禁止转载,违者必究。Update2024.07.25
一、Transformer
2017年《Attention is all you need》
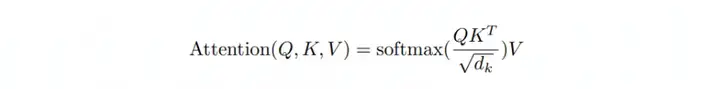
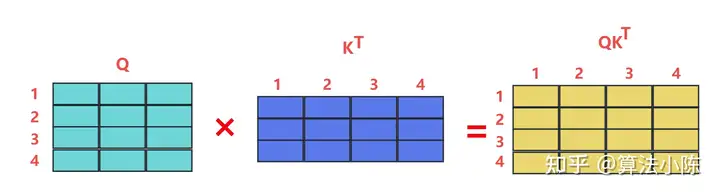
假如序列长度d,QKV都是输入的映射(projection),所以QKV维度都是d,因此Transformer的时间复杂度是O(d^2),如下图所示:
Transformer把要处理的文本(N>>d)分割成等长的片段,通常不考虑句子(语义)边界,导致上下文碎片化(context fragmentation)。通俗来讲,一个完整的句子在分割后,一半在前面的片段,一半在后面的片段。
一些常见的性能优化方法,优化平方时间复杂度问题:
- 权重剪枝(Weight Pruning)
- 权重分解(Weight Factorization)
- 权重量化(Weight Quantization)
- 知识蒸馏(Knowledge Distillation)
但是这些方法都不解决上下文碎片化问题,也不能解决平方级算力问题。
二、Transformer-XL
2019年 ACL《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》,用显存存储hidden states。
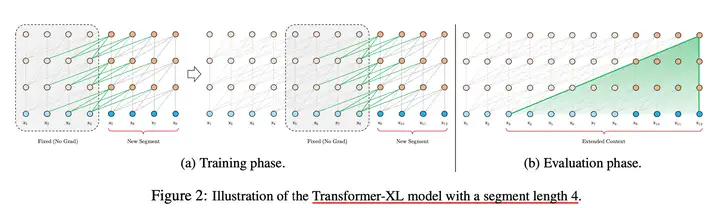
解决了上下文碎片化问题,提升了长文本效果,但是没有解决平方算力问题。
额外知识:论文同时提出了相对位置编码算法,取代了绝对位置编码。
三、稀疏Transformer
2019年《Generating Long Sequences with Sparse Transformers》,合理减少矩阵中的非0元素(稀疏化)实现计算加速。

另一篇论文Reformer使用局部敏感哈希(Locality-Sensitive Hashing, LSH)进一步将自注意力的复杂度降低到O(N log N)。本质是稀疏化矩阵,减小计算量。
四、线性注意力LA
《Transformers are RNNs:Fast Autoregressive Transformers with Linear Attention》
去掉了自注意力中的softmax,用sim函数代替。sim意思是“相似度函数”(similarity function),通过数学推导发现,sim函数可以是任何非负的核函数,例如多项式核或径向基函数(RBF kernel)。这篇论文将自注意力的计算复杂度从𝑂(𝑁^2)降低到线性𝑂(𝑁),从而显著提高了处理长序列的效率。
额外知识:使用低秩核替换了非线性函数softmax。
额外知识:后续研究表明非负核函数会导致训练不稳定并降低训练效果
五、低秩瓶颈LowRank Bottleneck
《Low-Rank Bottleneck in Multi-head Attention Models》提出多头注意力的低秩性是一个严重的瓶颈。
标准Transformer计算复杂度为n^2。每个Attention Head里边,是将原始的d维投影到d/h维,输出也是d/h维,然后把h个d/h维的结果拼接起来,最后得到一个d维的输出。通过QK映射后的参数量为2nd/h(其中d为Q,K的维度),且 2nd/h <<n^2,尤其是head(简称h)比较大的情况。所以用小参数表达 n^2 势必产生瓶颈。
线性注意力 LA表现出更严重的低秩瓶颈,因此在LA的后序论文中加大了秩矩阵的尺寸,导致了计算量增加).
六、State Space Model(SSM)理论
《HiPPO: Recurrent Memory with Optimal Polynomial Projections》 Albert Gu ,HiPPO算法成为了SSM(State Space Model)领域后序论文的基石。主要特性有:
- RNN对历史信息的遗忘速度是指数级的,而HiPPO的遗忘速度是多项式级,适合长序列模型
- 算法是线性ODE,也就是说比Transformer的O(n^2)快
- 算法具有timescale鲁棒性,这个特性对模型迁移特别重要
S4《EFFICIENTLY MODELING LONG SEQUENCES WITH STRUCTURED STATE SPACES》Albert Gu,将分段函数A(参数函数)经过数学推导改成了“对角+低秩函数“,提高了SSM的算法可用性。
DSS 《Diagonal State Spaces are as Effective as Structured State Spaces》使用对角( Diagonal )矩阵参数化状态空间,简化了 S4的复杂性。
额外知识:SSM的实际效果不好,因为它是线性时不变系统 ( Linear Time Invariance, LTI)。而Attention的QKV都是与输入数据有关的(data-dependent),后续一些论文的改进方向是SSM+Attention。
七、RetNet
《Retentive Network: A Successor to Transformer for Large Language Models》说Transformer性能不好,LA表达能力不行,S4虽然新但是表达能力也不行,在一些基准测试中不如Transformer。


RetNet的贡献在于提出了大语言模型的“不可能三角”(Training Parallelism、Low-Cost Inference、Good Performance),并给出了解决方案和推导过程。但RetNet仍然是参数数据无关(data-independent)的模型。
八、Data-Dependent Decay输入相关性的衰减率
HGRN 《Hierarchically Gated Recurrent Neural Network for Sequence Modeling》在RNN中间定义了有下界的可学习的遗忘门,使得模型上层关注长距离依赖,模型下层关注短距离依赖。
《Parallelizing Linear Transformers with the Delta Rule over Sequence Length》TODO
九、Mamba
Mamba 《Mamba: Linear-Time Sequence Modeling with Selective State Spaces》引入了data-dependent的模型参数,从S4升级到S6。论文的理论性很强。
Mamba2 《Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality》引入了SSD,效果:
与mamba相比:
- 参数A进一步从对角矩阵简化为标量乘以单位矩阵(scalar times identity)
- 使用了和Transformer类似的多头(head),叫P>1,相比之下mamba的P=1
与RetNet相比:
- 同样去掉了Attention中的非线性softmax,解决Attention Sink问题
- 引入了参数L,与QKT做哈达玛积,与RetNet中的参数D作用相似
参数L是data-dependent的,与HGRN等论文的想法又相同了。
与LA的形式化表达又相同了。

十、Llama3蒸馏为Mamba
《The Mamba in the Llama: Distilling and Accelerating Hybrid Models》作者之一就是Mamba的作者。
从头开始训练一个大模型太贵了,小模型直接训练效果不如大模型蒸馏。
Transformer做推理KV cache的显存占用是embedding长度的二次方,因此推理的显存需求比较大。而且MambaX的推理速度比Transformer快5倍且可以支持更长的上下文。

总而言之,RNN、Transformer、LA、SSM、Mamba、data-dependent这些所有的东西都逐渐统一,最终的目的都是刷论文。