目录
可以随意转载!Update2022.07.29
一、SOLO算法
来自论文《SOLO: Segmenting Objects by Locations》
一种单阶段的实例分割算法(请自行查阅实例分割、语义分割和全景分割的区别)。
根据作者的分析在COCO数据集中,98.3%的图片物体中心点举例超过了30个像素,剩下的1.7%中的40.5%的图片中物体尺寸相差1.5倍,因此作者想出了用instance category(物体的中心点和物体的大小)来解决实例分割问题,因此算法取名叫SOLO。具体的做法是找物体的中心位置,然后把像素分类到各个中心类型上,把位置预测任务转换成了分类任务,因此无需其他算法的二阶段处理。
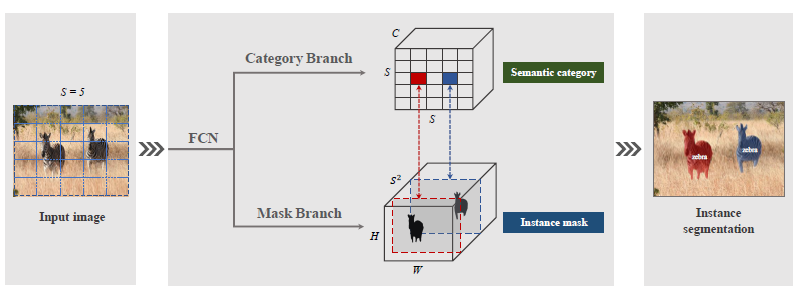
实例Mask
卷积具备空间不变形,一个物体无论出现在图片的什么位置,用卷积网络都可以轻易的找出来。但是对于实例检测来说,这就非常不好,我们不仅仅要知道是什么物体还需要知道它在图片中的精确位置,因此借鉴了CoordConv的做法,我们把Mask分支设计成:
原始输入尺寸:H x W x S2 = H x W x D
增加位置属性(x,y)后的尺寸是: H x W x (D +2)
损失函数
论文采用了Dice loss作为损失函数中的一部分,解决了正负样本不均衡的问题。
总结
SOLO这篇论文在实例分割领域具有领先的独创性。
二、SOLOv2算法
三点提升
- 提出了动态Mask提升了训练速度
- 提升了Mask的分辨率
- 提出了更高效的Matrix NMS方法
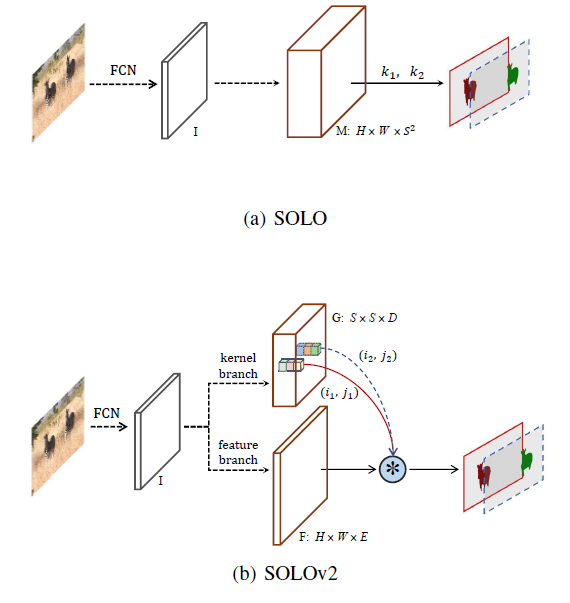
因为图片中的物体通常是稀疏的,在SOLOV1中我们用S2 个channels全部输出,十分占内存,而在改进版Decoupled SOLO中,通过x,y方向解耦,变成了2S的channels。
在SOLOV2中作者进一步优化,变成了D个channels,具体做法如上图,把category分支网络分成了2路:kernel branch(G)和feature branch(F)。