目录
可随意转载!Update2022.03.20
前言
“黑客帝国”等电影为我们打开了梦想世界,在全球产生了巨大商业影响力,因此拟真技术有着极大的商业价值。近几年GAN系列算法在im2im转换上取得了非常大的进步。像电影里的那种连续镜头是否可以用GAN算法生成出来呢?本文将给你一个满意的答案。
本篇论文是英伟达公司工程师ZeKun Hao和康奈尔大学学者共同的研究成果。人类向Metaverse(元宇宙)又前进了一步。下面是论文原文:《GANcraft: Unsupervised 3D Neural Rendering of Minecraft Worlds》
摘要
我们发明了GANcraft,一个无监督神经渲染算法,把Minecraft游戏世界(3D输入)渲染成拟真世界。具体方法是将语义块(semantic block)的游戏世界作为输入,每个块打上标签,比如污垢、草或水。将游戏世界表示为一个连续的体函数,并训练模型渲染成拟真世界(观察视角可控)。因为MineCraft游戏世界中缺乏和现实成对的数据(unpaired data),所以我们设计了一种基于伪GT(ground truth: 表示人工标记的正确数据)数据的对抗训练技术。这跟之前研究者依赖的成对数据(paired data)形成了鲜明的区别。除了相机轨迹外,GANcraft算法还允许用户控制场景语义和输出风格。实验表明,GANcraft算法在拟真MineCraft游戏世界上是有效的。
一、简介
im2im的算法(2D算法)可以让用户在Microsoft Paint中画草图然后转换成拟真的图片。但是3D场景的类似算法很难,它需要多年的专业知识、专业软件、资料库和大量时间。相比之下,MineCraft构造世界是如此简单和直观,甚至连孩子都能做到。如果我们能够先用MineCraft构建一个游戏世界,将其输入GANcraft算法获得一个具有高大的绿树、冰雪覆盖的山脉和蓝色的海洋的拟真世界,那该有多好? GANCraft算法可以做到MineCraft游戏世界–>拟真世界的自动转换。这个算法将有很多应用场景,例如:娱乐、教育、快速艺术原型制作等等。
在本文中我们提出了GANcraft算法,这是一种生成从语义标记的游戏世界出发到拟真世界的渲染算法。Minecraft是一个视频沙箱(sandbox)游戏中,用户可以在网格中放入块(block)而建筑一个游戏世界。Minecraft游戏提供了块(block)代表各种建筑材料,例如:草、土、水、沙、雪等等。每个块都有一个卡通化的纹理。我们把MineCraft游戏看作是一个3D构建工具。有些玩家甚至在游戏中建造了艾菲尔铁塔。所以MineCraft很适合作为我们GANcraft算法的媒介。本文专注在构建3D风景,就如之前im2im算法类似。
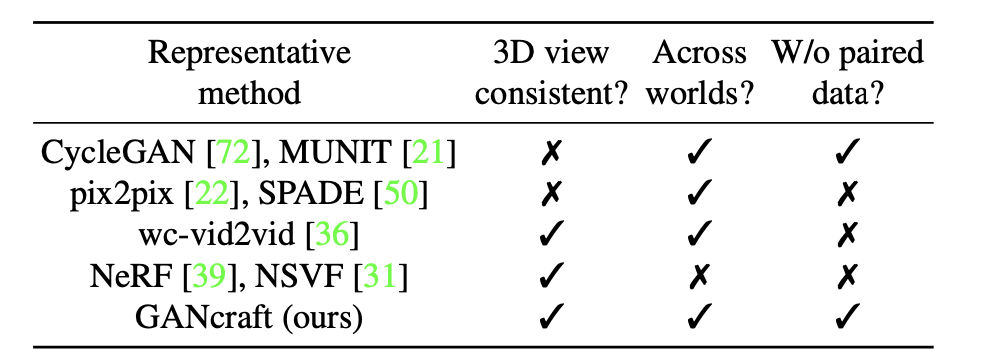
乍一看,从语义块创建3D真实场景似乎是一个翻译任务,将3D投影为2D分割映射,学术上属于im2im研究方向。但是顺着这个思路下去,会碰到几个难题。首先,获取虚拟世界和真实世界成对的训练数据(paired data)、分割标签的代价是极其高昂的。其次,之前的im2im模型不能生成连续场景,因为所有视频帧都是独立转换的。虽然vid2vid算法克服了连续场景问题,但它需要成对的训练数据(paired data)。即使是新视角合成算法,如NeRF、NSVF和NeRF-w,也需要场景的真实图像和相机参数,只适合于视频插值场景。因为没有这种成对数据,所以我们的目标(拟真MineCraft沙盒游戏)当前算法都是做不到的(如下表)。因此我们做了一些特别的算法调整,以适应之前的算法。比如在真实环境做分割而不是在MineCraft中。
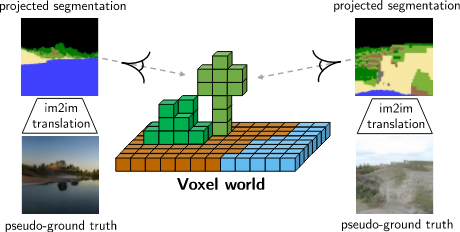
在缺乏GT数据的情况下,我们使用采样的相机视角伪GT数据(pseudo ground truths)来训练我们的框架。我们的框架使用了im2im转换的思路,并在3D视图合成的基础上改进工作,以产生拟真连续场景。虽然我们使用Minecraft演示我们的结果,我们的方法也适用于其他软件,如:voxels。我们选择MineCraft只是因为它更流行一些。
我们的主要贡献是:
- world2world(3D)的连续场景转换。
- 通过预训练生成伪GT图像做训练,不依赖成对数据(paired data)。
- 使用了GAN Loss的新的神经网络,能对场景的风格(style)进行定制。
二、相关工作
2.1 图片到图片的(im2im)转换
GAN已经可以做高保真的图像转换。比如从:分割地图到拟真图片。可以用监督学习(依赖成对数据)或者非监督学习(只依赖2个对应数据集)。监督学习类算法一般使用强损失函数(L1损失),或者使用感知+对抗损失函数(参考文章)。无监督学习类算法一般使用共享的隐空间(latent space) 假设(参考文章)或者使用循环一致损失函数(CycleGAN)。
本论文的问题属于无监督学习,因为没有成对数据。为了得到连续性场景,我们使用了伪数据,它们是从预训练的im2im数据中获得的。
2.2 伪GT数据

早期论文中大家都是用自监督学习或者从头训练来生成GT数据。最近伪GT数据生成已经被应用到适合无监督的领域,他们在源领域用深度学习模型获得目标领域的预测。并且把预测结果叫做伪GT(或者伪标签),最后在这些伪标签数据上做finetune深度学习模型。
本论文的问题中我们有MineCraft的分割地图数据,但是我们没有对应的真实世界数据。我们用了SPADE算法,输入游戏地图数据,输出伪GT数据,我们就可以生成成对数据。它们可以帮助我们在world2world转换中使用强力的L1、L2和感知损失函数,达到提升输出连续场景质量的目的。这个方法也被最近的几篇论文(StyleGAN)中被用作数据生成器来训练逆图像模型。
2.3 三维神经渲染
工业界已经有一些把传统图像处理管道优势(3D-aware projection)和神经网络进行结合输出连续场景的进展。通过引入可微分三维投影并使用三维或者二维的可训练层,最近的几种方法能够从二维 图像中对三维场景的几何形状和外观进行建模。一些方法成功地将神经渲染与对抗训练相结合,从而消除了训练图像必须在同一场景中同样姿势的限制。然而,问题的欠约束性质限制了这些方法在单个对象、合成数据或小规模简单场景中的应用。我们发现仅对抗性训练不足以在我们的环境中产生良好的结果。这是因为我们的输入场景更大更复杂,可用的训练数据高度多样化,并且游戏世界和真实图像之间的场景构成和相机位姿分布存在相当大的差距。
三、MineCraft中的神经渲染器
我们的目标是把一个用语义和标签块组成的MineCraft的地图渲染成一个可以从任意相机视角观察的连续的拟真场景。本论文关注在大范围场景,而不是单个物体或者小型舞台。在所有场景中,我们使用了大小为512×512块长宽,256块高。如果每块1立方米,那么场景大小为262144平方米(相当于32个足球场的面积)。与此同时,我们的模型需要学习比单个块更精细的细节,比如树叶、花和草,这些都是无监督的。由于块和标签都在地图中定义好了,因此要把这两块数据也输入到算法中。我们先讨论怎么用伪GT数据来克服算法对成对数据的依赖,然后我们展示稀疏的基于块的神经渲染。
3.1 生成伪GT数据
最直接的训练神经渲染模型是利用已知相机位姿的GT图。用最简单的L2重建损失就可以了。然而,我们的任务(从MineCraft中生成拟真场景)的GT图是不可能有的。
另一种选择是用非监督的方式,也不依赖成对数据类似:CycleGAN或者MUNIT。将会使用对抗损失函数和正则化函数将游戏世界转换到拟真世界。但是这种方式的效果不好。因为MineCraft世界和真实世界的巨大差异以及标签分布的变化(label distribution shift)。为了弥补这个巨大差异,我们使用了动态生成的伪GT数据。对于每个训练迭代,我们从上半球随机采样相机姿势,并随机选择焦距。然后,我们将语义块的标签投影到相机视图,以获得二维语义分割Mask。分割Mask以及随机采样的style被输入到预训练的SPADE网络中,以获得与相机视图具有相同语义布局的照片级真实感伪GT图像(这就是伪成对数据的来源)。我们能够将重建损失(如L2)和感知损失同时应用到伪GT数据和对应的MineCraft中的相机位姿的渲染输出,以及对抗损失。这显著改善了效果。
SPADE算法在大规模数据集上训练的可推广性,加上其生成拟真的能力,有助于减少领域差距和标签分布不匹配。虽然这提供了超视觉能力,但是它并不完美。Minecraft的块状特点会产生失真的带棱角的几何特征。某些相机姿势和style组合也可能生成有瑕疵的图像。因此,我们必须谨慎地平衡重建和对抗性损失,以确保神经渲染的成功训练。
3.2稀疏的基于块的神经渲染
这里论述的是NeRF领域的内容,使用普通图片生成3D图片,它用了算法Neural Sparse Voxel Fields(NSVF),因为它比NeRF算法快。
天空是写实风景场景中不可或缺的一部分。因为用一层块表示天空效率太低了。在 GANcraft 中,我们假设天空无限远(无视差),它的外观仅取决于观看方向。略
把上述NeRF的东西转换为二维的特征图。略
NeRF是另一个研究领域,感兴趣可以参考:
混合神经渲染架构
基线
- MUNIT算法: 无监督不需要成对数据,而且可支持多模转换。
- SPADE算法:需要监督和成对数据。
- wc-vid2vid算法:可输出连续场景。
- NSVF-W算法: 它结合了NSVF算法和NeRF-W算法。我们用预训练的SPADE算法模型生成GT图输入给它。
实现细节
我们输出的尺寸是256×256像素,每个模型用的显卡配置是:英伟达V100(32G显存)。batch size是8,相机的配置是24点采样,25万轮训练花了4天时间。上面所有的baseline都是一样的硬件配置。