目录
禁止转载 Update 2024.06.28
背景知识介绍
1. 论文中常见英文词根“auto”如何理解?
英语中的“auto”通常有两种含义:
- 自动(automatic):表示某事物能够自动完成或运作
- 自我(self):表示某事物与其自身相关,通常指代由自己产生或影响自身的事物。
例如:
- Autoregressive模型中的“auto”表示“自我回归”,即该模型利用前序值来预测next token。
- AutoEncoder模型中的“auto”表示将输入encode后再decode为输入, 表示“编码自我” ,在这个过程中获得神经网络模型。
2. Transformer是不是AutoEncoder?
Transformer 由 Vaswani 等人在 2017 年提出,它的核心思想是使用自注意力机制(self-attention)来捕捉序列中的依赖关系。Transformer 主要由编码器(Encoder)和解码器(Decoder)组成。Transformer 并不是 AutoEncoder。
3. GPT的Decoder是不是AutoEncoder?
GPT 使用 Transformer 的 Decoder 结构,并对 Transformer Decoder 进行了一些改动。所以GPT也不是AutoEncoder。
一、自回归模型(Auto-regressive model, AR)
这类模型的特点是通过训练大量前序tokens,推理时预测下一个token。例如著名的GPT模型就是一种AR模型。
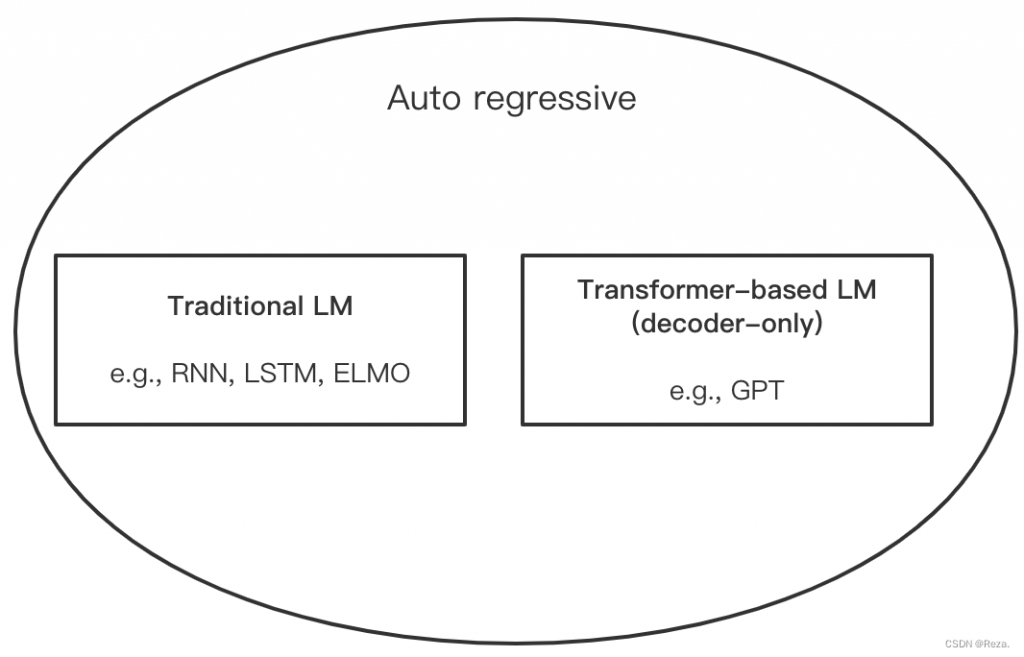
GPT是AR模型,同时它也是使用了Transformer的Decoder-only架构的Transformer-Based模型
二、自编码模型(Auto-encoder, AE)
Auto-encoder自编码器是1986年由Rumelhart 提出,常用于文本检索,以图搜图。
Auto-encoder的基本思路是:把高维输入encode成低维编码;然后,把低维编码decode成高维输入。
当代的编码/解码器一般都是可学习的神经网络。通过“一编一解”这种无监督的学习过程,获得编码器和解码器两个有用的神经网络。这两个神经网络可用来将输入降维或者特征提取(替代PCA,因为PCA是无法学习的,因此没法利用大量的数据作为先验知识)。
AE局限性:无法生成相似的图片。
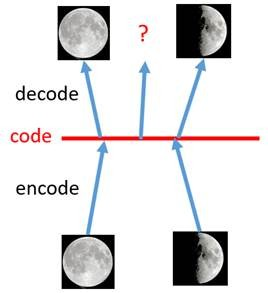
2.1 去噪自编码模型(Denoising AutoEncoder, DAE)
- DAE:在训练过程中随机dropout,研究结果显示此方法可以提升鲁棒性。效果如下图所示:。
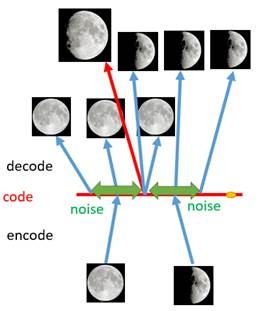
DAE生成图片更丰富了,但是随机噪声缺少普遍性,以及可控生成的可能性
2.2 变分自编码模型(VAE)
来自2013年论文《Auto-Encoding Variational Bayes》。作者通过晦涩难懂的推导,说隐藏层要加上正态分布最好,于是就有了VAE。
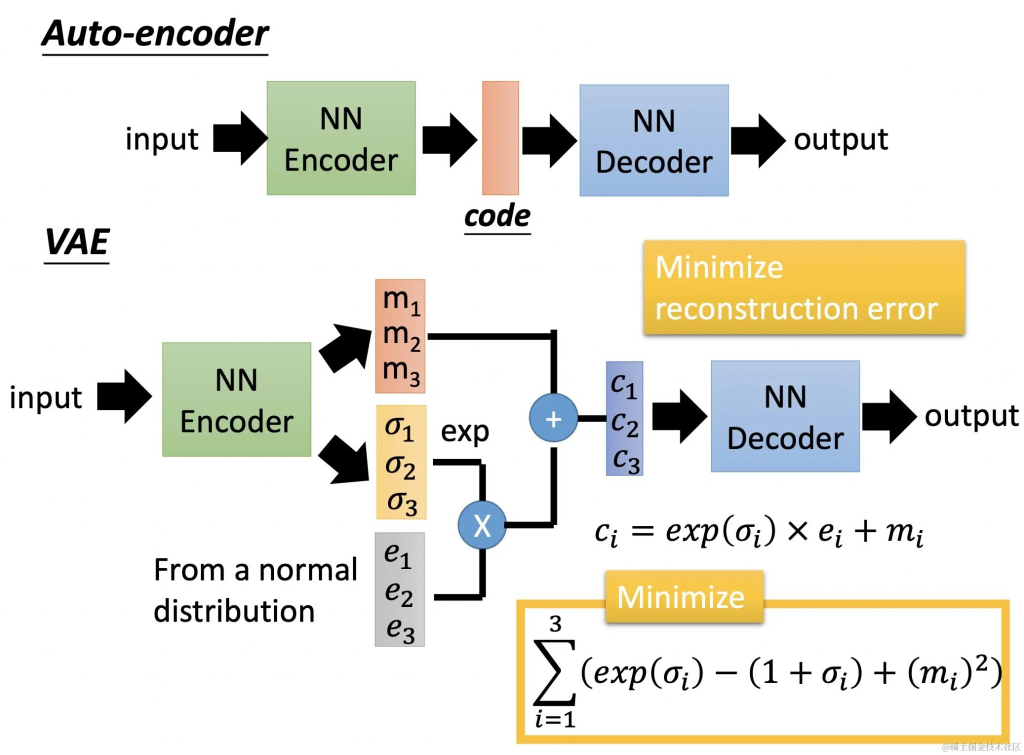
通俗理解:DAE的dropout方法属于工程性方法,理论派显然不满足,提出了加高斯噪声e实验证明它的生成能力更强。
2.3 VQ-VAE (Vector-Quantized Variational Autoencoders)
2017年来自google论文《Neural Discrete Representation Learning》,本质是离散化的AE。虽然名字里带了VAE,但是算法没有变分(variational)。
算法介绍(外链):VQVAE:言简意赅,轻松理解
算法简单理解:设计了CodeBook(Zq)代替低维连续空间Z,最小化 Zq 和Z的损失。通过训练,学习这个Vector-Quantized(有限的) CodeBook ( Zq ) 可以实现快速(对比PixelCNN)图像重建。这里的CodeBook意思是隐藏code的字典,本来隐藏code是无限的空间,变成了可查询的字典,速度自然快。
具体做法分两阶段:
- 把原始图像做离散化(VQ)
- 查询CodeBook,基于AR方法(Transformer decoder)的一块一块的解码,最后生成图像。
基于VQ-VAE,使用AR方式,VQ-GAN将每个patch,需要token个数个steps,例如:256或者1024。
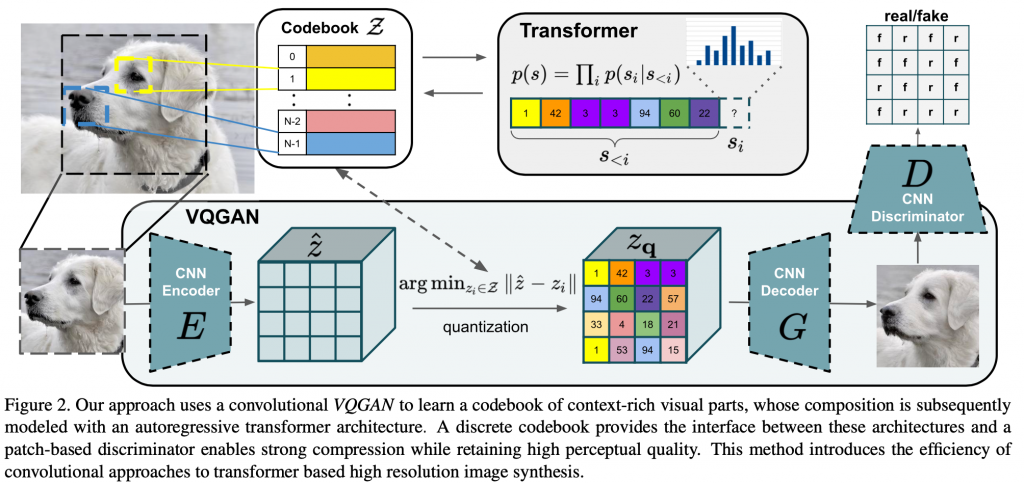
VQ-VAE 只能用于图像重建
三、MaskGIT模型
2022年,google发表论文MaskGIT,它是一种非AR的模型。
论文MaskGIT发现图片生成领域用Transformer结构替换了GAN之后,虽然效果提升了。但它们沿用了NLP领域的AR方式。而自回归解码的方法,生成next token 需要前面所有的 tokens 的信息。这个过程不能够并行,因此对于图像而言会非常慢。
论文借用Mask(掩码)将图片生成的速度提升了几十倍。具体做法分两阶段:
- 随机Mask掉输入中的图像块,然后训练模型(类似BERT算法),不仅仅是学习next token,而是学习整个上下文。
- 推理阶段,用训练好的模型固定steps生成完整的图像(非AR方式)。
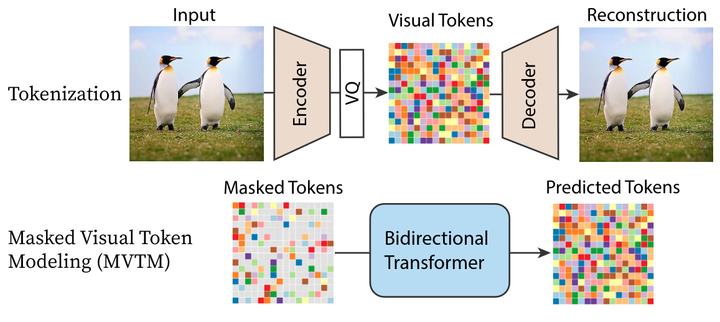
四、TiTok模型
2024年,字节跳动的论文Transformer-based 1-Dimensional Tokenizer (TiTok)发现在图片生成算法中,生成速度主要受到token数目的影响。论文认为图片生成默认的二维tokens是无必要的,于是改进了VQGAN算法,将Zq定义为一维tokens(最佳个数为32)。通过大幅压缩图片AR算法中的token数,大幅提升了图片AR的性能(400倍+)。
算法只替换了VQGAN的tokenizer,保留了了MaskGIT模型作为图像生成器,因此生成速度仍然比MaskGIT快。
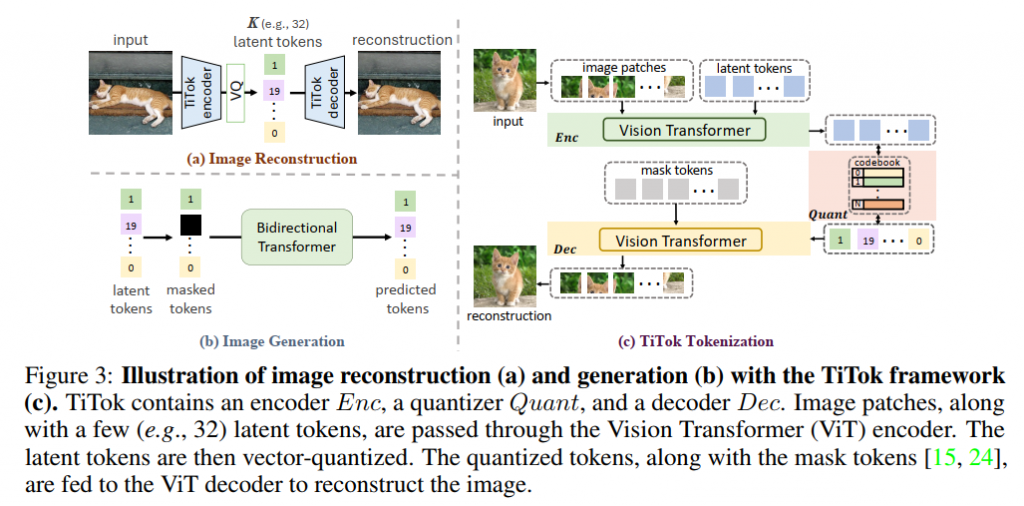
五、 AR模型与VQ
2024年KaiMing He在论文中《Autoregressive Image Generation without Vector Quantization》中质疑 Vector Quantization 的做法在图片生成领域是否必要?
论文提取使用per-token的去噪网络和AR模型做联合建模,代替CodeBook,速度更快,效果更好。这种方法跟LDM模型的区别是:LDM建模针对的是整张图片所有tokens的联合概率分布。
论文还一般化了图片生成的AR模型,在Masked AR(MAR)中,此方法仍然适用。(类似TiTok复用MaskGIT,一般来说MAR效率高于AR)
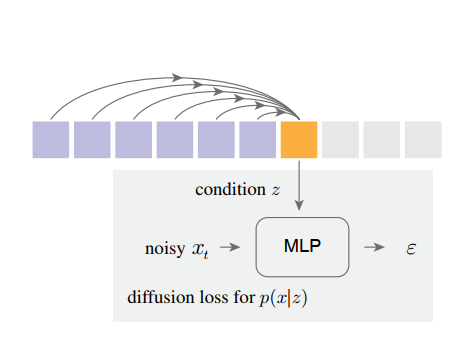
训练时,把next token相对前序tokens的权重矩阵定义为条件z,然后通过与时间t有关的噪声xt,训练这个以z为条件,t为时间步的加噪网络(从x0变成噪声ε),学习xt得到去噪网络(逆向)。
推理时,已知前序tokens和去噪网络权重,经过t个时间步可生成x0