,单线程训练。结果如图:

这个demo的问题是速度太慢,大概是3.8 分钟/万步。而最简单的一个demo就需要100万步,算下来要6.3个小时。需要写一个项目采用xparl分布式计算。
七、使用xparl训练
请看AIStudio分享
- 在Ubuntu18.04操作系统上搭建训练环境
- 安装星际争霸训练环境SC2.4.10.zip
- 安装训练python工具smac
- 安装训练用游戏地图SMAC_Maps.zip
- 测试smac是否安装好
- 安装PaddlePaddle-linux-gpu-2.x版本
- 安装PARL2.x版本
- 安装visualdl
- 配置linux的环境变量
- 启动xparl集群
- 启动训练
- 启动visualdl工具监控训练过程
为什么要用GPU版本的PaddlePaddle?
QMIX算法属于CTDE这一类,因此它的集中学习部分代码使用GPU会大大提升它的训练速度。

- C = compute = CUDA or OpenCL
- G = graphics = DirectX or OpenGL
1c3s5z训练效果:


八、源码分享
采用xparl多CPU集群提升训练效率,改进后的源码在这里。
Baidu网盘效果游戏录像文件:提取码: vzag
九、进一步优化QMIX
在smac环境下使用QMIX算法来学习《星际争霸》微操。
- 重新架构单进程的QMIX算法,利用xparl的并行能力
- 创建actor执行游戏,采集训练数据
- 创建calc_q执行计算Q函数的工作,减轻主进程的计算压力