目录
可随意转载!Update2022.07.24
前言
EditGAN论文的理论部分看不懂,需要更细化了解semantic branch部分的由来还是要看这篇论文:
《Semantic Segmentation with Generative Models:
Semi-Supervised Learning and Strong Out-of-Domain Generalization》
一、方法原理
传统的语义分割方法是基于如下公式:
f: x –> y x∈X(图片)y∈Y(像素语义标签)
目标是最大化条件概率 p(y|x),问题是计算这个条件概率需要大量的成对数据。因此本论文提出了替代的模型:
用GAN生成模型来最大化联合概率p(x, y)。我们知道GAN是从噪声z中开始生成图片,生成公式可表示为:
G(z) : Z –> (X, Y)
意思是G网络可以把噪声Z空间训练成图片空间X和语义分割空间Y。对于任何噪声z,它的x和y都是独立分布的(意思是:任意x,y都只跟z有关系,彼此没有关系)。
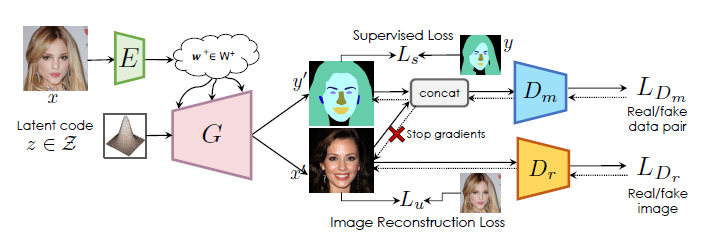
给定输入图片x* 我们可以用encoder把z* + x*通过G生成y* 。我们在实际编码中是这么做的:我们没有在Z空间(高斯分布)中搞事情,我们直接把x*通过encoder转换到StyleGAN2的W+空间再通过G生成y*,如下图:
二、理论推导
1.半监督训练
直觉上,一个算法如果能生成相片级的图片,那么它当然也可以生成像素级的语义分割图。理论上如何解释呢?
作者认为GAN算法实质是一种Z空间上的神经渲染(Neural Renderer)算法(因为假定Z分布包含了训练数据集的完整encode和describe信息),给定基于Z的模型和输入x得到相片级图片,这不就是渲染吗!由此作者推论:假如GAN能生成相片级图片,就一定能生成语义分割图。
于是作者给StyleGAN2网络增加了一个小分支。训练这个小分支只需要很少的人工标记数据,因为GAN网络可以预先训练好。这就是作者提出的高效半监督算法(efficient semi-supervised)。更进一步,联合了图片+语义分割图的GAN具备在线语义分割图finetune能力。
2.泛化能力
因为x,y是独立分布,所以作者认为联合概率p(x, y)比条件概率p(y|x)要有更好的泛化能力。
这里作者主要是解释上节提出的一些结论的原因。
3.生成网络
这里讲的是作者对StyleGAN2网络的改造点。

4. 判别网络
SemanticGAN算法有2个判别器:
Dr X–>R(其中r代表真实图片或者生成图片)
Dm (X,Y)–>R 最小化真实图片和语义标签之间的loss,让它们“对齐”。这个判别器抄的论文pix2pixHD的。
5.Encoder和W+空间
之前的论文证明了在W+空间比Z空间和W空间都更好,因此我们把生成网络G(z)直接转换为生成G(w+)。
我们在推理阶段直接用一个Encoder把图片x直接映射成latent w+
E : X –> W+
这个FPNEncoder网络结构是从论文pSp整理修改而来。
pSp 借鉴了FPN(特征金字塔)结构,来自另一篇论文《Feature pyramid networks for object detection》
6.训练
论文使用了2个数据集,未标签数据集 Du = { x1,… xn } ; 小数据集Dl= { (x1,y1), … (xk, yk) }
我们分两阶段训练:先训练生成器和判别器,然后再训练Encoder。
训练Encoder的时候,G网络参数不动,它的损失函数定义如下:
LE = LS + Lu
其中LS 是监督学习损失函数,公式如下:
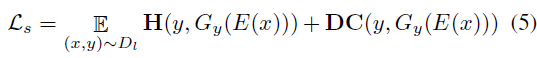
Lu 是非监督学习损失函数,公式如下:
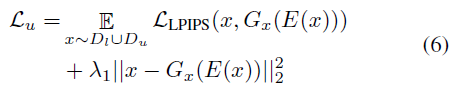
7. 推理
推导阶段,我们的输入是x*,目标是y* 。我们的方法是用Encoder直接把x* 嵌入到W+空间,因为X和Y是独立分布,所以要先找逆推函数w*+ :
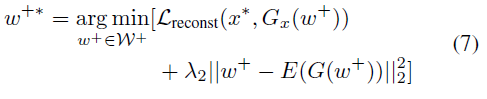
第一项Lreconst 项是为了提升图片质量,公式如下:
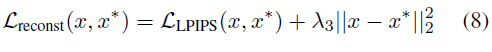
第二项是来自论文IDInvert,因为x* 是out-of-domain数据,通过G和E网络逆推得到的w+* 可能偏离p(w+ ) 数据分布。而 p(w+ ) 是通过StyleGAN2网络由p(z)计算出来的,它很难被直接计算,所以这里最小化它和w+ 的差值就是保证它尽量贴近w+ 分布。
8. 损失函数
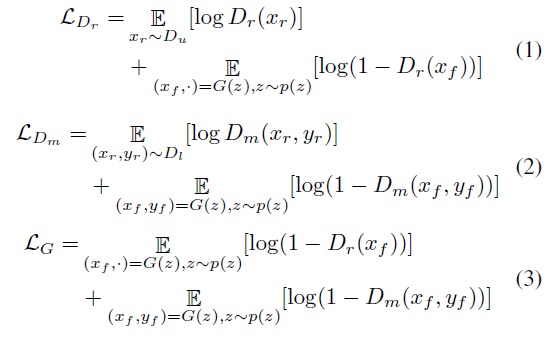
为了让生成的语义切割图“对齐”生成图片,因此把语义分支的loss反向传播停了,不让它影响G网络。
三、代码实操
1. 数据集CelebAMask-HQ
数据集需要做一些预处理,最后划分出来train,test,val加上标签总共6个数据目录。
2. 调整vscode设置
# launch.json
# 注意env配置了依赖的PYTHON modules
{
"version": "0.2.0",
"configurations": [
{
...
"env": {"PYTHONPATH": "${workspaceFolder}/utils/:${workspaceFolder}/dataloader/"},
"justMyCode": true,
"args": [
"--size", "512",
"--output", "inception.pkl",
"--dataset_name", "celeba-mask",
"/home/ouyang/Downloads/datasets/CelebAMask-HQ/semanticGAN_dataset"
]
}
]
}# settings.json
# 配置了代码提示
{
"python.analysis.extraPaths": ["${workspaceFolder}/utils/","${workspaceFolder}/dataloader/"]
}3. prepare_inception.py
# 第一次运行
Downloading: "https://download.pytorch.org/models/inception_v3_google-0cc3c7bd.pth" to /home/ouyang/.cache/torch/hub/checkpoints/inception_v3_google-0cc3c7bd.pth# log
extracted 29500 features
Calculating inception metrics...
Training data from dataloader has IS of 3.72096 +/- 0.20387
Calculating means and covariances...最后输出文件:inception.pkl
4. train_seg_gan.py
80万轮,跟StyleGAN一样了。
5. 训练encoder
train_enc.py