目录
可随意转载。Update2024.08.22
摘要
LoRA是一种广泛使用的PEFT方法。LoRA通过仅训练低秩的AB矩阵来节省内存。我们比较了LoRA和FT方法在编程和数学上的性能。考虑指令微调(约100K数据)和FT(约10B数据)数据规模。结果显示,在大多数设置中,LoRA在性能上明显落后于FT。但LoRA表现出了理想的正则化权重表示:它更好地保持了基础模型在out domain 的效果。LoRA比权重衰减(weight decay)、dropout等技术更强;它还有助于保持结果的多样化。FT的扰动(perturbations)秩比LoRA高10-100倍,我们还提出了LoRA的最佳实践。
一、引言
LLMs微调需要大量显存。PEFT方法通过冻结预训练的权重,仅训练少量参数(适配器)减少显存占用。LoRA本质是训练适配器作为预训练权重的低秩扰动。
LoRA一直标榜为一种严格的效率改进,不会影响下游任务的准确性。实际上,只有少数研究人员对具有数十亿参数的LLMs进行了LoRA与全参数微调的基准测试。其中一些研究依赖于旧模型(例如RoBERTa),或者粗略的评估基准(如GLUE或ROUGE),这显然不够。相比之下,更重要的评估(代码生成),揭示了LoRA不如FT。问题出现了:在哪些条件下,LoRA能够在像代码和数学这样具有挑战性的目标上接近FT的效果?
LoRA理论上被认为是正则化替代表示。另一个关键的问题是:相比FT,LoRA是否能减少遗忘?
…
结果表明,LoRA在代码生成上不如FT,但是在数学能力上与FT接近,而且LoRA训练效率低。尽管LoRA效果上有差距但是它遗忘少。此外,我们搞了一个“学习-遗忘”曲线来直观比较。
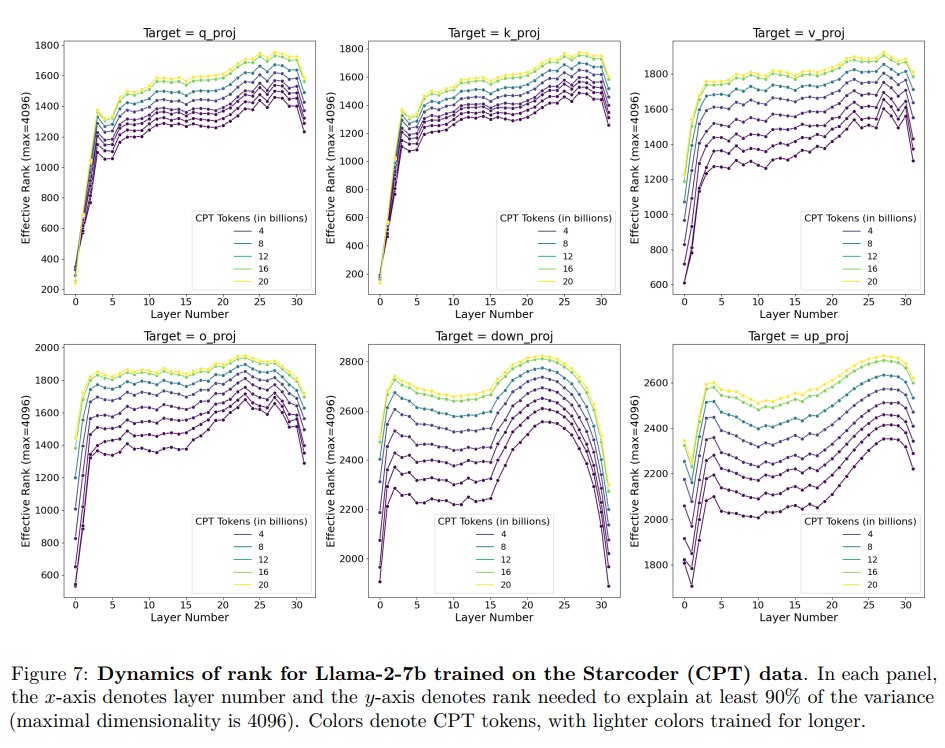
为什么LoRA比FT差?我们用SVD方法发现FT几乎没有改变基础模型权重矩阵的频谱(spectrum),但两者之间的差异(即扰动)是高秩的。扰动的秩随着训练的进展而增长,比典型的LoRA配置高出10-100倍(图7)。
我们最后提出了使用LoRA训练模型的最佳实践。我们发现LoRA对学习率特别敏感,性能主要受目标模块的选择影响,其次是秩。
论文的主要贡献:
• 在代码和数学领域,全参数微调比LoRA更准确、更高效(第4.1节)。
• LoRA的遗忘较少,是一种正则化表示(第4.2节和4.3节)。
• 与常见的正则化技术相比,LoRA的正则化更强;它还有助于保持生成的多样性(第4.4节)。
• 全参数微调发现了高秩的权重扰动(第4.5节)。
• 与全参数微调相比,LoRA对超参数更敏感,即学习率、目标模块和秩(按影响程度递减;第4.6节)。
四、 结论
4.1 LoRA在代码和数学问题上比FT差
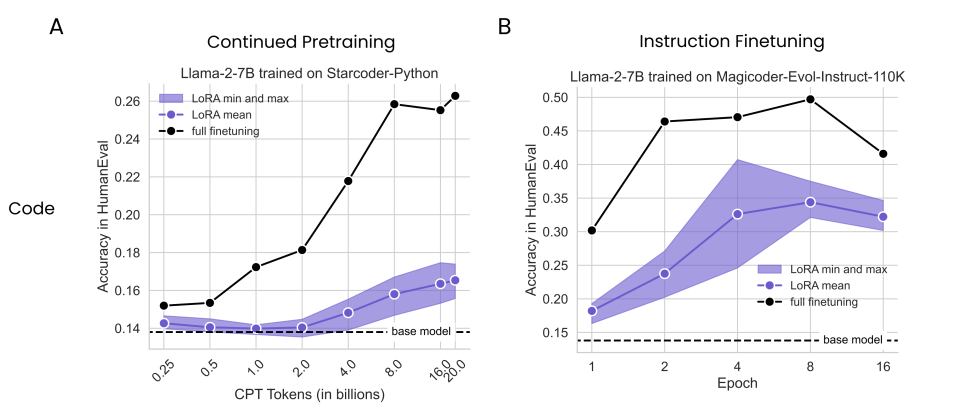
A图表示在持续Pretrain中,输入了16B的代码Tokens,在HumanEval测试中,LoRA也仅仅达到了0.175,远不如FT。
B图表示在指令微调中,运行了四个epoch达到了0.407;而FT在第二个epoch就达到了0.464。
同理,在数学问题上LoRA也有差距。
4.2 LoRA在代码和数学问题上比FT遗忘更少
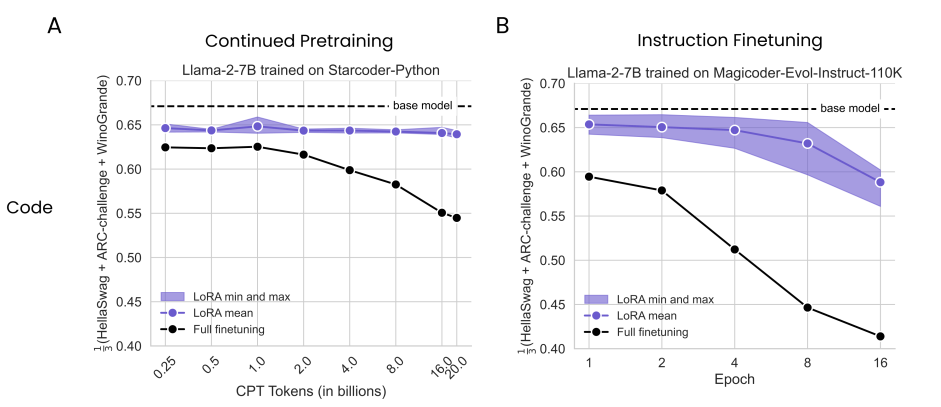
如图所示
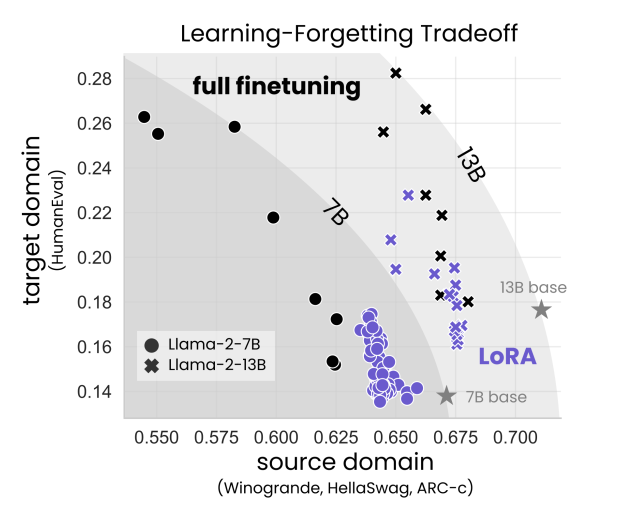
4.3 LoRA能否在学习能力和遗忘中平衡
LoRA能否在保持目标领域效果的同时,减少对源领域的遗忘?
通过实验提出了 Pareto frontiers 。通常来说,LoRA模型位于 Pareto frontiers 右下方——学得更少,遗忘得更少。
4.5 在代码和数学问题上做FT并未学习到低秩扰动
LoRA的低秩方法能近似FT方法吗?所需的秩是多大。
以Llama-2 7B为例,我们发现LoRA需要保留大约50%的SVD向量(大约2000 vs 4096)才能相当于90%的FT权重。至关重要的是,差分 Δ也具有与微调和FT相似的频谱。我们认为FT的频谱没有特殊性;通过向权重矩阵添加低幅度的高斯噪声也可以获得类似的频谱(见下图S7)。
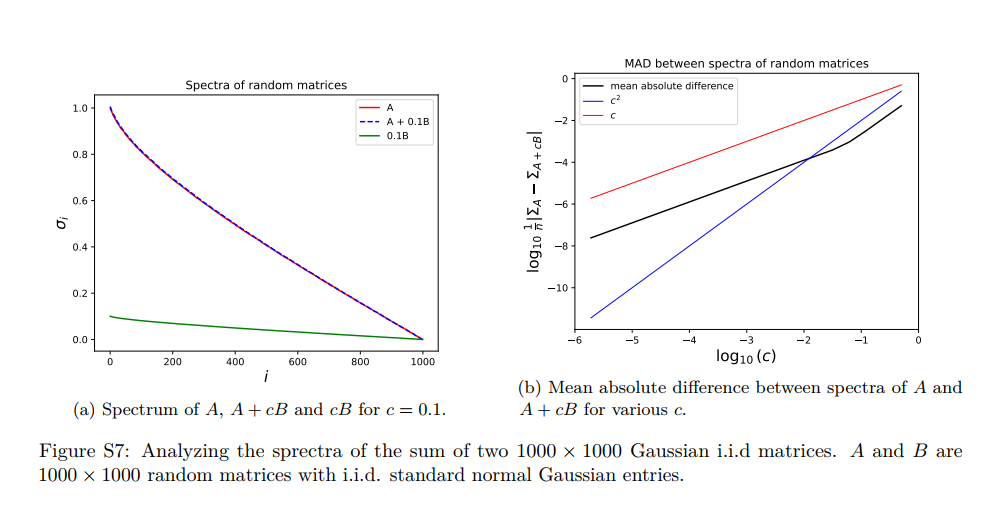
接下来,我们探讨了扰动训练的什么时间周期开始变得高秩,并询问它是否在模块类型和层之间有意义地变化。我们估计了解释矩阵90%方差所需的秩。结果出现在图7中。我们发现:
(1)最早的0.25B CPT标记的检查点显示 Δ 矩阵的秩比典型的LoRA秩大10-100倍;
(2)随着训练更多数据,Δ的秩增加;
(3)MLP模块的秩比注意力模块的秩高;
(4)第一层和最后一层似乎比中间层的秩低。