目录
请勿转载,违者必究 Update2023.11.12
一、研发团队
《ZEPHYR: DIRECT DISTILLATION OF LM ALIGNMENT》作者团队叫HuggingFaceH4,他们总结了行业内的先进方法并用最新最优的基座模型Mistral-7B微调了模型 Zephyr-7B,Huggingface作为开源社区的No.1,他们的成果是完全开源的具有很大的研究价值。
二、Zephyr-7B微调模型
2.1 Mistral-7B
Mistral-7B是一个在英语和代码数据上训练的基础模型,由于它非常优秀成为了当前(2023.10)最流行的开源模型。
自定义数据直接无监督fine tune Mistral-7B模型 notebook,效果肯定不会太好。
2.2 Zephyr-7B
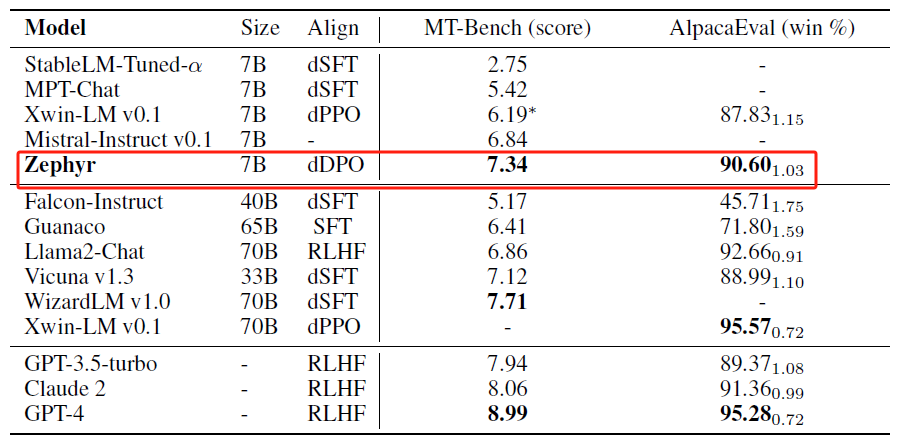
Zephyr-7B微调模型是 HuggingFaceH4 团队基于Mistral-7B模型,通过使用UltraChat数据集做dSFT,再用AI Feedback采集的UltraFeedback数据集进行dDPO训练得到的supervised fine tune(SFT)模型,结果显示很牛逼,源代码在:https://github.com/huggingface/alignment-handbook(2023-11-10已开源训练代码)。
三、dSFT-偷师学艺
因为成本太大,开源模型不可能达到商业模型(例如:GPT-4)的参数量,因此斯坦福大学首次采用了Self-Instruct的方式,从GPT3.5模型中进行大量学习并最终研发出了Alpaca模型。HuggingFace团队把这种师徒学习的方法称为distilled SFT。它的优点是人工做Supervise成本太高,用商业模型做可以节省大量成本。
四、AIF-替代HF
众所周知,ChatGPT是用RLHF做的与人类对齐,同理,Human Feedback成本也非常高。 HuggingFace团队先把prompt输入到Claude、Falcon、Llama等模型中,然后将这些模型的response交给GPT-4打分(score),存储最高分ywin,最低分ylose,最后形成结果集(x, yw , yl )。
五、Direct preference optimization(DPO)
请直接阅读知乎大神的翻译:
DPO——RLHF 的替代之《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》
六、源码解析
TODO