目录
可随意转载!
一、前言
Attention结构比Transformer框架出现更早。最早的关于Attention的论文来自于视觉领域,论文标题是:《Recurrent Models of Visual Attention》(2014),采用了RNN+Attention解决图片分类问题。
它很快被应用于机器翻译领域,论文是《Neural Machine Translation by Jointly Learning to Align and Translate》(2014),作者结合了Seq2Seq(2014)基础框架和Attention解决了长句翻译问题(RNN+Attention)。
2017年,论文《Attention is All You Need》正式宣布抛弃低效的RNN算法,发明了Transformer框架,开启了全新的Transformer时代,并很快蔓延到了其他机器学习领域。
注:论文中虽然用了新框架Transformer,但仍然沿用Seq2Seq论文中的基础框架:encoder-decoder。
Transformer和Attention的关系是什么呢?
Attention不等价于Self-Attention,在Self-Attention之前出现过Soft/Hard Attention, Global/Local Attention这些分支,Self-Attention更关注Q与K和自身Input之间的关系, Self-Attention也不止一种,我们只讨论Transformer框架中定义的Self-Attention。因此,结论可以概括为:Transformer仅仅是Seq2Seq的升级版本,主体流程还是堆叠Encoder-Decoder,而Self-Attention仅仅是Transformer框架的一部分。
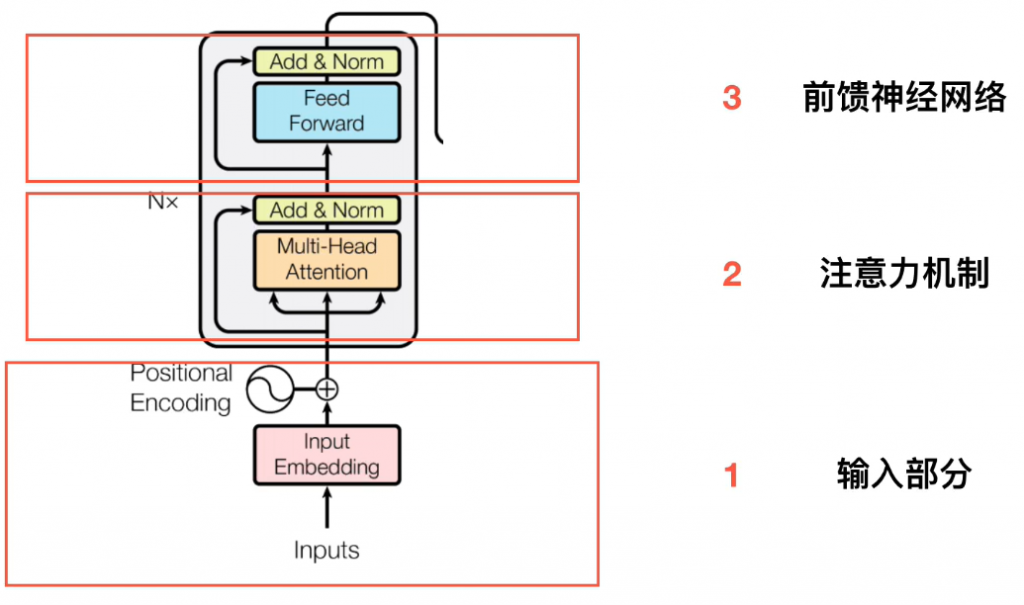
二、Transformer框架解析
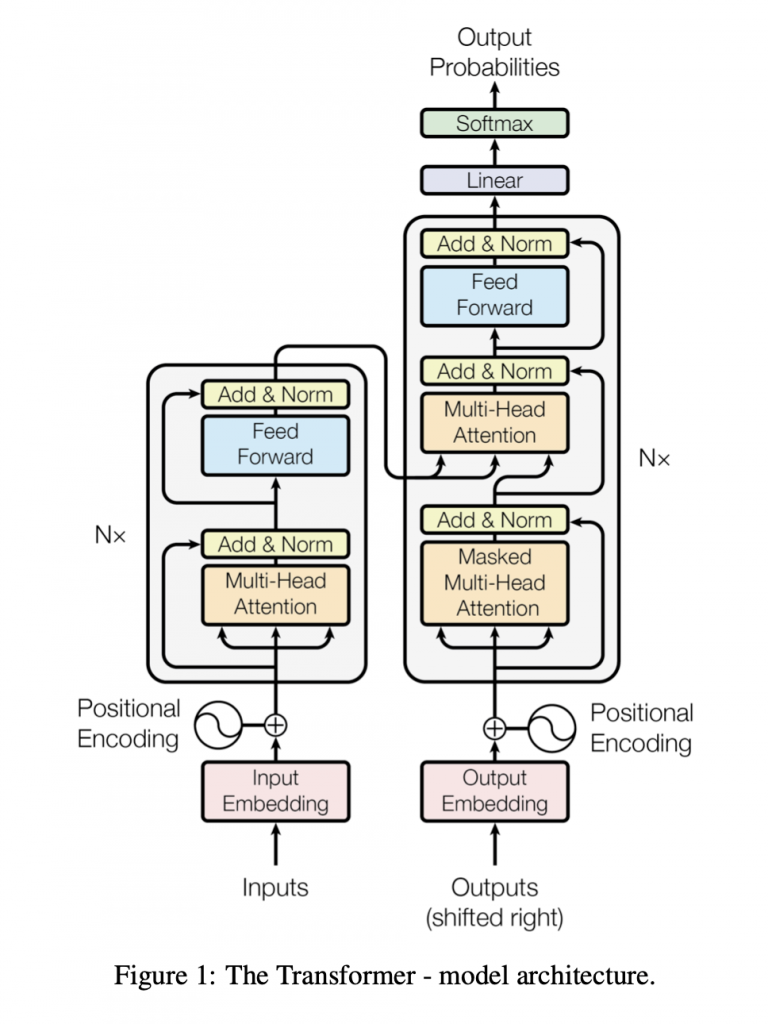
1.输入处理
首先看模型输入Inputs,它用到了Embedding算法(想了解算法请百度搜索Word2Vec)。很简单,Inputs(X)由下面数学公式表示:

2.理解自加权模型 Self-Attention
先看模型结构Multi-Head Attention(下右图):
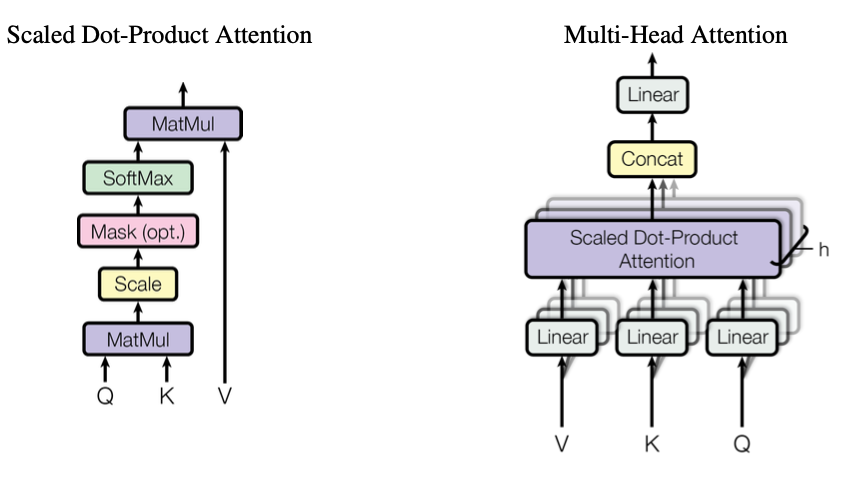
左边模型结构是右边模型结构的中间(紫色)那一部分,作者取名叫:Scaled Dot-Product Attention, 通常大家叫Self-Attention。
数学公式是:
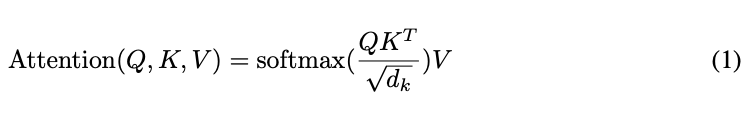
注意:QKT 被取名叫做注意力矩阵,表示词与词的逻辑距离(比如cat和dog,cat和sun,在日常认知中显然dog和cat逻辑距离更近。)
其中最重要的三个参数 Q K V 由下面数学公式计算:



其中,W矩阵由神经网络训练中自学习。举个程序猿都懂的例子:C++怎么来的?由C++编译器编译出来的,C++编译器怎么来的?由C++编写的……
3.Multi-Head Attention
Multi-Head Attention模型结构除掉上面的Self-Attention部分已经非常简单了,它引入了超参数h(本文中h=》head=3),简而意之,作者只是想多维度应用Self-Attention,把inputs映射到不同的高维度空间,再算术和。显然经过实验验证这样做比较好,初学者无需费力从理论上寻求解释。
4.Encoder&Decoder
总体看来Transformer仍然是Encoder-Decoder结构。
三、动态演示
更多细节请参考文章《The Illustrated Transformer》
5.1 处理第一个词
5.2 处理第二、三、四、五个词(结合之前的Output结果)
四、后记
五、附录
附1:注意力矩阵QKT 的两种算法
本文只介绍了第一种,但是这不是唯一的算法。
1. Dot Product
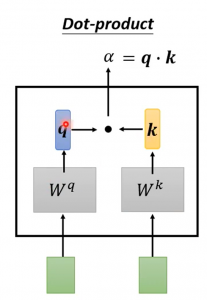
2. Additive

附2:Transformer网络结构分析
附3:LN(Layer Normal)取代BN(Batch Normal)
BN操作存在弊端,如果batch较小,不足以代表全部样本,效果差。