目录
可随意转载。Update2022.05.29
前言
Transformer的强大能力不仅仅在NLP领域中一统江湖,甚至在CV领域也大放异彩(ViT),就在2022年5月,DeepMind公司发表论文,提出了智能体 – Gato(一种能够完成600多种RL任务的智能体),还是用的Transformer。
一、背景知识
首先,Transformer在原论文中自称 – “Architecture”,因为它不是单一的算法,而是结合了前人提出的几种算法思想(Seq2Seq,Attention,Embedding,Positional Encoding, Multi-Head)并发扬光大。为了了解Transformer,我把它拆开以便于读者理解:
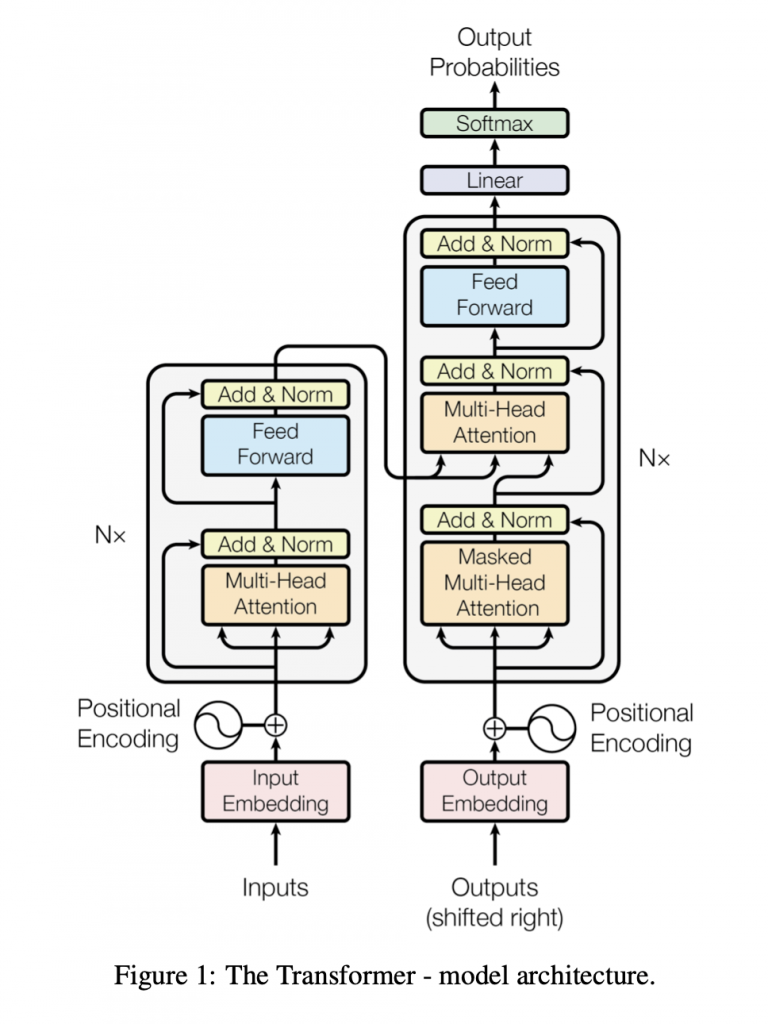
1.1 理解Embedding
数学原理:
函数 y=f(x),其中x∈X,y∈Y。当函数f满足以下两个约束,这种就叫embedding函数:
- injective:每个yi有且仅有一个xi
- structure-preserving: 如果xi < xj 那么yi < yj
1.2 one-hot VS embedding:
假如《哈姆雷特》中包含3000个不同的英文单词且字数为1百万字。我们用one-hot方式将它存储在计算机中,那么我们需要的储存空间为:1,000,000 X 3,000 = 30亿 ,这个存储空间显然太庞大了。
还有一个问题:小说中的单词man和 king是有现实关系的(king是男人),但在one-hot表示的计算机存储中它们是完全没有关系的,这并不合理。
那我们能不能压缩并更合理的在计算机中存储《哈姆雷特》呢?
当然可以,方法就是embedding。示意如下:
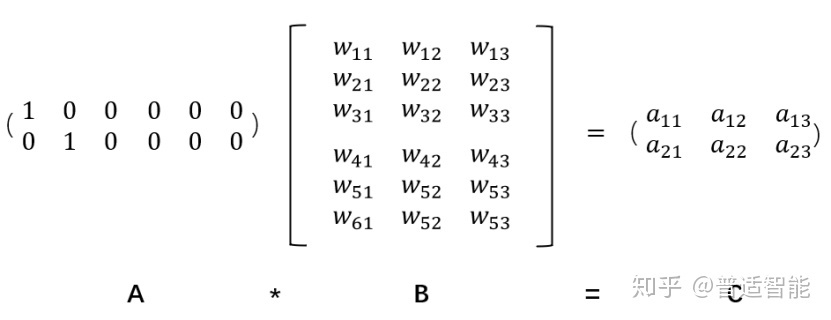
embedding相比one-hot优点如下:
- 低维度,稠密 占用空间少,计算效率高
- w矩阵可学习 可以用神经网络学习w参数
还有一个重要的优点:我们可以对同一个源数据(比如NLP中的英语)做多种不同处理后的结果(embedding)做向量加法(因为embedding的数学原理保证了:向量加法不改变数据的性质),这在数值处理领域是非常优秀的特点!在后面介绍Transformer时就能体会到。
1.3 位置编码
计算机并不能理解位置这个概念,比如一句话输入到Transformer矩阵中,就不再包含原始的词序信息,比如一张图片输入到CNN中,CNN需要用卷积核来保留原始图片的位置信息,Transformer使用Positional Encoding来保留源数据的位置信息。
1.4 多头注意力
将输入的Q、K、V向量做Self-Attention运算并相加。目地是为了提取原始数据空间映射到不同空间视角下的特征。详情见Paddle代码。
1.5 层归一化LayNorm
独立同分布(i.i.d.)是非常优秀的数据特性,比如随机抛掷硬币。但是机器翻译中的句子并不满足独立同分布,因为句子上下文是有语义关系的。虽然源数据不满足独立同分布,但是我们可以通过归一化的方法,让过程数据(或者源数据)的均值和方差相同,减少神经网络训练中的ICS问题。常见的归一化方法有:batch norm,layer norm。
二、Paddle库的Transformer实现
看完上面的原理部分,你可能已经晕了。但是不要紧,在Paddle库中一切都非常简单。
2.1 Embedding
类定义 (声明) :
# num_embeddings 输入空间总维度,比如上面的3000
# embedding_dim 输出数组的维度
class paddle.nn.Embedding ( num_embeddings, embedding_dim, padding_idx=None, sparse=False, weight_attr=None, name=None ) 调用forward:
x_data = np.arange(3, 6).reshape((3, 1)).astype(np.int64)
x = paddle.to_tensor(x_data, stop_gradient=False)
embedding = paddle.nn.Embedding(10, 3, sparse=True)
embedding.weight.set_value(w0)
out=embedding(x)
2.2 MultiHeadAttention
类定义 (声明) :
# embed_dim Q矩阵维度,输入和输出的维度
# num_heads 原论文默认是3
# kdim K矩阵维度
# vdim V矩阵维度
class paddle.nn.MultiHeadAttention ( embed_dim, num_heads, dropout=0.0, kdim=None, vdim=None, need_weights=False, weight_attr=None, bias_attr=None )调用forward:
query = paddle.rand((2, 4, 128))
attn_mask = paddle.rand((2, 2, 4, 4))
multi_head_attn = MultiHeadAttention(128, 2)
output = multi_head_attn(query, None, None, attn_mask=attn_mask) # [2, 4, 128]2.3 Transformer
2.3.1 TransformerEncoderLayer
类定义(声明):
# d_model 输入输出维度
# nhead 原论文默认是3
# dim_feedforward forward网络隐藏层维度
class paddle.nn.TransformerEncoderLayer ( d_model, nhead, dim_feedforward, dropout=0.1, activation='relu', attn_dropout=None, act_dropout=None, normalize_before=False, weight_attr=None, bias_attr=None ) 调用forward:
# 下面第一行三个参数为上面的定义参数
# 下面第二行两个参数为调用传递参数
encoder_layer = TransformerEncoderLayer(128, 2, 512)
enc_output = encoder_layer(enc_input, attn_mask) # [2, 4, 128]
2.3.2 TransformerEncoder
类定义(声明):
# encoder_layer 上面定义的layer层
# num_layers 叠多少层,原论文默认是6
class paddle.nn.TransformerEncoder ( encoder_layer, num_layers, norm=None ) 调用forward:
# 下面最后一行传递了2个参数
encoder_layer = TransformerEncoderLayer(128, 2, 512)
encoder = TransformerEncoder(encoder_layer, 2)
enc_output = encoder(enc_input, attn_mask) # [2, 4, 128]
2.3.2 TransformerDecoder
同理
2.3.1 TransformerDecoderLayer
同理
2.4 LayerNorm
三、Paddle类声明和forward解析
仔细的同学会发现上节代码会有奇怪,为什么有声明类和调用类两个东西。其实这是python的语言特性 – “__call__”函数的典型用法。我们看看Paddle内部的实现(paddle/fluid/dygraph/layers.py — Layer类):
def _dygraph_call_func(self, *inputs, **kwargs):
...
outputs = self.forward(*inputs, **kwargs)
...
return outputs
def __call__(self, *inputs, **kwargs):
return self._dygraph_call_func(*inputs, **kwargs)这里用到了python的__call__函数。简而言之,因为上面的所有类都是Layer类的子类,因此以类名调用函数的时候,本质是调用了子类中的forward方法。