目录
可随意转载!Update2023.12.02
前言
Diffusion作为GAN的后起之秀,以简洁的数学推导,强大的文/图生图的能力,把GAN赶下了神坛,而Stable Diffusion作为其中开源的版本在社区广泛流传。其中Stable Diffusion WebUI更是让广大非科技工作者也体验到了二次元涩图的乐趣。
一、扩散模型发展历程
1.1 2020年论文《Denoising Diffusion Probabilistic Models》
UC伯克利的大神Jonathan Ho(后来加入了Google)构建了一个离散步骤的马尔可夫链,不断加入随机噪声直至其成为无法辨识的纯噪声为止的前向过程。这个过程对应着分子热动力学里的扩散过程。而模型学习的则是如何从噪声分布里出发,逐渐去除噪声将图片还原至原始的数据分布中。如下图所示:

经过推导从时间步0到任意时间步t的扩散(diffusion)过程公式如下:
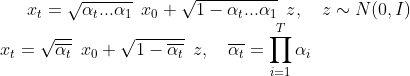
因为XT 是符合正态分布的噪声图,所以参数取值因满足下面条件:
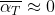
从上面公式可以看出扩散(diffusion)就是:从x0开始加连乘噪声z(标准正态分布),很容易理解。

去噪(denoise)过程理论上只需要把上面公式做简单转换即可,但是实验结果表明直接从xt去噪到x0生成图片太模糊,实际上去噪过程是一步步进行的,也就是从xT,xT-1, xt, xt-1,x0 分多步来做的。去噪(denoising)公式如下:
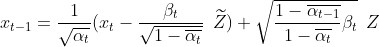
xt-1跟xt与Z飘的关系,其中 xt 是已知噪声图,Z飘是通过Unet神经网络计算,Z是标准正态分布,α、β都是常量
从上面公式可以看出去噪(denoising)就是:用Xt减去扩散过程加的噪声Z飘,重复迭代到X0。另外加了扰动z(标准正态分布)帮助神经网络做梯度下降,很容易理解。

1.2 2021年论文《Diffusion Models Beat GANs on Image Synthesis》
微软旗下的OpenAI也不甘示弱,通过扎实的理论和丰富的消融实验论证了扩散模型优于GAN系列模型。受到GAN算法的启发,首次引入classifier,通过权重控制在生成“威尔士柯基狗”例子上取得了很好的效果。

它的贡献是首次提出了分类(classifier),实现了用分类方法控制扩散模型输出。
1.3 文/图生图
2021年论文《More Control for Free! Image Synthesis with Semantic Diffusion Guidance》和论文《DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation》等,引入了”文生图”,突破了GAN的局限性(文生图是out domain,GAN+CLIP的效果比较差,比如用手遮住一部分脸,GAN就很难生成那只手),扩散模型这方面明显强过GAN系列模型,大大提升了这个科技领域的上限。


这篇文章的意义是论证了扩展模型强于GANs,此文之后学术界再无GANs。
1.4 Classifier-Free 引导的文/图生图
2022年大神Jonathan Ho入职google后发表论文《Classifier-Free Diffusion Guidance》(简称CFG)提出不管是引入classifier或者用文字、图片等形式去引导扩散模型,都需要给扩散模型增加额外的网络,不利于扩散模型做得更大。Classifier-Free模型的好处是不需要训练额外的Classifier网络,而且对原始的无条件扩散网络改动极小,只需要在训练代码中增加随机dropout条件,在sampling代码中混合条件和无条件的score estimates。
这篇论文非常重要。这条路线诞生了三个著名的扩散模型:Google的Imagen,OpenAI的GLIDE模型,开源的Stable Diffusion。
OpenA动用大量算力做出了产品GLIDE。使用自家的CLIP来替代外部模型的classifier,直接输入扩散模型做训练。
Google还以颜色,做出了Imagen。使用了T5系列的文本编码,作为控制条件直接输入扩散模型做训练。使用了cross-attention关联文本编码和图片编码。
开源社区不甘示弱,研发出了Stable Diffusion,把图片缩小48倍,在latent space中实现了更节约和高效的扩展算法,同时使用了openClip。在这个开源模型的基础上,还出现了更多算法:
- 基于SD的微调算法HyperNetwork劫持CrossAttention插入Style
- 从大语言模型引入的LoRA算法修改CrossAttention权重,实现SD模型特性化微调
SD中的重要步骤VAE处理图片域到latent space转换,研究者发现SD的细节(例如人脸)恢复存在问题。2023年11月,openAI承认是它训练的VAE预训练模型导致的这些问题,并提出了新的VAE模型。
1.5 能指定人/物体的生成算法DreamBooth
2022年的谷歌论文《DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation》提出了定义一个概念/物体X,通过微调让扩散模型理解X并在生成的时候可以根据提示词+种类词生成对应的X’。
dreambooth算法的根本问题是需要对每个人/物体做训练,因此无法大规模应用。
1.6 控制生成模型ControlNet
ControlNet来自论文《Adding Conditional Control to Text-to-Image Diffusion Models》,通过小数据、小算力的训练就可以给LDM增加控制模型(注意:它是一系列针对不同用途的模型,不是算法),在执行DDIM生成的时候,可以做到条件控制。例如:pose,canny,inpaint等等。最新版本是V1.1。
它的创新点是使用了zero inited layer,使得可以不动预训练模型,复制一份原模型部分网络结构做旁路训练,结合预训练模型和旁路模型实现生成控制。
1.7 GLIGEN算法
这个算法来自微软的实习生,主要作用是可以结合开放集合的定位算法,实现对图片中的某一个位置的替换。它的代码思路不错,有很好的借鉴价值。
1.8 T2I-Adapter算法
作者认为sd的生成能力没有问题,但是控制能力有问题,所以训练若干个adapter来做控制。
https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/adapter
1.9 Custom Diffusion
来自Adobe公司的论文《Multi-Concept Customization of Text-to-Image Diffusion》,又名custom diffusion,代码地址:Custom Diffusion。它的性能优于dreambooth和textual Inversion
此项目已经被diffusers实现,文档路径分别是:
https://huggingface.co/docs/diffusers/main/en/training/custom_diffusion
- 用脚本去网址https://knn.laion.ai/knn-service从laion_400m数据集中搜索并下载了200张对应的类别(class)用来做正则化。
2. RTX3090需要开xformers,否则会内存溢出。关联pytorth 1.13.1+cu117只能用conda安装,因为pip目前只有cu118和cu121两个版本。每个物体都需要训练时间3-4分钟。
python train_custom_diffusion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--class_data_dir=./real_reg/samples_cat/ \
--with_prior_preservation --real_prior --prior_loss_weight=1.0 \
--class_prompt="cat" --num_class_images=200 \
--instance_prompt="photo of a skssks cat" \
--resolution=512 \
--enable_xformers_memory_efficient_attention \
--train_batch_size=2 \
--learning_rate=1e-5 \
--lr_warmup_steps=0 \
--max_train_steps=250 \
--scale_lr --hflip \
--modifier_token "skssks" 二、Stable Diffusion WebUI软件安装
- 打开科学上网工具
- 安装Python(版本号3.10.6)并勾选“Add Python To Path”
- 安装git
- 从Github网址拖最新源码
- 去抱抱脸网站下载stable diffusion 1.5的模型文件,大约4G。放到目录C:\AlexOuyang\app\SD\models\Stable-diffusion下
- 运行webui-user.bat,下载很多依赖后,打开浏览器访问http://127.0.0.1:7860就可以使用了。
三、仿写Stable Diffusion WebUI
3.1 各模型支持的提示词权重
在modules中有个文件叫sd_samplers.py,里面会调用prompt_parser.py。这个文件包含了stable-diffusion-webui的特殊提示词语法,例如:“((best quality))”会被处理成[‘best quality’, 1.21]最终传递给Text Encoder做tokenize。
实际上根据测试,语法(())本身在stable diffusion上就是支持的,请看下面代码
import torch
from PIL import Image
from diffusers import StableDiffusionPipeline, UniPCMultistepScheduler
prompts = ["a red cat playing with a ball","a red cat playing with a (ball)","a red cat playing with a ((ball))",
"a red cat playing with a (((ball)))","a red cat playing with a ['ball',1.1]"]
def concat_images(images):
"""Generate composite of all supplied images."""
# Get the widest width.
width = max(image.width for image in images)
# Add up all the heights.
height = sum(image.height for image in images)
composite = Image.new('RGB', (width, height))
# Paste each image below the one before it.
y = 0
for image in images:
composite.paste(image, (0, y))
y += image.height
return composite
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.to("cuda")
pipe.enable_xformers_memory_efficient_attention()
generator = torch.Generator(device="cuda").manual_seed(13)
print(prompts)
images = pipe(prompts, generator=generator, num_inference_steps=20).images
concat_image = concat_images(images)
concat_image.save('prompt_weighting_test.jpg')
3.2 中文提示词
AltDiffusion支持中文提示词
四、使用Dreambooth for SD插件
从LV牌官网找几张包包各个角度的图片,生成一张全新的此包包的图片。
4.1 安装插件
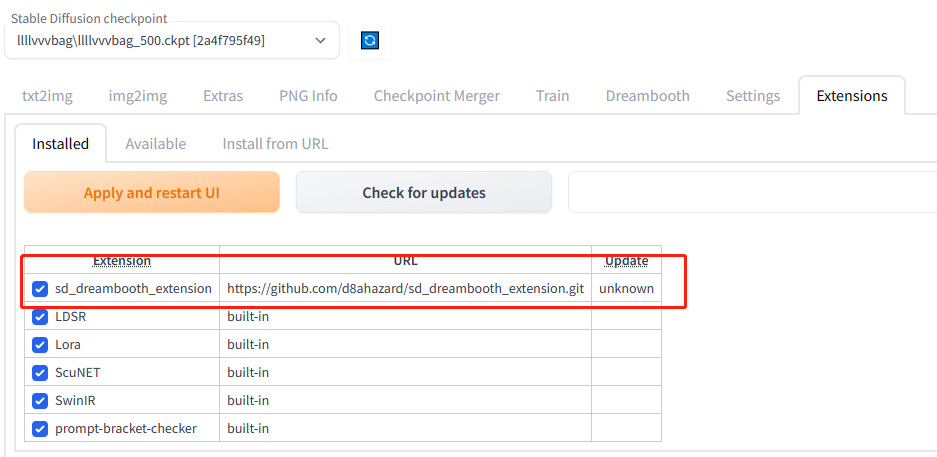
4.2 创建空模型(create)
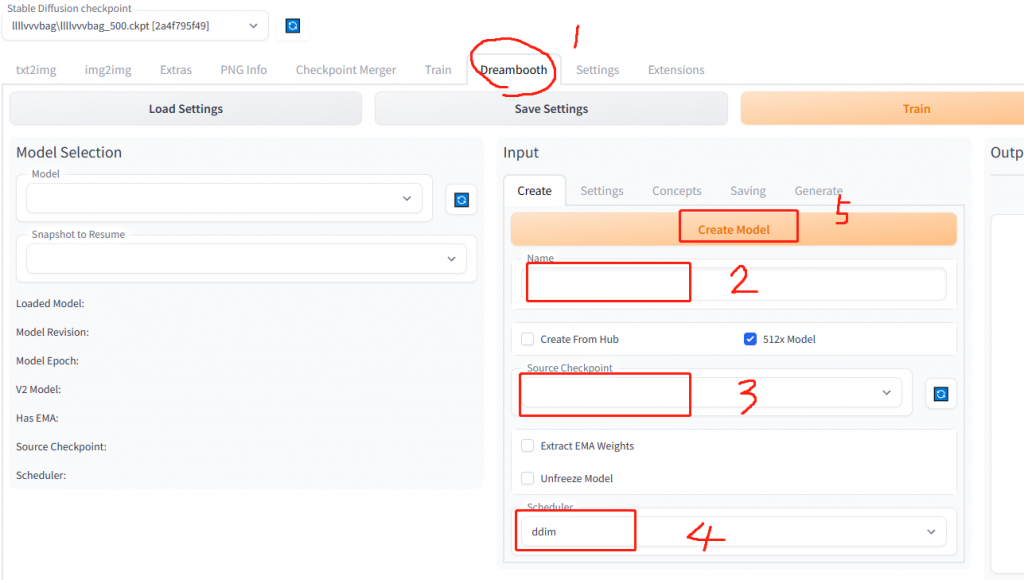
其中source checkpoint选择sd1.5模型,第一次使用会下载一些依赖包,之后每次创建模型大约2分钟左右。
4.3 准备数据
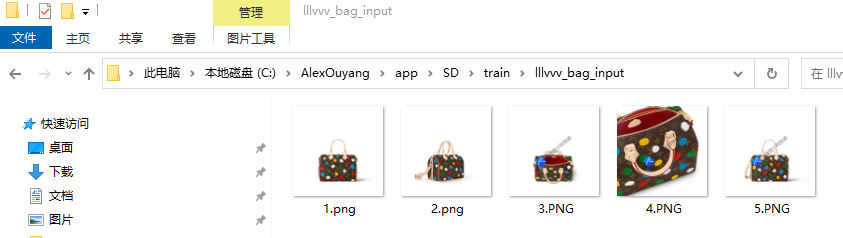
4.4 参数设置(settings)
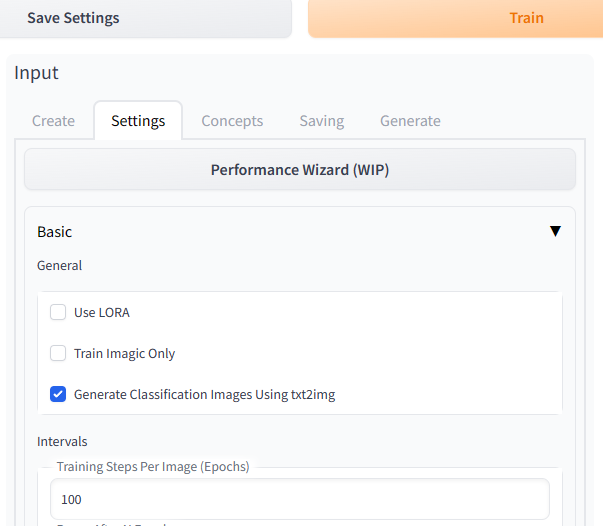
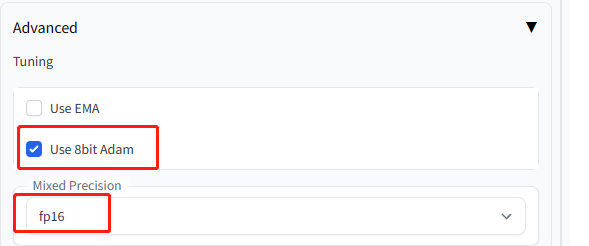
设置学习率为0.00001,设置高级–>8bit Adam和fp16
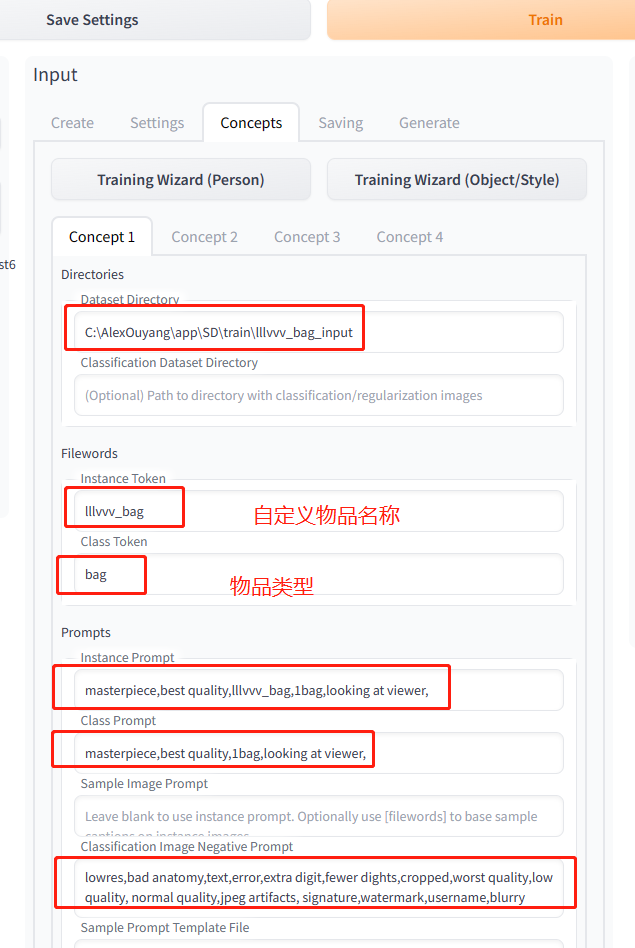
4.5 配置物品参数(concepts)
点击“Training Wizard (Object/Style)”,这时候Settings会自动调节为Object/Style默认值。插件tip建议训练物体不需要用prior-preservation。
点击上方菜单“Train”开始训练
4.6 合成ckpt文件
训练完成后,点击Generate Ckpt按钮合成一个大的ckpt文件。
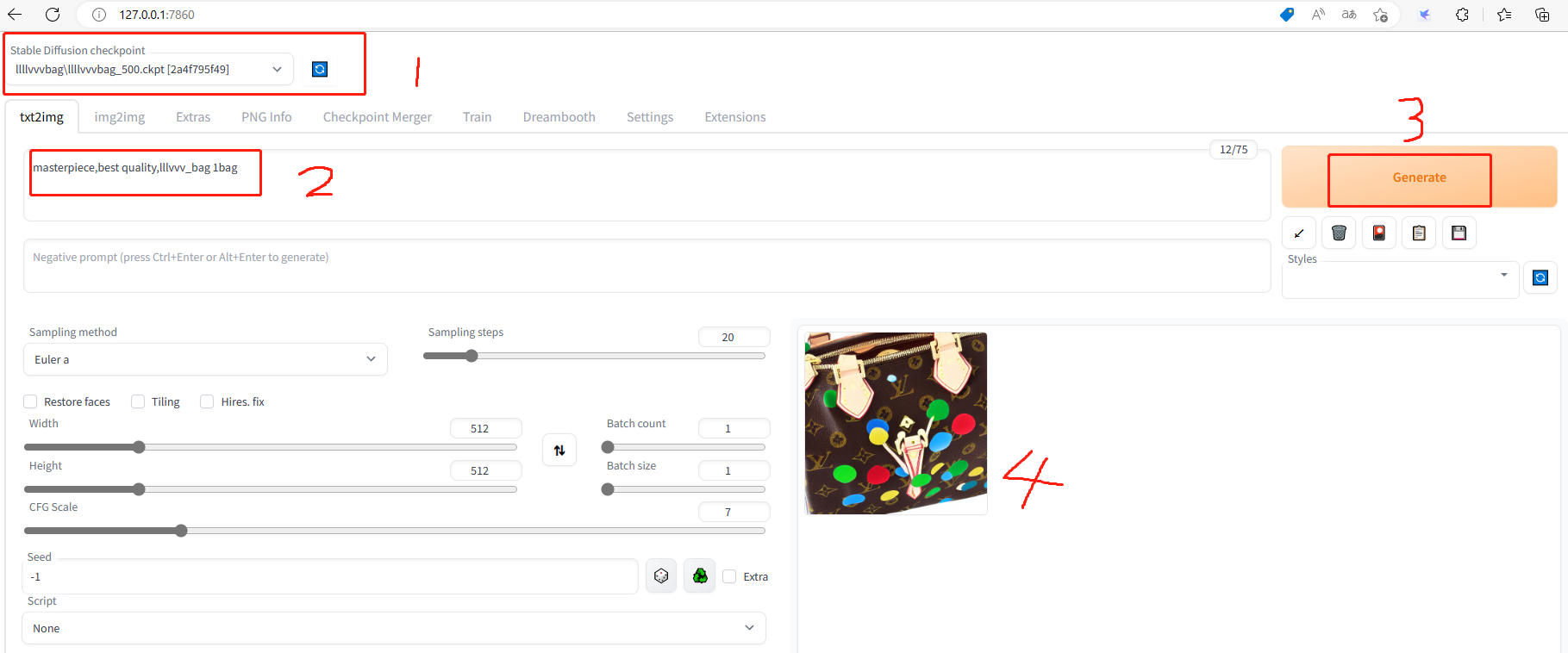
4.7 测试效果
切换到txt2img
五、使用ControlNet For SD插件
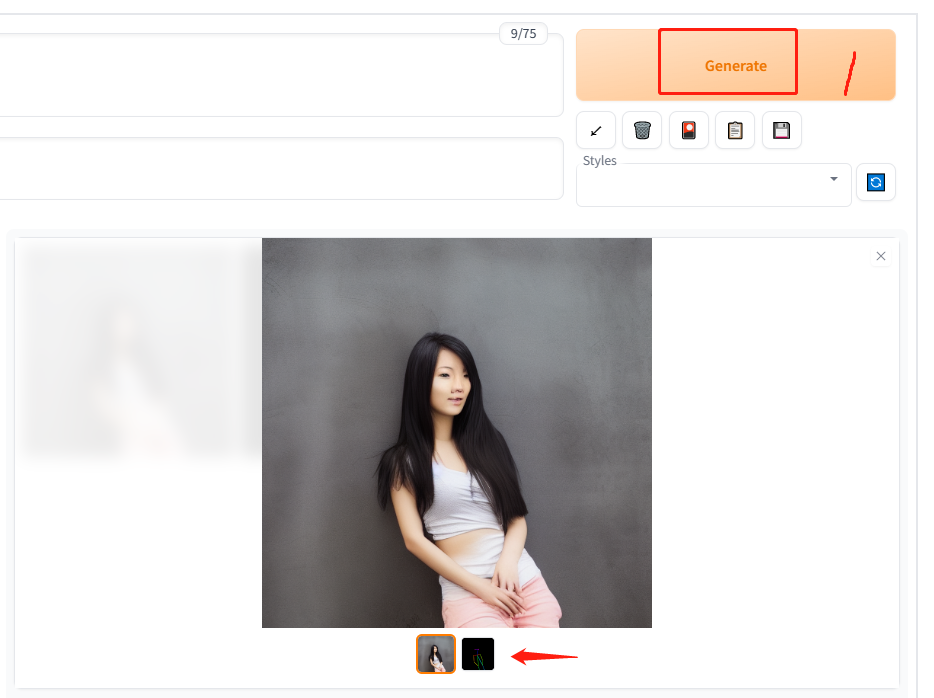
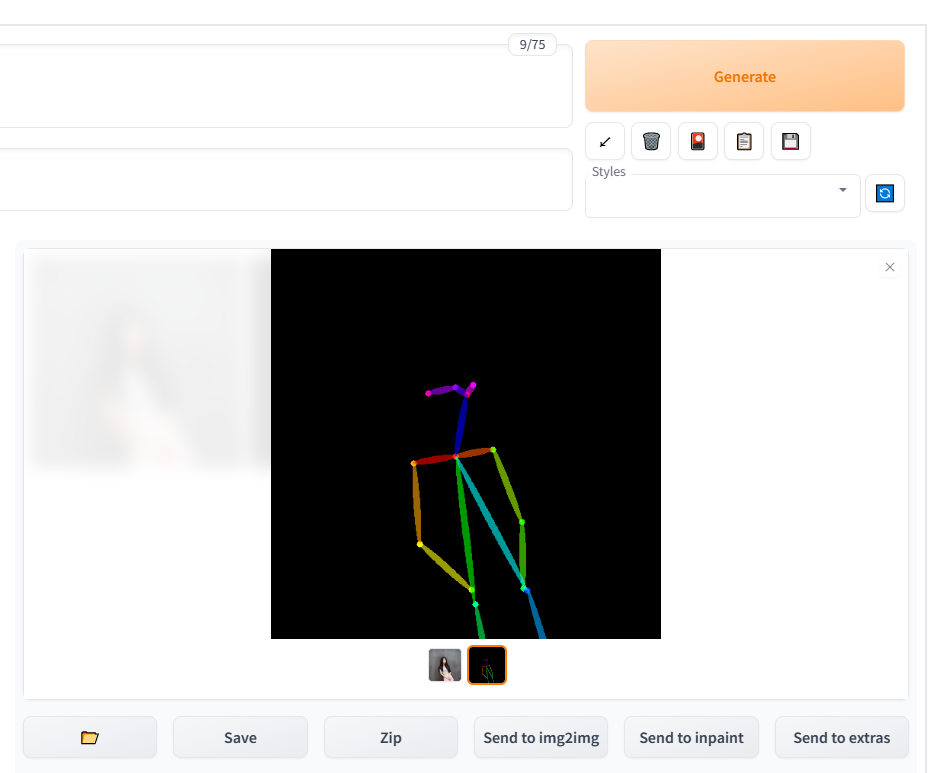
找一张模特的姿势图片,生成同样姿势的另外一个模特的图片。
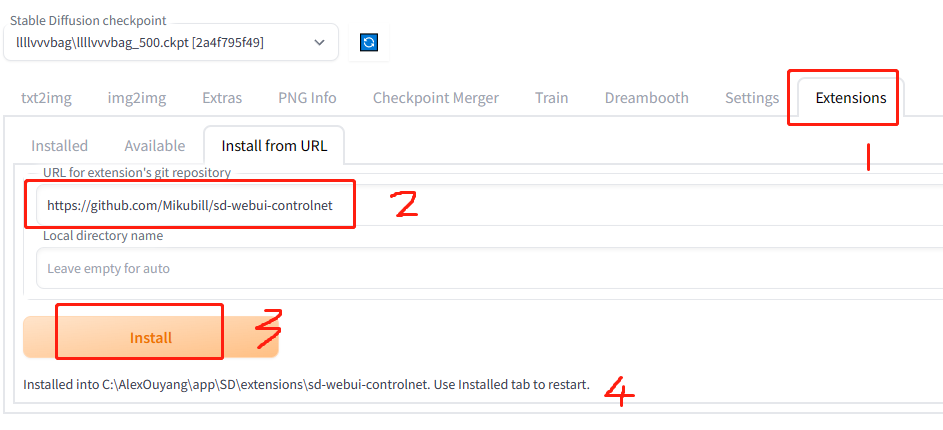
5.1 安装插件
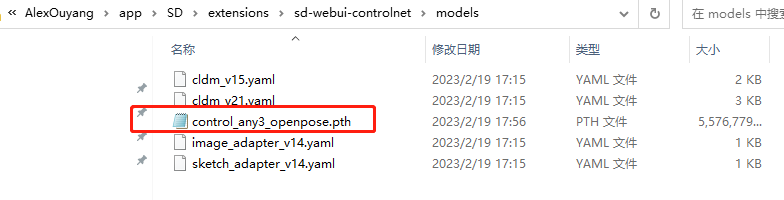
5.2 下载pose模型
从抱抱脸网站下载control_any3_openpose.pth,下载后复制到文件夹C:\AlexOuyang\app\SD\extensions\sd-webui-controlnet\models,大约有5.3G,请耐心等待。
5.3 准备数据
从商业测试数据选取456号模特中的任意一张图作为姿势引导图
5.4 配置参数
在文生图页签中选中ControlNet,配置如下:
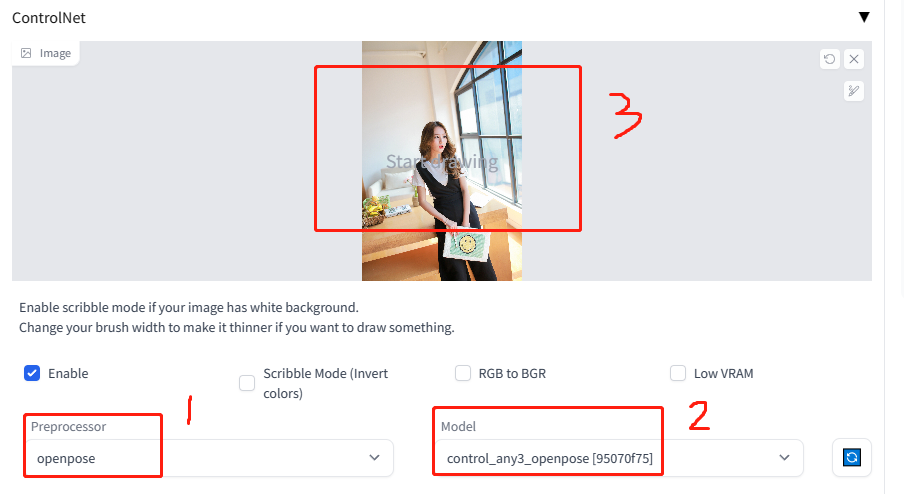
5.5 点击生成
六、源码理解
stable-diffusion-webui分为几个部分:
- launch.py : prepare_environment() 安装依赖库,下载github源码
- webui.py : 安装好一次后就可以跳过前面步骤,直接从这个文件启动程序。它分为两种模式:api_only()和webui()。
- 如果使用了webui模式会使用框架gradio,它定义了call_queue.py做异步,分离了前端网页和后台算法,保证用户不会卡死。下面以文生图为例介绍:
- txt2img.py : 从队列中取任务并调用processing.py中的process_images
- processing.py : 它的方法process_images_inner是文生图和图生图都要用的。
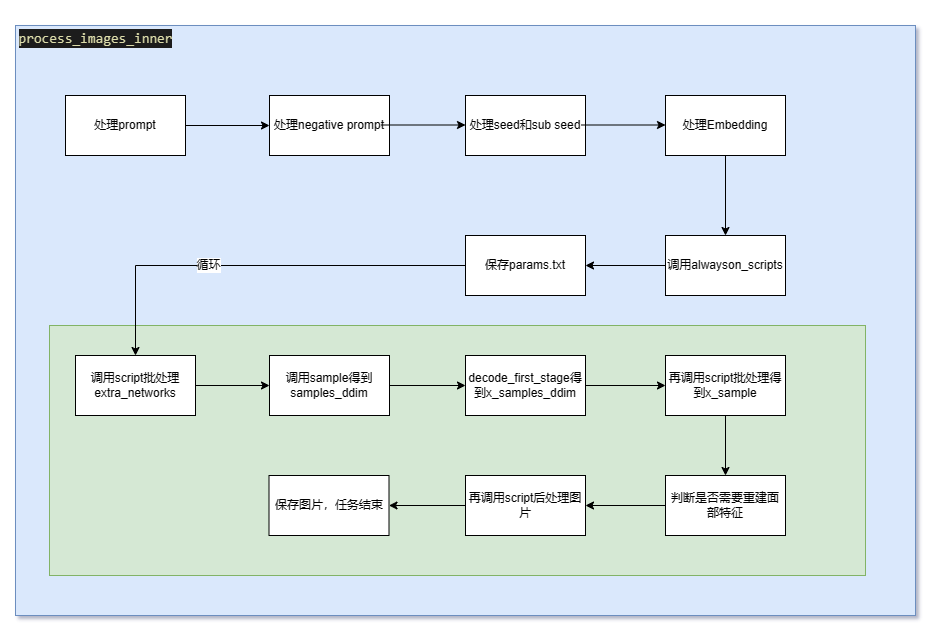
process_images_inner关键流程:
- 通过p.scripts.process(p)调用alwayson脚本(包含插件里面的脚本);
- 通过extra_networks.parse_prompts和p.scripts.process_batch(p, batch_number=n, prompts=prompts, seeds=seeds, subseeds=subseeds)处理扩展网络;
- 通过samples_ddim = p.sample(xxxx)执行生成过程,得到张量samples_ddim;
- 执行p.scripts.postprocess_batch(p, x_samples_ddim, batch_number=n)后处理x_samples_ddim;
- 迭代x_sample执行p.scripts.postprocess_image(p, pp)后处理image最后得到生成结果
如下流程图所示:
附录
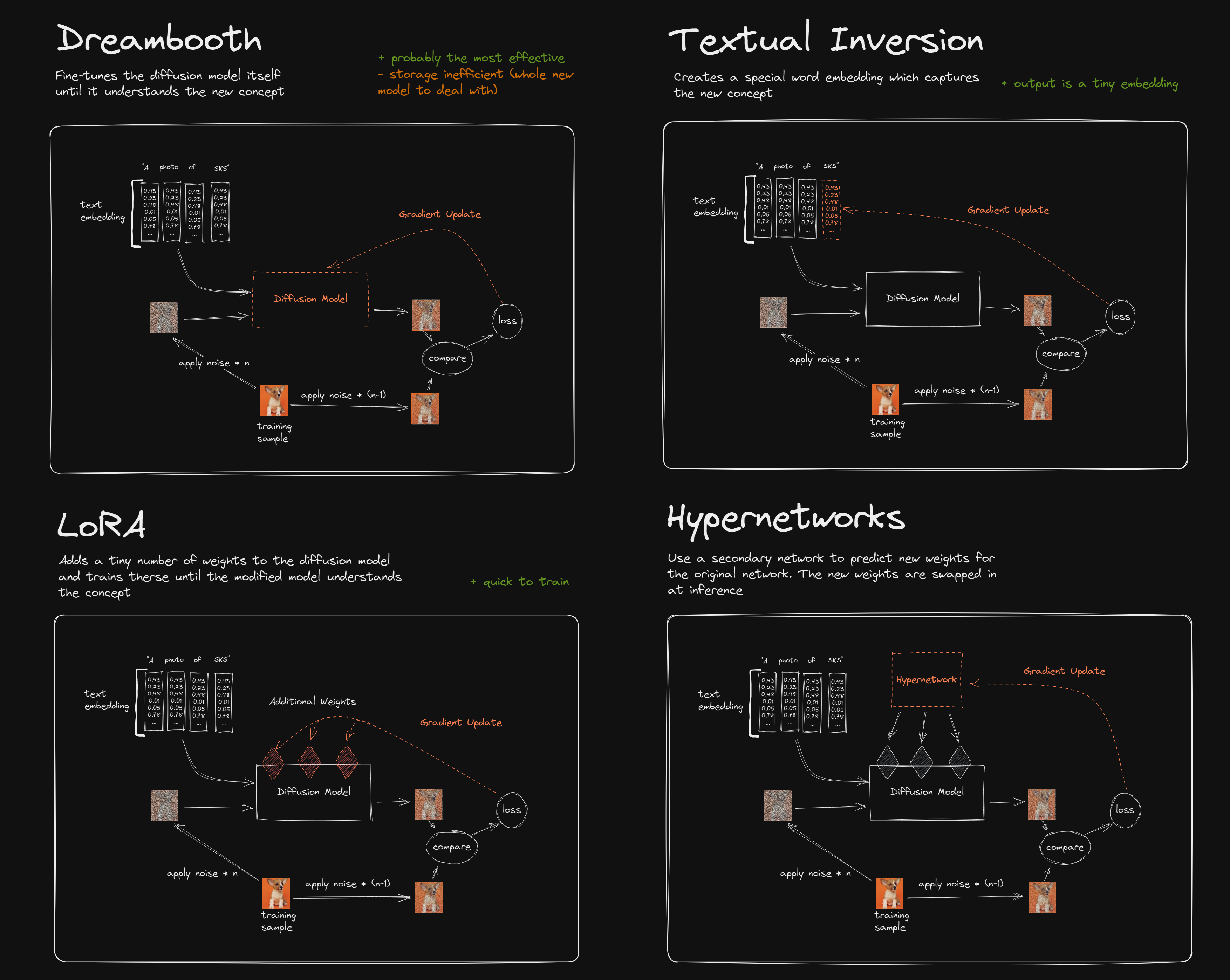
主流调优sd模型的方法:
Q1:xformers没有被安装
请打开webui-user.bat,修改下面一行
set COMMANDLINE_ARGS=--xformersQ2:报错Repo id must use alphanumeric chars or ‘-‘, ”, ‘.’, ‘–‘ and ‘..’ are forbidden, ‘-‘ and ‘.’ cannot start or end the name, max length is 96_
请把项目根目录改名叫SD(或者任何不含特殊字符的名字)
Q3: TypeError: ‘NoneType’ object is not subscriptable | Error verifying pickled file from C:\AlexOuyang\app\SD\models\Codeformer\
下载Codeformer未完成,删掉models/Codeformer/里面的对应模型,重新下载。
测试用图

参考资料
stable diffusion图文关系可解释性(diffusion attentive attribution maps)