目录
可随意转载。 Update 2024.05.29
摘要
我们介绍了TinyLlama,一个紧凑的11亿参数的语言模型,它在大约1万亿个token上预训练了大约3个epoch。TinyLlama基于Llama 2的架构和分词器构建,并利用了开源社区贡献的各种进步(例如FlashAttention),实现了更好的计算效率。尽管体积相对较小,TinyLlama在一系列下游任务中展示了显著的性能。它显著优于现有体积相当的开源语言模型。我们的模型检查点和代码在GitHub上公开可用,地址为:https://github.com/jzhang38/TinyLlama
一、介绍
NLP最近进展由扩大LLMs的规模推动,在大量文本语料库上预训练的LLMs已经在广泛的任务上证明了有效性。一些实证研究展示了LLMs中的涌现能力,这些能力可能只有在参数数量足够多的模型中才会显现,例如少样本提示(few-shot prompting)和思维链推理(chain-of-thought reasoning)。其他研究集中在对LLMs的scaling行为。Hoffmann等人(2022年)建议,为了训练一个计算最优模型,模型的大小和训练数据的数量应该以相同的速率增加。这提供了一个指导方针,即在计算预算固定时如何最优地选择模型大小和分配训练数据的数量。尽管这些研究明显倾向于大型模型,但用更大的数据集训练较小模型的潜力尚未被充分探索。Touvron等人(2023a)强调了推理预算的重要性,而不是仅仅专注于训练计算最优的语言模型。推理最优语言模型旨在在特定的推理约束下实现最优性能,这是通过训练比扩展法则(Hoffmann等人,2022年)推荐的更多的token的模型来实现的。Touvron等人(2023a)展示了,当用更多数据训练时,较小的模型可以匹敌甚至超越它们较大的对应模型。此外,Thaddée(2023年)建议现有的扩展法则(Hoffmann等人,2022年)可能无法在较小模型训练较长时间的情况下准确预测。
受到这些新发现的激励,这项工作专注于探索当训练的token数量显著多于scaling-law(Hoffmann等人,2022年)建议的数量时,较小模型的行为。具体来说,我们用大约3万亿个token训练了一个具有11亿参数的Transformer解码器模型。据我们所知,这是第一次尝试用如此大量的数据训练一个具有10亿参数的模型。遵循与Llama 2相同的架构和分词器(Touvron等人,2023b),我们将模型命名为TinyLlama。TinyLlama与现有体积相似的开源语言模型相比显示出竞争力。具体来说,TinyLlama在各种下游任务中超越了OPT-1.3B(Zhang等人,2022年)和Pythia1.4B(Biderman等人,2023年)。
我们的TinyLlama是开源的,旨在提高语言模型研究领域研究人员的可访问性。我们相信它出色的性能和紧凑的尺寸使其成为语言模型研究的研究人员和实践者的有吸引力的平台。
二、预训练
这一节描述了我们如何预训练TinyLlama。首先,我们介绍了预训练语料库的细节和数据采样方法。接下来,我们详细阐述了预训练期间使用的模型架构和超参数。
2.1 预训练数据
我们的主要目标是使预训练过程有效且可复现。我们采用自然语言数据和代码数据的混合来预训练TinyLlama,自然语言数据来自SlimPajama,代码数据来自Starcoderdata。我们采用Llama的分词器来处理数据。
SlimPajama
SlimPajama是一个大型的开源语料库,基于RedPajama创建,用于训练语言模型。最初的RedPajama语料库是一个开源研究项目,旨在复制Llama的预训练数据,包含超过1.2万亿个token。SlimPajama通过清洁和去重原始的RedPajama得到。
Starcoderdata
Starcoderdata这个数据集被收集用于训练StarCoder,一个功能强大的开源大型代码语言模型。它包含了大约2500亿个token,涵盖了86种编程语言。除了代码之外,它还包括涉及自然语言的GitHub问题和文本-代码对。为了避免数据重复,我们移除了SlimPajama中的GitHub子集,并且只从Starcoderdata中采样代码数据。
结合这两个语料库后,我们总共有大约9500亿个token用于预训练。TinyLlama在这些token上训练了大约三个epoch,正如Muennighoff等人(2023年)所观察到的,与使用独特数据相比,最多重复四个epoch的数据训练会导致最小的性能下降。在训练期间,我们采样自然语言数据,以实现自然语言数据和代码数据之间大约7:3的比例。
2.2 架构
我们采用了与Llama 2相似的模型架构。我们使用了基于Vaswani等人(2017年)的Transformer架构,并具有以下细节:

位置嵌入:
我们使用RoPE(旋转位置嵌入)来向我们的模型注入位置信息。RoPE是一种被广泛采用的方法,最近被许多主流大型语言模型使用,如PaLM、Llama和Qwen。
RMSNorm:
在预标准化中,为了获得更稳定的训练,我们在每个Transformer子层之前对输入进行标准化。此外,我们应用RMSNorm作为我们的标准化技术,这可以提高训练效率。
SwiGLU:
而不是使用传统的ReLU非线性,我们遵循Llama 2并将Swish和门控线性单元结合起来,这被称为SwiGLU,作为TinyLlama中的激活函数。
分组查询注意力:
为了减少内存带宽开销并加快推理速度,我们在模型中使用了分组查询注意力。我们有32个头用于查询注意力,并使用4组键值头。通过这项技术,模型可以在多个头之间共享键和值的表示,而不会牺牲太多性能。
2.3 训练速度优化
全部分片数据并行(FSDP):
在训练期间,我们的代码库集成了FSDP,以有效利用多GPU和多节点设置。这种集成对于跨多个计算节点扩展训练过程至关重要,这显著提高了训练速度和效率。
Flash Attention:
另一个关键改进是集成了Flash Attention 2,一个优化的注意力机制。代码库还提供了融合的layernorm、融合的交叉熵损失和融合的旋转位置嵌入,这些共同在提高计算吞吐量中发挥了关键作用。
xFormers:
我们把xFormers中的SwiGLU模块替换成了混合SwiGLU。有了这些特性,我们可以减少内存占用,使得11亿参数的模型能够在40GB的GPU RAM中运行。
性能分析与模型比较:
这些元素的整合将我们的训练吞吐量提高到每个A100-40G GPU每秒24,000个token。与像Pythia-1.0B和MPT-1.3B这样的其他模型相比,我们的代码库展示了更优越的训练速度。例如,TinyLlama-1.1B模型仅需要3456个A100 GPU小时来处理3000亿个token,相比之下,Pythia需要4830小时,而MPT需要7920小时。这展示了我们的优化的有效性,以及在大规模模型训练中节省大量时间和资源的潜力。
2.4 训练
我们的框架是基于lit-gpt构建的。遵循Llama 2的方法,我们在预训练阶段采用自回归语言建模目标。与Llama 2的设置一致,我们使用AdamW优化器,并将β1设置为0.9,β2设置为0.95。此外,我们使用余弦学习率调度,最大学习率为4.0 × 10^-4,最小学习率为4.0 × 10^-5。我们使用2000个预热步来促进优化学习。我们将批量大小设置为200万个token。我们将权重衰减设置为0.1,并使用1.0的梯度裁剪阈值来调节梯度值。我们在项目中使用16个A100-40G GPU来预训练TinyLlama。
三. 结果
我们在广泛的常识推理和问题解决任务上评估TinyLlama,并将其与几个具有类似模型参数的现有开源语言模型进行比较。
基线模型:
我们主要关注具有解码器架构的语言模型,大约包含10亿参数。具体来说,我们将TinyLlama与OPT-1.3B、Pythia-1.0B和Pythia-1.4B进行比较。
常识推理任务:
为了理解TinyLlama的常识推理能力,我们考虑了以下任务:Hellaswag、OpenBookQA、WinoGrande、ARC-Easy和ARC-Challenge、BoolQ以及PIQA。我们采用语言模型评估框架来评估模型。按照以往的实践,这些模型在这些任务上以零样本(zero-shot)的方式进行评估。结果在表2中呈现。我们注意到TinyLlama在许多任务上超越了基线模型,并获得了最高的平均分。
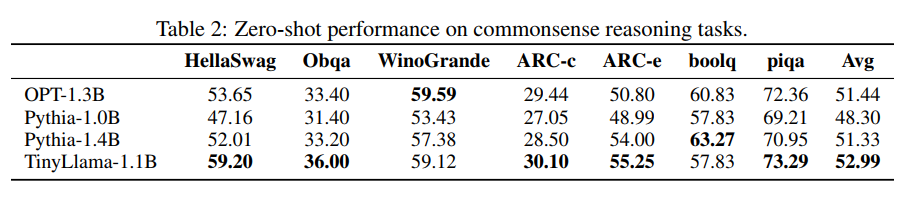
训练期间的性能演变:
我们跟踪了TinyLlama在预训练期间在常识推理基准上的准确性,如图2所示。总体而言,随着计算资源的增加,TinyLlama的性能得到了提升,在大多数基准测试中超过了Pythia-1.4B的准确性。
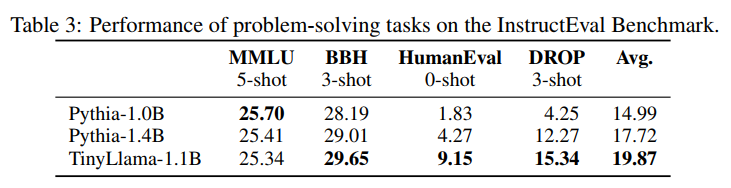
问题解决评估:
我们还使用InstructEval基准测试评估了TinyLlama的问题解决能力。此基准测试包括以下任务:
- 多任务语言理解(MMLU):此任务用于衡量模型在各个主题上的世界知识和问题解决能力。我们在5样本(5-shot)的设置中评估模型。
- 困难的BIG-Bench(BBH):这是来自BIG-Bench基准测试的23个具有挑战性任务的子集,旨在衡量语言模型在复杂指令跟随方面的能力。模型在3样本(3-shot)的设置中被评估。
- 段落上的离散推理(DROP):这个阅读理解任务衡量模型的数学推理能力。我们在3样本(3-shot)的设置中评估模型。
- HumanEval:此任务用于衡量模型的编程能力。模型在零样本(zero-shot)的设置中被评估。
评估结果在表3中呈现。我们观察到TinyLlama展示了比现有模型更好的问题解决技能。
四. 结论
在本文中,我们介绍了TinyLlama,一个开源的小型语言模型。为了促进开源大型语言模型预训练社区的透明度,我们已经公开了所有相关信息,包括我们的预训练代码、所有中间模型检查点以及我们数据处理步骤的详细信息。凭借其紧凑的架构和有希望的性能,TinyLlama可以支持移动设备上的最终用户应用程序,并作为一个轻量级平台,用于测试与语言模型相关的广泛创新思想。我们将利用在此项目公开、活跃阶段积累的丰富经验,旨在开发改进版的TinyLlama,为其配备多样化的功能,以增强其在各种任务中的性能和多功能性。我们将在即将发布的报告中记录进一步的发现和详细结果。