目录
可随意转载。 Update 2024.08.09
官方源码:microsoft/rho: Repo for Rho-1(还没公开训练源码)
摘要
一般LLM训练对所有tokens统一最小化损失。我们提出:tokens是有权重的。我们深入分析训练动态发现了不同token的loss模式不同。我们引入了一种名为RHO-1的新方法。它采用了选择性语言建模(selective Language Modeling, SLM),它会选择有用tokens。我们的方法使用参考模型(RM)先对tokens进行评分,然后对具有高损失的tokens进行有针对性训练。在15B OpenWebMath语料库上,我们的方法在9个数学任务中的少样本测试中,准确性上取得了30%的提升。微调后,RHO-1的1B和7B模型在MATH数据集上分别达到了40.6%和51.8%的效果,与DeepSeekMath相当,但仅使用了3%的token量。此外,在80B token量上进行训练时,RHO-1在15个不同任务中效果平均提高了6.8%,不仅提高了预训练的效率,还提升了效果。
一、介绍
扩大模型参数和加大数据集能提升LLM的效果。然而,研究表明在所有TOKENS上训练不是最优的,数据过滤至关重要,各种启发式方法、分类器过滤训练文档中的tokens,能显著提高模型性能。
尽管如此,高质量数据集中仍然包含许多低质量的tokens,它们会对模型效果产生负面影响,如图2(上)。作者指出,移除这些tokens可能会改变文本语义,而且严格的过滤方法还可能会移除有用的数据,导致效果变差。此外,Web数据集的数据分布并不与下游应用的分布一致。例如,在TOKEN级别上,web语料库中包括幻觉或歧义的tokens。
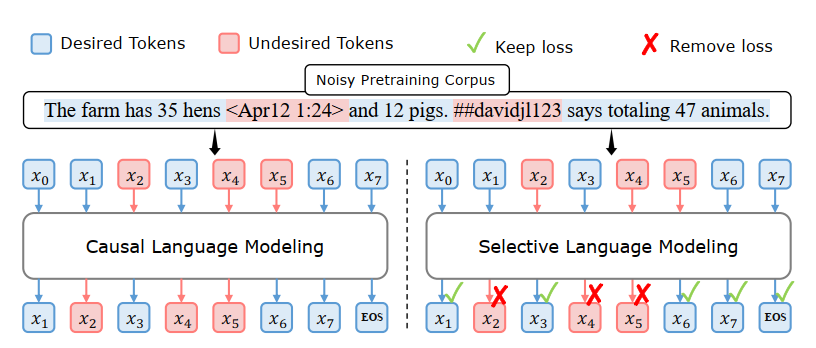
对所有tokens训练会导致在无用的tokens上浪费算力,还可能影响LLM的效果。为了深入了解LLM在预训练中TOKEN级别的学习方式,我们深入观察了预训练动态过程,特别是TOKEN级损失是如何演变的。在第2.1节中,我们在不同的检查点评估了模型的tokens困惑度指标(perplexity),并将tokens分类。我们发现在训练过程中,显著的损失下降仅限于部分的tokens。而一些tokens已经是“简单tokens”,已被模型学习,另一些tokens则是“困难tokens”,表现对loss下降的抵抗,导致预训练过程的无效梯度更新。
基于这些分析,作者提出了一种新颖的选择性语言建模(Selective Language Modeling, SLM)训练RHO-1。如图2(右)所示,这种方法将完整序列输入模型,并有选择性地移除不需要的tokens的损失。详细的流程在图4中描述:首先,SLM在高质量语料库上训练一个参考语言模型。该模型建立了效用指标,根据期望的分布对tokens进行评分,自然地过滤掉不干净和不相关的tokens。其次,SLM使用参考模型根据其损失对语料库中的每个token进行评分。最后,我们只训练那些在参考模型和训练模型之间显示出高额外损失的tokens的语言模型,有选择性地学习最有利于下游应用的tokens。
全面实验表明,SLM方法显著提高了预训练的效率,并改善了下游任务的性能。此外,我们发现SLM有效地识别了与目标分布相关的tokens,提高了SLM在基准测试中的困惑度 (perplexity) 分数。第3.2节展示了SLM在数学持续预训练中的有效性:1B和7B RHO-1在GSM8k和MATH数据集上的性能均超过CLM训练的基线16%以上。如图1所示,SLM达到基线准确性的速度高达10倍。值得注意的是,RHO-1-7B仅使用15B个tokens就匹配了DeepSeekMath-7B的最新性能,而DeepSeekMath需要500B个tokens。在微调后,RHO-1-1B和7B在MATH上分别达到了40.6%和51.8%。值得注意的是,RHO-1-1B是第一个超过40%准确性的1B语言模型,接近GPT-4早期的CoT性能42.5%。第3.3节证实了SLM在一般预训练中的有效性:使用SLM在80B tokens上训练Tinyllama-1B,在15个基准测试中平均提高了6.8%,在代码和数学任务中的提升超过10%。
二、SLM(selective Language Modeling)
2.1 预训练中的损失变化
我们的研究从仔细观察预训练中token loss变化开始。我们使用来自OpenWebMath的15B令牌对Tinyllama-1B进行预训练,并在每1B令牌后保存检查点。然后我们使用大约320,000个令牌的验证集在这些间隔评估令牌级损失。图3(a)揭示了一个特征:根据token loss的轨迹可以分为四类:
- 持续高Loss(H→H)
- Loss增加(L->H)
- Loss降低(H->L)
- 一致性低Loss(L->L)
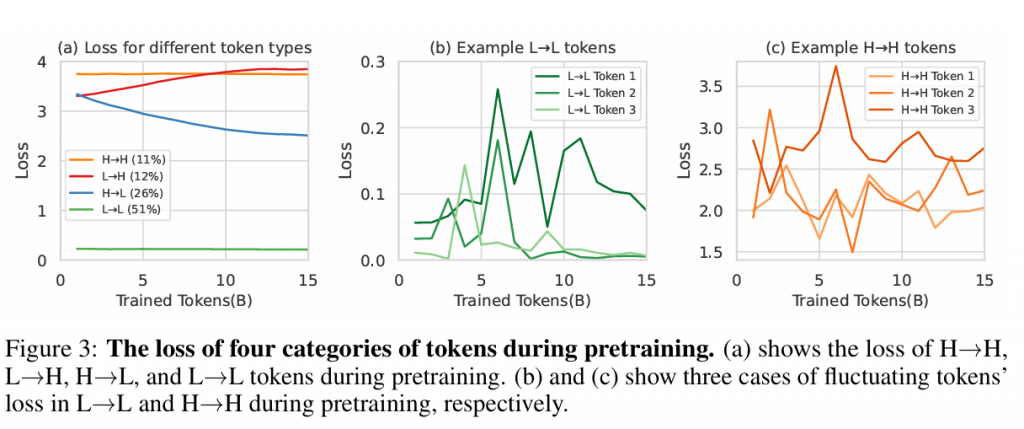
我们的分析发现仅有26%的令牌显示出显著的损失减少(H→L),而大多数(51%)处于L→L类别,表明它们已经被学习过了。有趣的是,11%的令牌持续具有挑战性(H→H),这可能是由于高随机不确定性。此外,在训练期间,有12%的令牌经历了意外的损失增加(L→H)。
第二个观察是,部分token loss持续波动抵抗收敛。如图3(b)和(c)所示,许多L→L和H→H令牌的损失在训练期间显示出高方差。在B.2节中,我们可视化并分析了这些令牌的内容,发现它们中的许多都是噪声,这与我们的假设一致。
因此,我们了解到,训练期间与每个令牌相关的损失并不像整体损失那样平滑减少;相反,不同令牌之间存在复杂的训练动态。如果我们能夜选择适当的令牌让模型在训练期间集中注意力,我们可能能够稳定模型训练的轨迹并提高其效率。
2.2 Selective Language Modeling
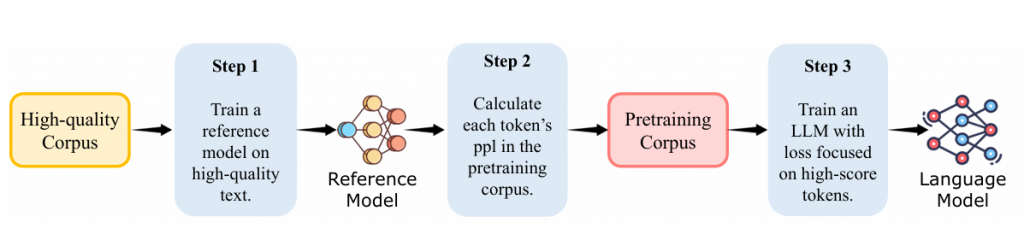
- 方法概述:提出了选择性语言建模(SLM),该方法在预训练阶段有选择性地关注那些与训练模型相比参考模型损失更高的令牌。
- 参考模型训练:首先在高质量数据集上训练一个参考模型,用来评估预训练语料库中每个令牌的损失。
- 选择性预训练:然后,使用参考模型的评估结果来选择性地训练语言模型,重点关注那些具有高额外损失的令牌。
实验结果
- 数学任务:在数学任务上,RHO-1在GSM8k和MATH数据集上的表现超过了因果语言建模(Causal Language Modeling, CLM)训练的基线模型,平均少数样本准确性提高了超过16%。
- 效率提升:RHO-1在达到基线准确性的同时,速度提高了10倍。
图表分析
- 图3:展示了不同类别令牌在预训练期间的损失变化,包括H→H、L→H、H→L和L→L令牌的损失变化。
- 图4:描述了选择性语言建模(SLM)的流程,包括训练参考模型、计算令牌损失和选择性训练语言模型。
实验设置
- 数据集:使用了OpenWebMath(OWM)数据集,该数据集包含来自Common Crawl的数学相关网页的大约14B令牌。
- 模型设置:对Tinyllama-1.1B和Mistral-7B模型进行了持续预训练,并使用了特定的学习率和批次大小。
贡献和结论
- 作者展示了SLM在预训练期间显著提高了令牌效率,并在下游任务上提高了性能。
- 发现SLM有效地识别了与目标分布相关的令牌,从而在基准测试中提高了模型的性能。
3 实验
3.1 实验环境
- 参考模型训练:作者为数学参考模型收集了0.5B个高质量、数学相关的令牌数据集,并训练了参考模型。
- 预训练语料库:使用了OpenWebMath(OWM)数据集,该数据集包含来自Common Crawl的数学相关网页的约14B令牌。
- 预训练设置:对Tinyllama-1.1B和Mistral-7B模型进行了持续预训练,并设置了学习率和批次大小。
- 基线设置:使用了通过常规因果语言建模预训练的模型作为基线。
3.2 数学预训练结果
- Few-shot CoT Reasoning Results:使用少量样本链式思考(CoT)示例对基础模型进行了评估,RHO-1-Math在1B和7B模型上的平均少数样本准确性分别提高了16.5%和10.4%。
- Tool-Integrated Reasoning Results:在ToRA语料库上对RHO-1和基线模型进行了微调,并在MATH数据集上达到了40.6%和51.8%的最新结果。
3.3 通用预训练结果
- 一般预训练结果:通过在80B通用令牌上持续训练Tinyllama-1.1B,SLM在15个基准测试中平均提高了6.8%的性能,特别是在代码和数学任务中提升超过10%。
3.4 分析
- 选定令牌损失与下游性能的关系:作者分析了参考模型选定的令牌在预训练和下游任务性能之间的关系,并发现选定令牌的平均损失与下游任务性能呈正相关。