目录
禁止转载,侵权必究!Update2022.04.15
前言
PARL 是由百度开发的、高性能、灵活的强化学习(RL)框架。
微软AirSim环境是基于Unreal高性能游戏引擎开发的,面向四轴无人机和无人驾驶汽车的虚拟学习环境。
AirSim目前在GitHub上的star数高达12.9k,是微软公司目前最火的人工智能项目。
目前AirSim环境还不能运行PARL程序,本文的目标是在AirSim环境中运行基于PARL的强化学习程序。
一、环境配置
- win10操作系统
- Anaconda Navigator
- Python3.7+
- PaddlePaddle2.x
- PARL2.x
- 宽带网络+加速器
- 内存16G或更多
- 显卡NVIDIA RTX3060Ti以上
注册账号
- 注册微软统一账号:Win10系统菜单中找到windows 商店注册即可。
- 注册Unreal账号:打开游戏引擎官网https://www.unrealengine.com/zh-CN 注册账号,并打通github.com认证授权(二次开发Unreal代码需要用到)。
下载软件
- 下载Visual Studio Community 2019
- 使用C++的桌面开发
- 安装组件:Window 10 SDK(10.0.18362.0)
- 下载Epic Game Launcher并安装4.26以上版本的“虚幻引擎”
- 重启Epic Game Launcher并关联项目文件
- 下载AirSim源代码:git clone https://github.com/Microsoft/AirSim.git
本地编译AirSim源代码(Windows环境)
- 打开Developer Command Prompt for VS 2019,在项目根目录下输入命令:build.cmd
- 检查插件目录:$ProjectRoot\Unreal\Plugins\ 看插件是否生成。
测试AirSim环境
- 打开Developer Command Prompt for VS 2019,在$ProjectRoot\Unreal\Environments\Blocks目录下输入命令:update_from_git.bat
- 弹出窗口点击确定,关联当前引擎
- 进入目录双击Blocks.sln, VS2019自动启动。
- 编译选项设置为:Development_Editor + Win64
- 点击菜单“调试”–>“开始调试”,虚幻编辑器启动,看一遍教程
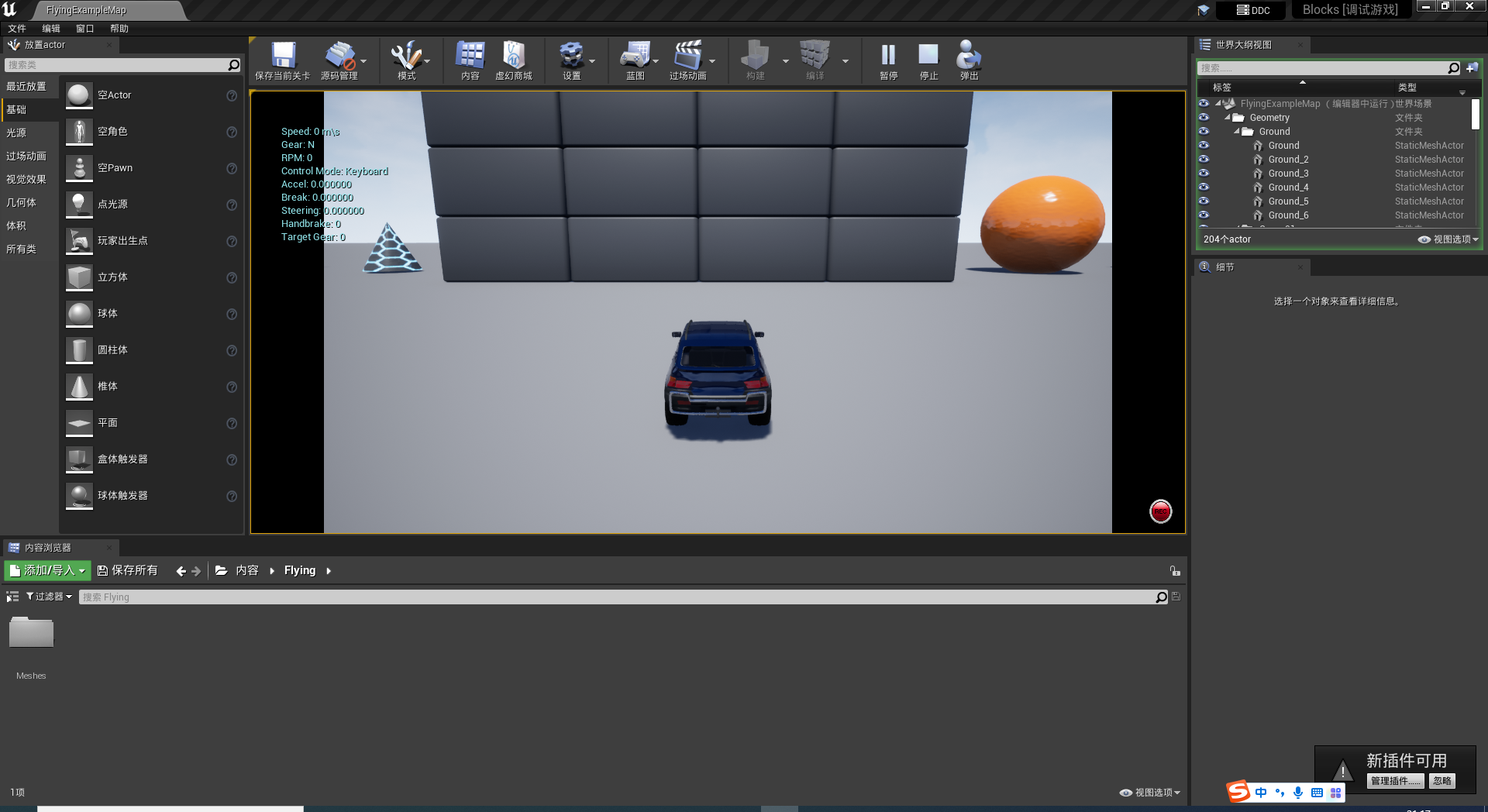
- 点击“运行”,点击确定,出现入下图小车,AirSim环境安装完毕。
下载与安装示例
- 打开Epic Game Launcher,选中Sample,往下滑,找到Landscape Mountains示例
- 选择一个本地文件夹,点击Create,忽略引擎版本号警告,下载(大约1.5G)。
- 进入本机文件夹,打开文件LandscapeMountains.uproject,选择用当前Unreal版本打开
- File –> New C++ Class –> Next –> Create Class 因为Unreal必须要求有一个新类才会触发编译并打开VS 2019 项目LandscapeMountains.sln
- 拷贝第三步编译的Unreal\Plugins进入下载的LandscapeMountains本地文件夹
- 关闭所有相关项目窗口,重新打开文件LandscapeMountains.uproject,提示AirSim需要重新构建,点击确定
- 用文本编辑器编辑文件LandscapeMountains.uproject,如下修改:
{
"FileVersion": 3,
"EngineAssociation": "4.27",
"Category": "Samples",
"Description": "",
"Modules": [
{
"Name": "LandscapeMountains",
"Type": "Runtime",
"LoadingPhase": "Default",
"AdditionalDependencies": [
"AirSim"
]
}
],
"TargetPlatforms": [
"MacNoEditor",
"WindowsNoEditor"
],
"Plugins": [
{
"Name": "AirSim",
"Enabled": true
}
],
"EpicSampleNameHash": "1226740271"
}- 用文本编辑器编辑Config\DefaultGame.ini,如下修改
[/Script/EngineSettings.GeneralProjectSettings]
Description=
Description=A showcase of the Landscape and foliage tools, featuring a heightmap and layers imported from World Machine..
ProjectID=2F9E755244BE3FD42C78DA99BE9702D5
ProjectName=Landscape Mountains Showcase
+MapsToCook=(FilePath="/AirSim/AirSimAssets")- 保存并关闭所有相关窗口后,右键文件LandscapeMountains.uproject,点击Generate Visual Studio Project Files
- 双击LandscapeMountains.sln,打开VS 2019,编译选项置为”DebugGame Editor”和”Win64″,点击开始调试(F5)。程序会自动打开Unreal编辑器
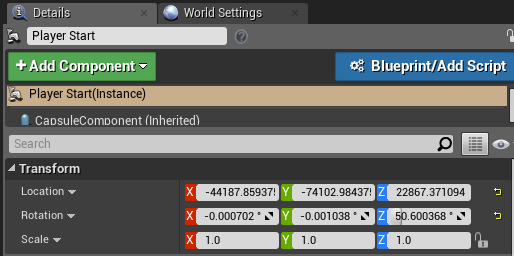
- 在右上找到“Player Start”对象并单击,右下角会显示详细,如下图坐标设置游戏Agent的开始位置(注意:这是四轴飞行器的位置):
- 可选:点击菜单“窗口” –> 世界场景设置 在右下角“详细”页签旁边打开World Settings。
- 在World Settings里面选中的“游戏模式”–> “游戏模式重载”滚动并选中选项:“AirSimGameMode”
- 可选:如果你的电脑性能不行,可以在“编辑”–>“编辑器偏好设置”,搜索“CPU”,勾选上:处于背景时占用较少CPU。
- 菜单中点击保存所有。
- 点击Play,示例项目配置完毕。
二、使用程序控制汽车
- 配置好Anaconda环境
- pip安装依赖包
# 安装Unreal和python之间的通讯协议
pip install msgpack-rpc-python
# 安装airsim的python库
pip install airsim- 启动VS Code,打开文件夹PythonClient\car\
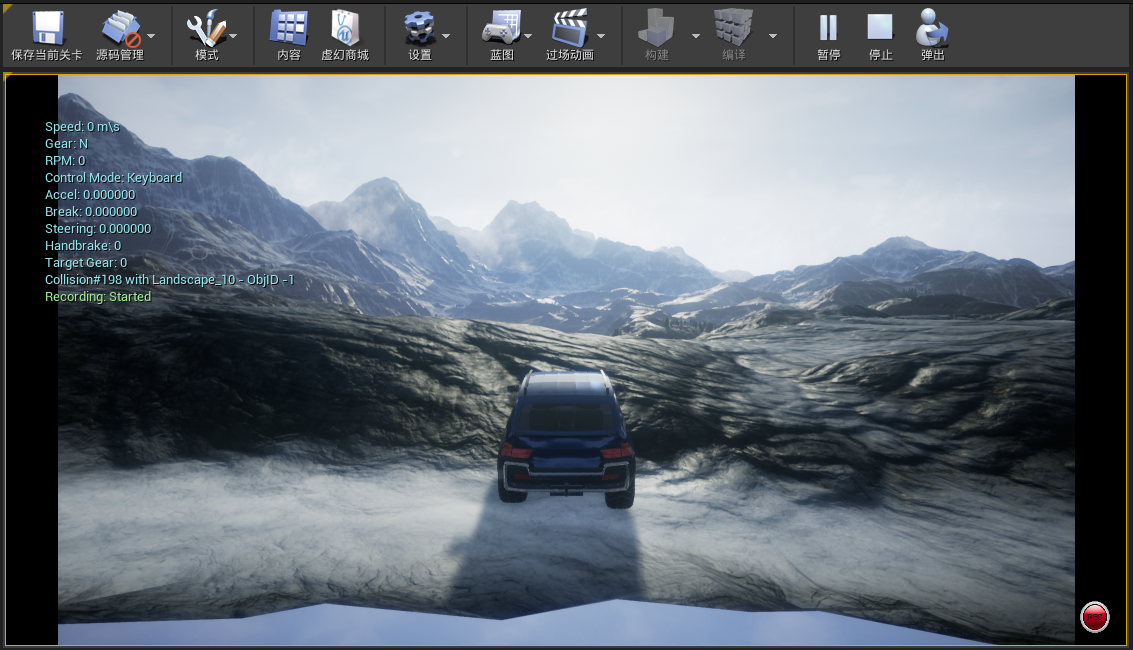
- 运行hello_car.py,如下:
三、使用飞桨PARL自动驾驶汽车
Github下载AirSim预编译的windows版本的训练环境(地图):

AirSim_Paddle
│ agent.py
│ model.py
│ replay_memory.py
│ setup_path.py
│ train.py
│
└─airgym
│ __init__.py
│
└─envs
airsim_env.py
car_env.py
drone_env.py
__init__.py3.1 AirSim环境相关类:
- setup_path.py AirSim环境设置
- airgym目录
__init__.pypython包配置- envs目录
- airsim_env.py 基础环境配置
- car_env.py 汽车训练环境配置
__init__.pypython包配置
3.2 DQN算法相关类:
- train.py 主程序,训练DQN模型
- model.py 飞桨PARL三件套之一
- agent.py 飞桨PARL三件套之一
- replay_memory DQN系列算法的“记忆回放”
3.3 代码逻辑
- 初始化AirSim_Gym 游戏环境
- 初始化飞桨PARL库的DQN算法
- 预热“记忆回放”
- 循环开始触发动作,训练自动驾驶
- 定期评估训练效果
- 保存训练结果。
...
while True:
step += 1
# 获取记忆回放中的4帧
context = rpm.recent_obs()
# 把当前动作返回帧加进去
context.append(obs)
# 数组增加一维
context = np.stack(context, axis=0)
# 选择一个动作,e-greedy算法
action = agent.sample(context)
# 触发动作
next_obs, reward, isOver, _ = env.step(action)
# 回写记忆回放
rpm.append(Experience(obs, action, reward, isOver))
# train model
if (len(rpm) > MEMORY_WARMUP_SIZE) and (step % LEARN_FREQ == 0):
# s,a,r,s',done
(batch_all_obs, batch_action, batch_reward, batch_done) = rpm.sample_batch(BATCH_SIZE)
# 抽帧
batch_obs = batch_all_obs[:, :CONTEXT_LEN, :, :]
batch_next_obs = batch_all_obs[:, 1:, :, :]
# 把抽出的帧放入learn方法中学习
train_loss = agent.learn(batch_obs, batch_action, batch_reward,
batch_next_obs, batch_done)
loss_lst.append(float(train_loss))
print("loss" + str(train_loss))
total_reward += reward
obs = next_obs
if isOver:
break
return total_reward, step, np.mean(loss_lst)