目录
可随意转载Update2023.04.24
前言
一、 自主GPT
所谓自主(autonomous)GPT是设计一个Agent,让它自己做计划、决策和动作,通过源源不断的迭代,去完成设定的目标。比如 AutoGPT 。
AutoGPT把GPT的能力推向了更高的应用层次。设定一个任务:赚xx美金。AutoGPT通过十轮甚至更多的与互联网、GPT的交互达到令人震惊的效果。在它的背后是什么原理呢?
1.1 工作记忆
chatGPT本质是无状态的,用户感受到连续对话是通过每次输入之前多轮对话历史做到的。这种多轮对话学术上被称为“短期记忆”。常见的为以下三种:
- 主动用prompt引导
- ReAct
- Self Ask
通过工作记忆,我们可以把复杂任务拆分成多个小的子任务,引导chatGPT完成越来越复杂的任务。
当需要chatGPT来扮演某种角色的时候,我们就会用到“长期记忆”。我们会将长期记忆存储在外部数据库中,当开启chatGPT对话时,从外部数据库提取长期记忆并作为初始prompt输入chatGPT。
假如长期记忆很大很长超过了chatGPT单次可处理的token数怎么办呢?
这种情况非常常见,我们会通过Embedding模型把它进行高度压缩并存储在vector数据库中。
1.2 提示词工程
把LLM当成具有“智慧”的生物,我们怎么样提问能更好的与它交互呢?
一般情况下,我们把提示词分为四类:
- 指令:要求LLM完成的任务
- 输出格式:对LLM提出的输出的要求
- 上下文:给大模型一些外部信息作为输入
- 问题:给LLM的具体问题
二、 langchain介绍
2.1 langchain入门
当你拿到这些LLM模型要怎么用呢?
langchain是一个连接APP和LLM之间的一个中间层框架。请看下面的例子:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain import OpenAI,VectorDBQA
from langchain.document_loaders import DirectoryLoader
from langchain.chains import RetrievalQA
import os
os.environ["OPENAI_API_KEY"] = 'your openai key'
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader('/movies/', glob='**/*.csv')
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader.load()
# 初始化加载器
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(documents)
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma.from_documents(split_docs, embeddings)
# 创建问答对象
qa = VectorDBQA.from_chain_type(llm=OpenAI(), chain_type="stuff", vectorstore=docsearch,return_source_documents=True)
# 进行问答
result = qa({"query": "电影《红高粱》简介?"})
print(result)上面这段代码从本地csv文件中解析电影数据,并切分存储到vector数据库(Chroma)中,通过from_chain_type函数参数llm=OpenAI()传递给OpenAI GPT,返回result,利用langchain框架就完成了一个最简单的AI驱动的APP开发。
2.1.1 文本嵌入
langchain为各种支持text Embedding的模型提供了接口类。如果使用OpenAI作为LLM,可能需要用:text-embedding-ada-002这个模型。
文本嵌入作用是把一段文本编码成vector,然后通过向量近似算法来查询。常见用法是:
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])2.1.2 文档索引
langchain定义了四种索引方式
- Stuffing 直接把文档作为prompt输入给OpenAI
- MapReduce 对于每个chunk做一个prompt(回答或者摘要),然后再做合并
- Refine 在第一个chunk上做prompt得到结果,然后合并下一个文件再输出结果
- Map-Rerank 对每个chunk做prompt,然后打个分,然后根据分数返回最好的文档中的结果
2.2 langchain agent
要实现类似AutoGPT的功能,就不能只依赖静态的、预编码的chain,而需要具备动态生成chain的能力。因此需要用到Agent这个概念,langchain也开发了对应的功能:Agents
2.2.1 Tools
Agents自身不会去完成动态部分的工作,它依赖Tools类,除了buildin的Tools,它还支持用户自定义。有两种方法定义Tools:基于Tool类、继承BaseTool。最方便的是用python语法糖 @tool
from langchain.agents import tool
@tool
def search_api(query: str) -> str:
"""Searches the API for the query."""
return f"Results for query {query}"class SearchInput(BaseModel):
query: str = Field(description="should be a search query")
@tool("search", return_direct=True, args_schema=SearchInput)
def search_api(query: str) -> str:
"""Searches the API for the query."""
return "Results"2.2.2 Agents
普通agent
class FakeAgent(BaseSingleActionAgent):
# 同步
def plan(
self, intermediate_steps: List[Tuple[AgentAction, str]], **kwargs: Any
) -> Union[AgentAction, AgentFinish]:
...
# 异步
async def aplan(
self, intermediate_steps: List[Tuple[AgentAction, str]], **kwargs: Any
) -> Union[AgentAction, AgentFinish]:
...LLM agent
# LLM chain consisting of the LLM and a prompt
llm_chain = LLMChain(llm=llm, prompt=prompt)
tool_names = [tool.name for tool in tools]
agent = LLMSingleActionAgent(
llm_chain=llm_chain,
output_parser=output_parser,
stop=["\nObservation:"],
allowed_tools=tool_names
)MRKL agent
MRKL(Modular Reasoning, Knowledge and Language)由一组模块(例如Google搜索、API调用、数据库查询等)和一个路由器组成,决定如何将自然语言查询“路由”到适当的模块。在langchain框架中包含了三块
- Tools
- LLMChain: 生成text,依据text决定采用哪种action
- Agent
# Tools
search = SerpAPIWrapper()
tools = [
Tool(
name = "Search",
func=search.run,
description="useful for when you need to answer questions about current events"
)
]# LLMChain,需要输入参数prompt
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)# Agent
tool_names = [tool.name for tool in tools]
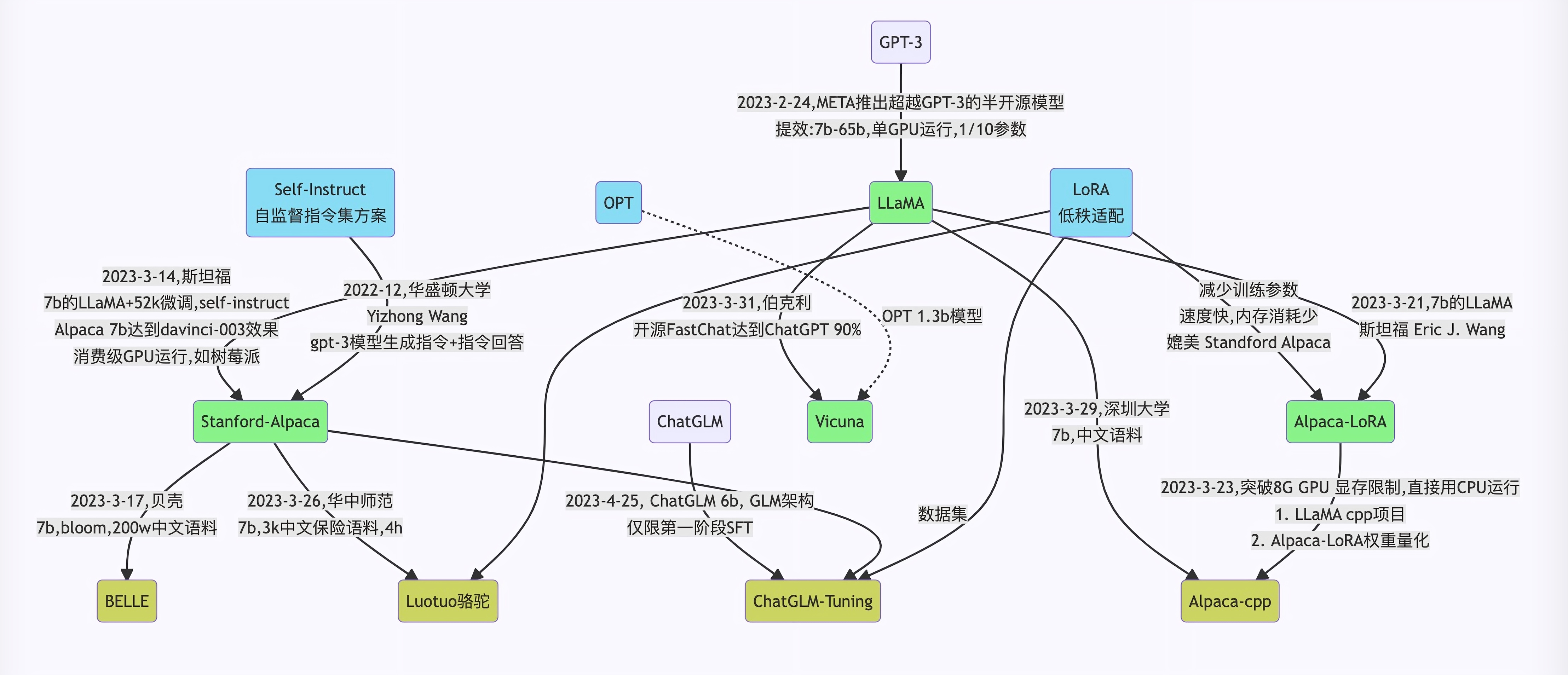
agent = ZeroShotAgent(llm_chain=llm_chain, allowed_tools=tool_names)在国内使用openai有诸多限制。另外客户也会担心数据安全,因此我们找到了GPT的开源替代ChatGLM-6B。
三、chatGLM-6B介绍
chatGLM-6B是基于 General Language Model 架构,使用了和 ChatGLM 技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术,具有 62 亿参数的LLM。
# 在langchain-ChatGLM代码中只需要修改model_config.py中的下面一行,即可实现本地加载
llm_model_dict = {
"chatglm-6b-int4-qe": "THUDM/chatglm-6b-int4-qe",
"chatglm-6b-int4": "THUDM/chatglm-6b-int4",
"chatglm-6b": "C:\\AlexOuyang\\app\\GPT projects\\langchain-ChatGLM\\models\\chatglm-6b",
"chatyuan": "ClueAI/ChatYuan-large-v2",
}四、langchain-ChatGLM
langchain-ChatGLM 是一个使用了langchain框架和chatGLM-6B模型打造的替代chatGPT的代码实现。可以实现企业级私有化部署。代码逻辑如下:
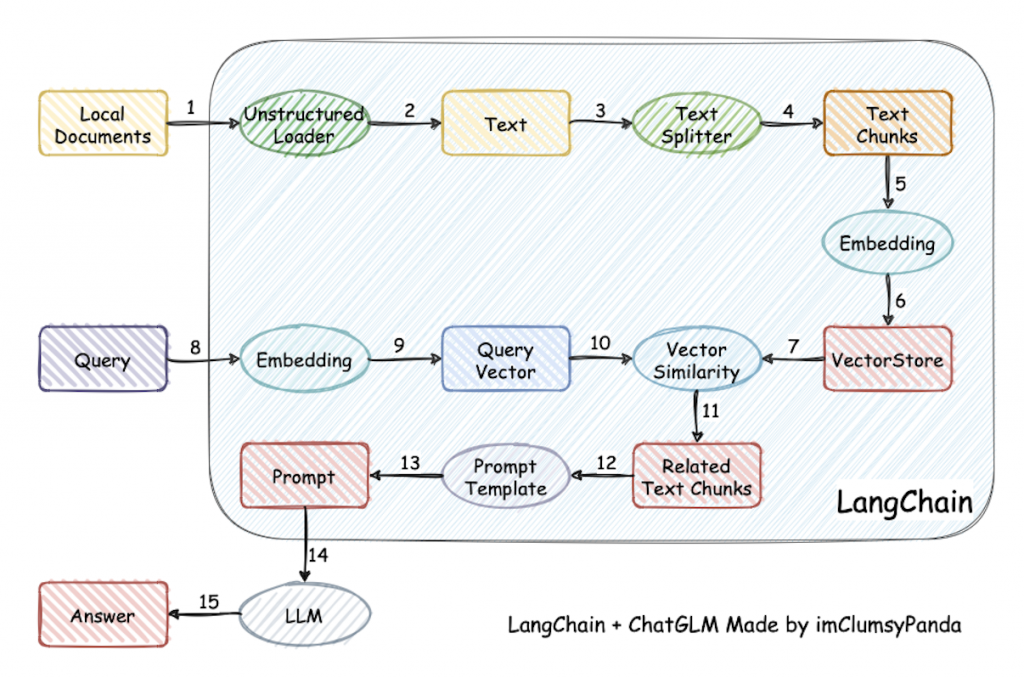
从开发路线图看,这个项目还落后于AutoGPT(没有实现最重要的Agent)

附录
sentence embedding for langchain