目录
禁止转载,违者必究! Update 2024.08.19
前言
在大语言模型领域,LoRA(Low-Rank Adaptation)已成为一种非常实用的技术。随着模型规模的急剧扩大和训练语料库的增加,训练和推理的资源消耗非常惊人。LoRA的出现,为这一挑战提供了一条全新的解决之道。通过巧妙地降低模型参数的秩,LoRA不仅显著减少了计算和存储成本,更在性能上表现出色,为研究人员带来了新的可能性。本文将深入探讨LoRA系列算法的工作机制和改进方法,为初学者提供有价值的参考。
一、LoRA
《LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS》
在深度学习和人工智能领域,随着语言模型规模的不断扩大,如GPT-3这样的175B参数模型,传统的全参数微调方法面临着资源消耗巨大的挑战。这不仅增加了训练和部署的成本,也限制了模型在下游任务中的应用。为了解决这一问题,微软研究人员提出了一种创新方法——低秩适应( LOW-RANK ADAPTATION )。
LoRA的核心思想是在保持预训练模型权重不变的同时,通过在Transformer架构的每一层中引入可训练的低秩分解矩阵来实现模型的高效微调。LoRA高效的核心是AB矩阵尺寸远小于原矩阵W。计算公式如下:
y = (W + ηBA)x
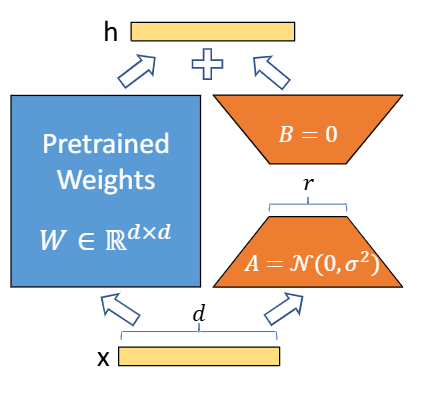
LoRA不仅显著减少了可训练参数的数量,降低了对硬件资源的需求,而且在模型推理时不引入任何额外的延迟。研究人员在RoBERTa、DeBERTa、GPT-2和GPT-3等多个模型上进行了广泛的实验,LoRA均能达到与FT相当的性能。
LoRA未来的研究方向是选择W矩阵的进一步研究,以及W矩阵本身的秩不足问题。
作者选择了矩阵加法(而大部分书籍主要介绍矩阵乘法,例如SVD),巧妙保留了W权重矩阵不动。
二、QLoRA
《QLORA:Efficient Finetuning of Quantized LLMs》提出了一种训练期间使用的新的数据类型NF4,占用显存小,这种量化训练技术可以大大减少LORA微调的内存需求。
三、DoRA
《DoRA: Weight-Decomposed Low-Rank Adaptation》研究表明,尽管LoRA因其简单有效而在参数高效微调(PEFT)方法中广受欢迎,但与FT相比,仍存在一定的容量差距。研究的挑战在于,在不增加额外推理成本的前提下,缩小PEFT方法与FT之间的性能差异。
研究内容包括提出了一种新颖的权重分解方法,该方法将预训练模型的权重分解为两个组成部分:大小(magnitude)和方向(direction)。这种分解基于权重归一化理论,通过将权重表示为大小向量和单位方向向量的乘积,使得模型权重的更新可以独立于其大小和方向进行。
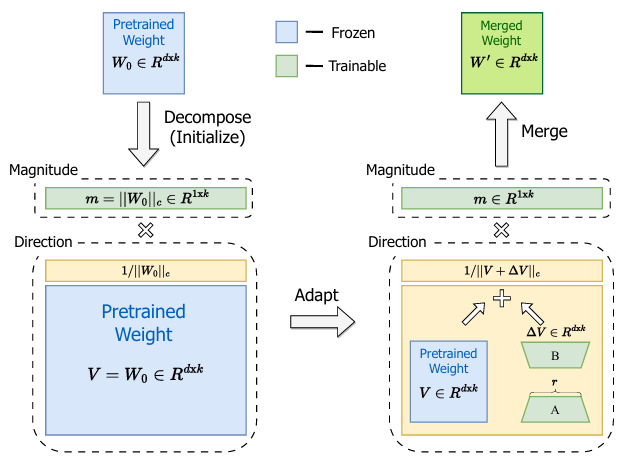
方向分量的更新采用了LoRA技术,通过两个低秩矩阵的乘积来近似方向的变化。这种更新方式的优势在于,它能够在保持参数数量较低的同时,对模型的方向分量进行有效的调整。
大小分量作为可训练参数,在微调过程中对其进行调整,以更好地适应下游任务。
在微调结束后,更新的方向分量和调整的大小分量可以合并回原始权重,确保模型在推理时不增加额外的延迟。通过这种权重分解和微调机制,DoRA方法旨在提高模型对下游任务的适应性,同时避免了全参数微调所带来的高昂代价,实现了在参数效率和模型性能之间的平衡。
四、GaLore
《GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection》
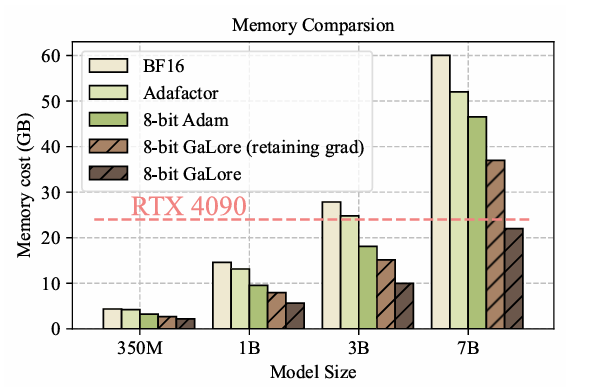
尽管LoRA引入低秩矩阵来降低权重(Weights)的显存,但优化器显存占用与Weights相当,训练时显存依然容易OOM。论文作者通过深入分析训练过程中优化器的梯度动态,首次证明了Weights的梯度矩阵在训练期间实际上展现出缓慢变化的低秩特性,这一发现为显存优化提供了新的视角。
基于这个理论,GaLore提出了一种创新的训练策略,即通过构建梯度的低秩投影来显著减少优化器的显存占用。具体来说,GaLore利用两个投影矩阵,将梯度矩阵有效映射至低维空间,实现了在不牺牲模型性能的前提下,大幅度降低显存需求。
GaLore不仅减少了优化器状态的显存,而且避免了全秩预热训练,实现了与FT相似的性能。
五、PiSSA
《PISSA: PRINCIPAL SINGULAR VALUES AND SINGULAR VECTORS ADAPTATION OF LARGE LANGUAGE MODELS》
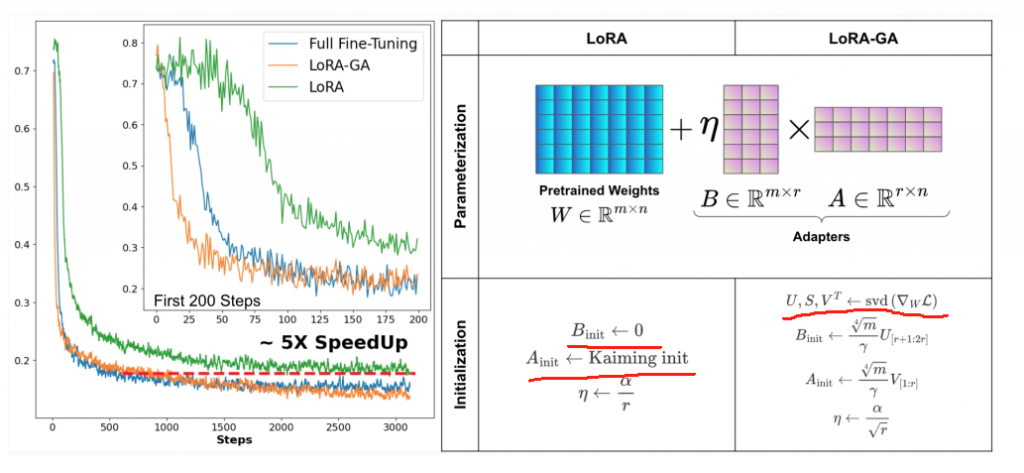
LoRA的研究重点是如何初始化矩阵A和B。一般来说,LoRA算法的矩阵A用高斯噪声,B用零初始化。
PiSSA方法的核心是用奇异值分解(SVD)技术对权重矩阵重构。将权重矩阵分解为三个矩阵的乘积:U、Σ和V^T。其中Σ包含了W的所有奇异值,代表了模型在不同方向上的拉伸程度,分解公式如下:
W=U Σ VT
PiSSA选择Σ中最大的r个向量,即主成分,用它们初始化矩阵A和B,而剩余的奇异向量Wres在微调中保持不变。根据SVD理论可知:A和B已经包含了W中最重要的信息,PiSSA能够快速收敛,性能优于LoRA。PiSSA可以无缝集成到原始模型中,无需对模型架构进行任何修改。
官方源码:PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models
默认微调fxmeng/PiSSA-Llama-3-8B-r128模型,24G内存跑不起来;而4bit量化微调fxmeng/PiSSA-Llama-3-8B-4bit-r128-5iter模型,微调需要20G显存。
六、LoRA-GA
《LoRA-GA: Low-Rank Adaptation with Gradient Approximation》
LoRA虽然减少了每次迭代的计算和内存需求,但相比于FT,其收敛速度较慢,最终整体计算成本增加,并且效果有时更差。LoRA-GA的核心在于梯度近似初始化,这种方法利用奇异值分解(SVD)对模型的梯度矩阵进行分析,从中提取出能够代表梯度主方向的低秩结构。通过这种方式,LoRA-GA能够在微调过程的第一步就使得低秩矩阵的更新方向与FT时保持一致,从而加速了模型的收敛。
官方源码: Outsider565/LoRA-GA
与PiSSA类似都使用了SVD,但它的优化目标不是W权重,是AB矩阵。LoRA-GA默认微调的是t5-base模型(参数量0.2B),需要的显存不到7G。