目录
Init 2024.12.16 Update 2025.05.24可随意转载
Paper1:RDAgent(2024)
一、研究背景
https://github.com/microsoft/RD-Agent
研究者常常阅读英文论文并进行编程验证来寻找潜在的研究方向,一般来说,这一过程工作负担较重。过去十年间,随着科学的发展,实验也越来越复杂,研究者阅读论文和编程验证的负担日益加剧,不利于从大量的论文中找出有价值的点。因此,自动化这一Reasearch & Development(R&D)流程变得很迫切。
二、研究框架和研究方法
2.1 研究框架

标签为“r”的模块根据预设的模板阅读文档,并生成任务(ModelTask)。
标签为’d’的模块共有两个部分:
- 组合任务、RAG、知识图谱等文字内容,与GPT-4对话,得到反馈和代码
- 根据反馈和代码部署docker运行环境,并评估它们。
2.2 研究方法
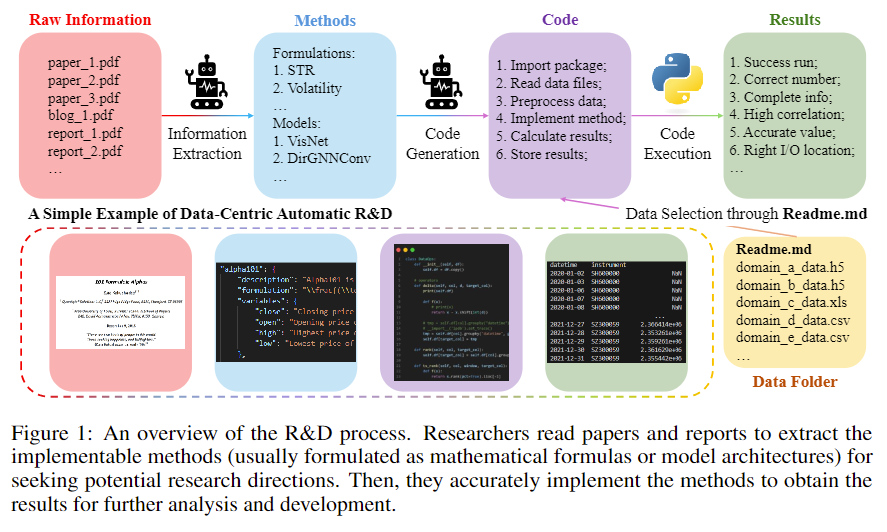
将pdf内容格式化为json,并生成研究代码,读取数据集,并通过多轮循环修改bug,提出假设,作出评价最终得到验证结果。
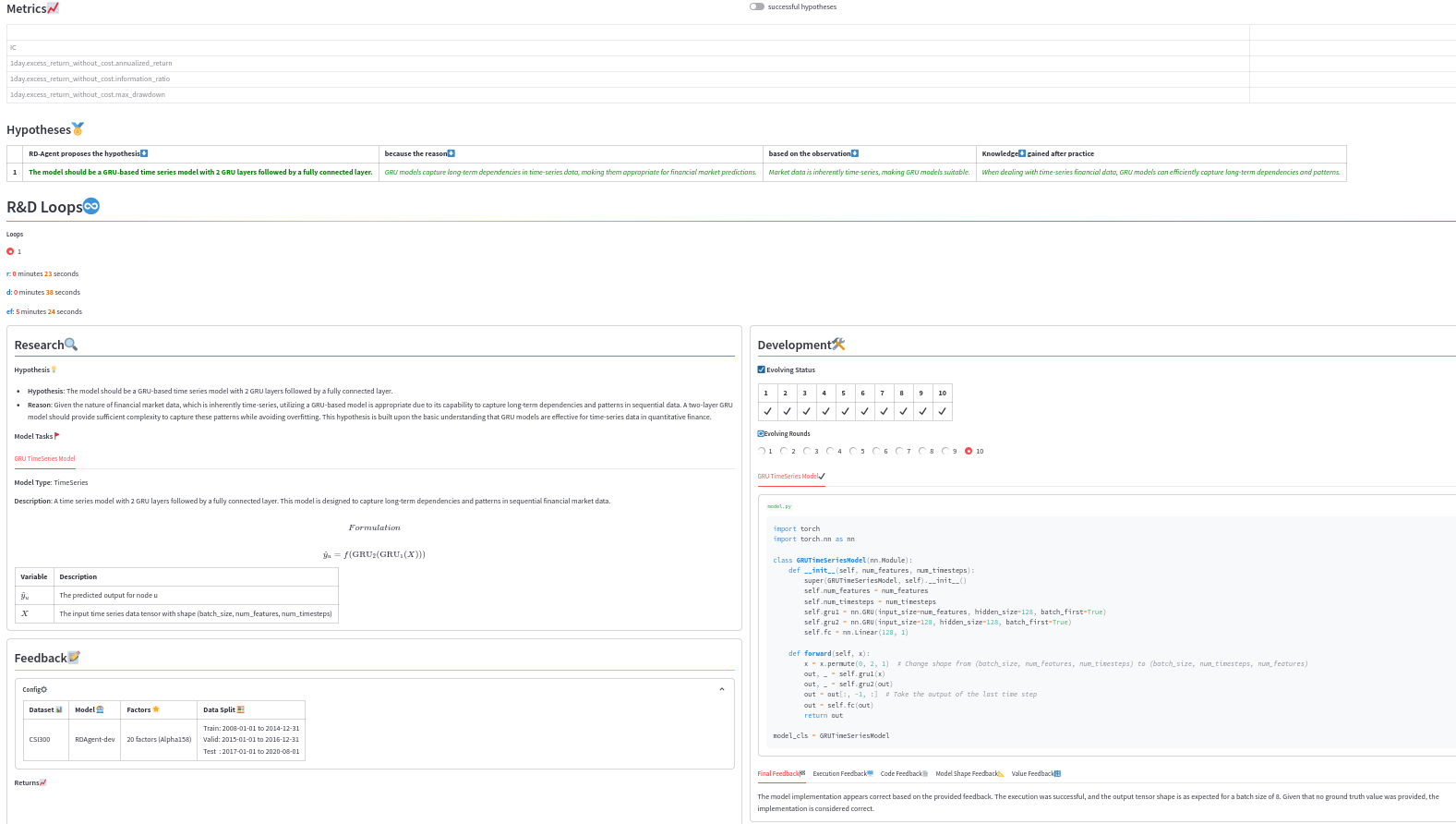
2.3 研究成果展示
fin_model
三、源码阅读
https://github.com/microsoft/RD-Agent
vscode运行配置如下:
{
"version": "0.2.0",
"configurations": [
{
"name": "Python:Algorithem",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/rdagent/app/cli.py",
"console": "integratedTerminal",
"args": [
"general_model", "https://arxiv.org/pdf/2210.09789"
],
"env": {
"PYTHONPATH": "${workspaceFolder}"
}
},
{
"name": "Python:fin_factor",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/rdagent/app/cli.py",
"console": "integratedTerminal",
"args": [
"fin_factor"
],
"env": {
"PYTHONPATH": "${workspaceFolder}"
}
},
{
"name": "Python:UI",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/rdagent/app/cli.py",
"console": "integratedTerminal",
"args": [
"ui"
],
"env": {
"PYTHONPATH": "${workspaceFolder}"
}
}
]
}3.1 general_model任务源码
任务目标:读取指定论文,并写出论文研究课题对应的代码,并且运行代码,评估代码的效果。
在rdagent/app/general_model/general_model.py文件中。
初始化代码(tag init):
with logger.tag("init"):
scenario = GeneralModelScenario()
logger.log_object(scenario, tag="scenario")主要是用来加载预先设定的prompt,是项目作这精挑细选的。
Reasearch部分代码(tag r):
with logger.tag("r"):
# Save Relevant Images
img = extract_first_page_screenshot_from_pdf(report_file_path)
logger.log_object(img, tag="pdf_image")
exp = ModelExperimentLoaderFromPDFfiles().load(report_file_path)
logger.log_object(exp, tag="load_experiment")用来提取pdf中的内容,并为了下一步模型使用,格式化成model_dict,代码如下:
# rdagent/components/coder/model_coder/task_loader.py
def load(self, file_or_folder_path: str) -> dict:
docs_dict = load_and_process_pdfs_by_langchain(file_or_folder_path) # dict{file_path:content}
model_dict = extract_model_from_docs(
docs_dict
) # dict{file_name: dict{model_name: dict{description, formulation, variables}}}
model_dict = merge_file_to_model_dict_to_model_dict(
model_dict
) # dict {model_name: dict{description, formulation, variables}}
return ModelExperimentLoaderFromDict().load(model_dict)再次转换格式为ModelTask:
# rdagent/components/coder/model_coder/task_loader.py
def load(self, model_dict: dict) -> list:
"""Load data from a dict."""
task_l = []
for model_name, model_data in model_dict.items():
task = ModelTask(
name=model_name,
description=model_data["description"],
formulation=model_data["formulation"],
architecture=model_data["architecture"],
variables=model_data["variables"],
hyperparameters=model_data["hyperparameters"],
model_type=model_data["model_type"],
)
task_l.append(task)
return QlibModelExperiment(sub_tasks=task_l)Development部分代码(tag d):
Co-STEER(Collaborative Knowledge-STudying-Enhanced Evolution by Retrieval)是论文的核心方法,这个方法是一个基于大型语言模型(LLMs)的自主代理策略。根据我的理解,这个核心方法有几个关键内容:
- 知识库:可以是预先输入的,也可以是过程中自动生成的(包含正确和错误的知识),且包含生成知识轨迹(叠加所有的知识,提示词的token消耗很多)。因此知识库是自进化的。
- RAG:从子任务生成的知识轨迹中用大模型向量搜索找到similar_successful_knowledge
- 进化代理:基于LLM的智能体代理,根据知识(包含正确和错误)生成code。(使用了scenario中的提示词作为system_prompt)
- 反馈:把code放入子工作空间(docker)中做多种评估测试(包含:shape,value,ModelCodeEvaluator,ModelFinalEvaluator)。其中后两个评估器会与LLM交互并获得LLM的反馈(feedback),根据反馈中的final_decision决定是否继续进化(evolve)
- filter_final_evo:这个参数?? TODO
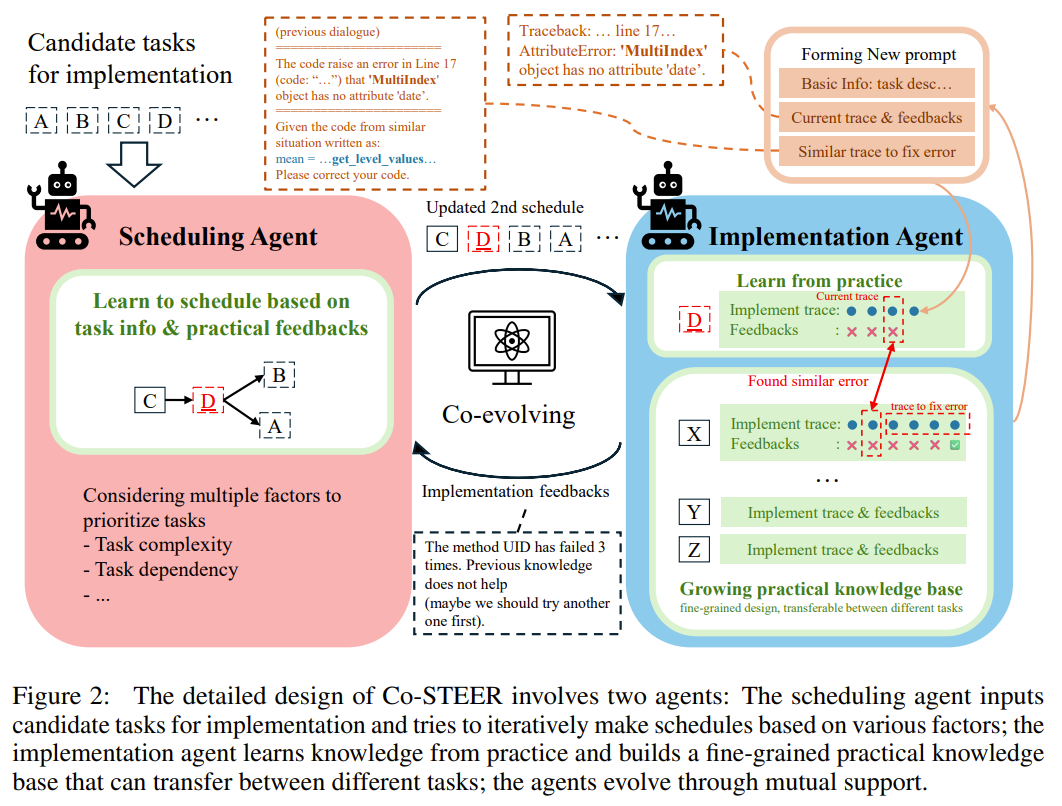
先执行初始化。其中,类QlibModelCoSTEER是上述Co-STEER方法的封装。
with logger.tag("d"):
exp = QlibModelCoSTEER(scenario).develop(exp)
logger.log_object(exp, tag="developed_experiment")# 2024-12 更新
from rdagent.components.coder.model_coder import ModelCoSTEER
QlibModelCoSTEER = ModelCoSTEERModelCoSTEER的初始化代码如下:
# rdagent/components/coder/model_coder/CoSTEER/__init__.py
初始化参数:max_loop,knowledge_base_path,new_knowledge_base_path,with_knowledge,with_feedback,knowledge_self_gen,filter_final_evo,evolving_strategy,model_evaluator# 2024-12 更新
# rdagent/components/coder/model_coder/__init__.py
class ModelCoSTEER(CoSTEER):
def __init__(
self,
scen: Scenario,
*args,
**kwargs,
) -> None:
# 定义评估器
eva = CoSTEERMultiEvaluator(ModelCoSTEEREvaluator(scen=scen), scen=scen)
# 定义算法进化策略类
es = ModelMultiProcessEvolvingStrategy(scen=scen, settings=CoSTEER_SETTINGS)
super().__init__(*args, settings=CoSTEER_SETTINGS, eva=eva, es=es, evolving_version=2, scen=scen, **kwargs)
最后调用超类CoSTEER的初始化方法,如下:
# 2024-12 更新
# 初始化知识库和RAG:
# rdagent/components/coder/CoSTEER/__init__.py
......
# init knowledge base
# 默认使用CoSTEERKnowledgeBaseV2
self.knowledge_base = self.load_or_init_knowledge_base(
former_knowledge_base_path=self.knowledge_base_path,
component_init_list=[],
)
# init rag method
self.rag = (
CoSTEERRAGStrategyV2(self.knowledge_base, settings=settings)
if self.evolving_version == 2
else CoSTEERRAGStrategyV1(self.knowledge_base, settings=settings)
)初始化知识库:CoSTEERKnowledgeBaseV2,完成了self.graph(类型:UndirectedGraph)的初始化。2024-12 更新
# 2024-12 更新
class CoSTEERKnowledgeBaseV2(EvolvingKnowledgeBase):
def __init__(self, init_component_list=None, path: str | Path = None) -> None:
"""
Load knowledge, offer brief information of knowledge and common handle interfaces
"""
self.graph: UndirectedGraph = UndirectedGraph(Path.cwd() / "graph.pkl")
logger.info(f"Knowledge Graph loaded, size={self.graph.size()}")
if init_component_list:
for component in init_component_list:
exist_node = self.graph.get_node_by_content(content=component)
node = exist_node if exist_node else UndirectedNode(content=component, label="component")
self.graph.add_nodes(node=node, neighbors=[])初始化RAG:CoSTEERRAGStrategyV2。它包含了特定的generate_knowledge和query方法实现!2024-12 更新
初始化所有流程到此结束。
接下来再将ModelTask的封装传入执行develop方法,方法中调用multistep_evolve方法,执行下面的代码:2024-12 更新
for _ in tqdm(range(self.max_loop), "Implementing"):
# 1. knowledge self-evolving
if self.knowledge_self_gen and self.rag is not None:
self.rag.generate_knowledge(self.evolving_trace)
# 2. RAG
queried_knowledge = None
if self.with_knowledge and self.rag is not None:
# TODO: Putting the evolving trace in here doesn't actually work
queried_knowledge = self.rag.query(evo, self.evolving_trace)
# 3. evolve
evo = self.evolving_strategy.evolve(
evo=evo,
evolving_trace=self.evolving_trace,
queried_knowledge=queried_knowledge,
)
...
return evomultistep_evolve方法第一、二步,根据evolving_trace实现RAG知识库的进化。
其中RAG类实例(ModelRAGStrategy)在knowledge_management.py文件中,RAG实现类CoSTEERRAGStrategyV2,包含两个重要方法:generate_knowledge和query。
第一步 RAG-generate_knowledge
2024-12 更新
# 从进化轨迹(evolving_trace)中循环遍历evo_step,并提取其中的可进化主题(evolvable_subjects)重命名名为implementations + 反馈(feedback)。
# 遍历implementations的子任务(sub_tasks),并为每个子任务生成知识。
# 对于每个子任务,获取任务信息(target_task_information),实现(implementation),以及对应的反馈(single_feedback,类型为CoSTEERSingleFeedback)。
# 如果single_feedback为None,则跳过当前循环。否则,创建一个ModelKnowledgeCoSTEERKnowledge对象,包含target_task、implementation和feedback。
# 检查target_task_information是否已存在于success_task_info_set success_task_to_knowledge_dict中。如果不存在,将新的知识添加到知识库的轨迹中(implementation_trace)working_trace_knowledge,并根据feedback的最终决策(final_decision)设置success_task_to_knowledge_dict同时更新成功任务信息集。如果最终决策是False,则生成错误分析知识图谱node,并将其添加到working_trace_error_analysis中。
# 更新当前生成的轨迹计数: 最后,将当前已生成的轨迹计数更新为传入的进化轨迹的长度。更新状态:将self.current_generated_trace_count更新为evolving_trace的长度,表示已处理完所有可用的EvoStep对象。
def generate_knowledge(
self,
evolving_trace: list[EvoStep],
*,
return_knowledge: bool = False,
) -> Knowledge | None:第二步 RAG-query
# 取参数query_former_trace_limit:查询先前轨迹的限制;query_similar_success_limit:查询相似成功任务的限制;fail_task_trial_limit:任务失败尝试的限制
# 遍历 evo.sub_tasks 中的每个子任务
# 如果任务信息存在于 知识库的success_task_info_set 中,则将该任务信息及其对应的最后一条知识轨迹添加到 queried_knowledge.success_task_to_knowledge_dict 中。
# 如果任务信息不存在于成功任务集合中,并且该任务在 知识库的implementation_trace 中的尝试次数已达到或超过 fail_task_trial_limit,则将该任务信息添加到 queried_knowledge.failed_task_info_set 中。
# 对于既不是成功也不是失败的任务,将最后 query_former_trace_limit 条轨迹添加到 queried_knowledge.working_task_to_former_failed_knowledge_dict 中。
计算当前任务信息与成功任务信息集合之间的嵌入距离(相似性)。
根据相似性排序并选择前 query_similar_success_limit 个最相似的成功任务。
将这些相似成功任务的最后一条知识轨迹添加到 queried_knowledge.working_task_to_similar_successful_knowledge_dict 中。
def query(
self,
evo: EvolvableSubjects,
evolving_trace: list[EvoStep],
) -> QueriedKnowledge | None:2024-12 更新
# 配置知识采样器
# 创建一个CoSTEERQueriedKnowledgeV2的实例queried_knowledge_v2
# queried_knowledge_v2更新3步
def query(self, evo: EvolvableSubjects) -> CoSTEERQueriedKnowledge | None:
...
# 1 迭代sub_tasks,处理进化轨迹中记录的过去知识,填充query_knowledage的task的过去失败轨迹记录。
queried_knowledge_v2 = self.former_trace_query(...
# 2 组件分析(analyze_component)组织提示词与GPT-4对话,生成当前任务的知识图谱
# 基于约束条件(constraint_labels=["task_description"]或者["task_success_implement"])分析知识图谱中节点交叉,使用文字向量相似度方法找到相似成功知识的嵌入。
# 然后采样 GT(ground-truth)和非GT知识列表。
# 最后填充query_knowledage的task的相似成功任务知识。
queried_knowledge_v2 = self.component_query(...
# 3 类似上一步把same_error_success_knowledge_pair_list填充到query_knowledage,增强GPT-4对负面知识的了解
queried_knowledge_v2 = self.error_query(...
点评:策略(strategy)的基本思路是通过多轮的GPT-4对话获取成功和失败的经验。算法的复杂点在于第2步,把成功的知识用知识图谱表示并计算相似度。这导致代码可读性差。
然后第三步:evolve会调用evolving_strategy.py文件中的implement_one_model方法,构造上下文并和GPT-4的对话:
# rdagent/components/coder/model_coder/CoSTEER/evolving_strategy.py
def implement_one_model(...):
model_information_str = target_task.get_task_information()
model_type = target_task.model_type
...
queried_former_failed_knowledge_to_render = queried_former_failed_knowledge
system_prompt = (...)
...
for _ in range(10): # max attempt to reduce the length of user_prompt
user_prompt = (...)
...
code = json.loads(
APIBackend(use_chat_cache=MODEL_IMPL_SETTINGS.coder_use_cache)
.build_messages_and_create_chat_completion(
user_prompt=user_prompt,
system_prompt=system_prompt,
json_mode=True,
),
)["code"]
return code第四步,把queried_knowledge打包成es(EvoStep),用来评估。
第五步,建立docker镜像并把代码插入进入,然后运行镜像评估GPT-4编写的代码正确与否:
# 4. Pack evolve results
es = EvoStep(evo, queried_knowledge)
# 5. Evaluation
if self.with_feedback:
es.feedback = (
eva
if isinstance(eva, Feedback)
else eva.evaluate(evo, queried_knowledge=queried_knowledge)
)
logger.log_object(es.feedback, tag="evolving feedback")3.2 fin_factor任务源码
任务目标:持续挖掘金融量化因子。
rdagent/app/qlib_rd_loop/factor.py中的代码:
def main(path=None, step_n=None):
"""
自动进行金融科技的研发迭代循环
"""
if path is None:
model_loop = FactorRDLoop(FACTOR_PROP_SETTING)
else:
model_loop = FactorRDLoop.load(path)
model_loop.run(step_n=step_n)其中FactorRDLoop初始化调用了RDLoop类的__init__方法,初始化了下面变量:
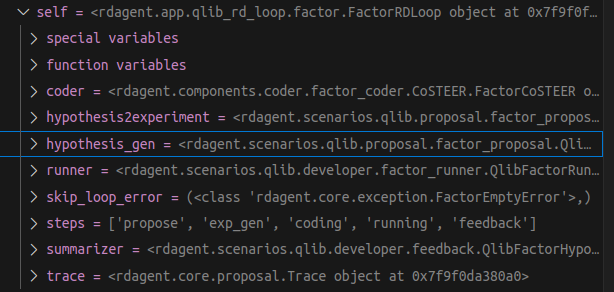
其中run方法会按照steps里面定义的workflow各个阶段逐一执行。
def run(self, step_n: int | None = None):
with tqdm(total=len(self.steps), desc="Workflow Progress", unit="step") as pbar:
while True:
...
# 取出每个step的名字,通过名字动态调用对应的方法。
name = self.steps[si]
func = getattr(self, name)
try:
self.loop_prev_out[name] = func(self.loop_prev_out)
except self.skip_loop_error as e:按设定好的workflow:[‘propose’, ‘exp_gen’, ‘coding’, ‘running’, ‘feedback’] 执行对应的代码:
@measure_time
def propose(self, prev_out: dict[str, Any]):
with logger.tag("r"): # research
hypothesis = self.hypothesis_gen.gen(self.trace)
logger.log_object(hypothesis, tag="hypothesis generation")
return hypothesis
@measure_time
def exp_gen(self, prev_out: dict[str, Any]):
with logger.tag("r"): # research
exp = self.hypothesis2experiment.convert(prev_out["propose"], self.trace)
logger.log_object(exp.sub_tasks, tag="experiment generation")
return exp
@measure_time
def coding(self, prev_out: dict[str, Any]):
with logger.tag("d"): # develop
exp = self.coder.develop(prev_out["exp_gen"])
logger.log_object(exp.sub_workspace_list, tag="coder result")
return exp
@measure_time
def running(self, prev_out: dict[str, Any]):
with logger.tag("ef"): # evaluate and feedback
exp = self.runner.develop(prev_out["coding"])
logger.log_object(exp, tag="runner result")
return exp
@measure_time
def feedback(self, prev_out: dict[str, Any]):
feedback = self.summarizer.generate_feedback(prev_out["running"], prev_out["propose"], self.trace)
with logger.tag("ef"): # evaluate and feedback
logger.log_object(feedback, tag="feedback")
self.trace.hist.append((prev_out["propose"], prev_out["running"], feedback))比如propose阶段的GPT-4上下文简化如下:
[
{
"role": "system",
"content": "用户正在为数据驱动的量化投资研究开发假设,这些因子用于解释投资组合或单一资产的回报和风险。因子帮助识别超额回报,并是量化策略的核心。用户的模型将基于过去的因子值预测未来几天的回报。每个因子包含:1) 名称,2) 描述,3) 公式,4) 变量。每个因子定义静态输出和固定数据源。例如,10天和20天的动量应视为不同因子。数据源包括 daily_pv.h5,包含一段时间内的股票价格和成交量数据。\n\n代码接口应包括:导入部分、函数部分和主函数部分,主函数命名为 calculate_{function_name}。Python代码应将因子值保存为 result.h5 文件,文件内容为一个按日期和股票代码索引的 pandas DataFrame。用户将使用 Qlib 进行模型训练和投资组合评估。用户已提出一些假设,任务是验证并改进这些假设。开始时因子应简单,之后逐步增加复杂度,每次生成 1-3 个因子。确保每个假设符合给定的指引。\n\n输出格式:JSON,包含假设、推理、简明理由、观察、论证和知识等信息。"
},
{
"role": "user",
"content": "生成推理和提炼知识的相关键,特别是在领域特定的背景下解释,而非泛泛的理论知识。"
}
]比如exp_gen阶段的GPT-4上下文简化如下:
[{
"role": "system",
"content": "用户生成因子用于量化投资,关注组合的回报与风险。因子用于训练模型,基于过去的数据预测回报。因子包含名称、描述、公式和变量。每个因子定义一个输出,使用特定的数据集。数据包括每日的价格和成交量(开盘价、收盘价、最高价、最低价、成交量、因子值)以HDF5格式存储。Python代码应计算并将因子结果保存到一个HDF5文件,文件中使用日期时间和证券代码作为索引,因子值作为唯一列。Qlib将用于评估和基于因子构建投资组合。输出格式为JSON,包含因子的详细信息。"
}, {
"role": "user",
"content": "生成因子的目标假设是:引入一个30日的MACD因子,基于12日和26日指数加权移动平均(EMA)收盘价的差值。MACD有助于识别短期动量和趋势变化,是未来价格走势的有效预测指标。简洁知识:MACD结合短期和长期EMA,能够信号未来价格变化的方向。"
}]
比如coding阶段的GPT-4上下文简化如下:
[
{
"role": "system",
"content": "用户正在实现量化投资中的因子,因子用于解释资# 4. Pack evolve results
es = EvoStep(evo, queried_knowledge)产或投资组合的回报与风险。用户将基于前几天的因子值训练模型预测未来几天的回报。因子包括名称、描述、公式和变量,可能不完全包含所有部分。因子应静态定义一个输出和数据源。代码需按照给定接口格式编写,并保存结果为HDF5文件。输出的DataFrame包含时间戳和证券代码,因子值为数据列。"
},
{
"role": "user",
"content": "目标因子:MACD_30,描述:基于12日与26日指数移动平均(EMA)差值的30日MACD,用于预测未来回报。公式:MACD_{30} = EMA_{12}(Close) - EMA_{26}(Close)。变量:EMA_{12}为12日EMA,EMA_{26}为26日EMA,Close为收盘价。"
}
]coding包括子阶段:evolve,它GPT-4上下文简化如下:
[
{
"role": "system",
"content": "用户正在实现量化投资中的因子。因子用于解释资产或投资组合的回报和风险,帮助识别超额回报来源,是量化策略的核心。每个因子在特定日期对一个工具产生物理值。用户将训练模型,基于历史因子值预测未来回报。因子包括:名称、描述、公式和变量,并指定如窗口大小和回溯期等超参数。不同的因子应基于静态数据计算,例如‘过去10天的动量’和‘过去20天的动量’应作为不同的因子。源数据为 daily_pv.h5,包含多个工具的每日价格和因子值。结果应保存在 ‘result.h5’ 文件中。用户的代码将计算因子值并保存为 HDF5 格式,以便后续在 Qlib 中进行模型训练,预测回报并评估投资组合表现。"
},
{
"role": "user",
"content": "目标因子信息:因子名称:Signal_Line_9。描述:MACD的9日信号线,用于平滑值并识别买卖信号。公式:Signal_{9} = EMA_{9}(MACD_{30})。变量:EMA_{9}为MACD的9日指数移动平均,MACD_{30}为30日MACD。"
}
]
之后,它会调用FactorEvolvingStrategyWithGraph类中的方法implement_one_factor,而这个方法的GPT-4上下文简化如下:
[
{
"role": "system",
"content": "用户正在为量化投资实现因子。因子帮助解释投资组合的收益和风险。用户将训练模型,根据历史因子预测收益。每个因子包括名称、描述、公式和变量。因子应具有窗口大小和回溯期等超参数。数据来源是'daily_pv.h5'文件。用户编写代码计算因子值并保存在'result.h5'文件中。代码需遵循接口,生成因子、训练模型、评估投资组合表现,使用Qlib平台进行。"
},
{
"role": "user",
"content": {
"factor_name": "MACD_Histogram",
"factor_description": "MACD柱状图,衡量MACD与信号线之间的距离。",
"factor_formulation": "MACDHist = MACD_{30} - Signal_{9}",
"variables": {
"MACD_{30}": "30日移动平均收敛/发散指标。",
"Signal_{9}": "MACD的9日信号线。"
}
}
}
]coding包括子阶段:evaluate(多个),它GPT-4上下文简化如下:
{
"背景": {
"描述": "用户正在实现量化投资中的因子,用于根据因子值预测资产的回报。因子由名称、描述、公式和变量定义,帮助解释投资组合或单一资产的回报和风险。",
"数据格式": {
"类型": "HDF5",
"列": ["$open", "$close", "$high", "$low", "$volume", "$factor"],
"数据": "调整后的每日价格和成交量数据,使用多重索引: (datetime, instrument)"
},
"任务": {
"模型": "基于因子值训练模型来预测回报。",
"文件": "result.h5",
"输出格式": "DataFrame,使用多重索引(datetime, instrument),单列存储因子值。"
}
},
"接口": {
"python代码": "代码必须包含导入部分、函数部分和主函数部分,主函数名为 'calculate_{function_name}',并将输出保存到 'result.h5'。",
"要求": "因子的计算应针对特定周期,比如 '过去10天动量' 和 '过去20天动量' 应定义为不同因子。"
},
"因子数据": {
"示例输出": {
"数据框": {
"多重索引": "(Timestamp, 'instrument')",
"列": "因子名称(单列)",
"数据类型": "float64"
},
"模拟": "因子用于在Qlib中训练模型,预测回报、管理投资组合并评估性能。"
}
},
"用户状态": {
"任务": "用户正在处理与某个特性相关的任务。",
"输出示例": {
"数据框信息": {
"多重索引": "48700条记录,(Timestamp('2018-01-02 00:00:00'), 'SH000300') 到 (Timestamp('2019-12-31 00:00:00'), 'SH600121')",
"列": "MACD_30",
"非空计数": 48548,
"数据类型": "float64"
}
}
}
}
running阶段不会调用GPT-4,它会创建docker并运行
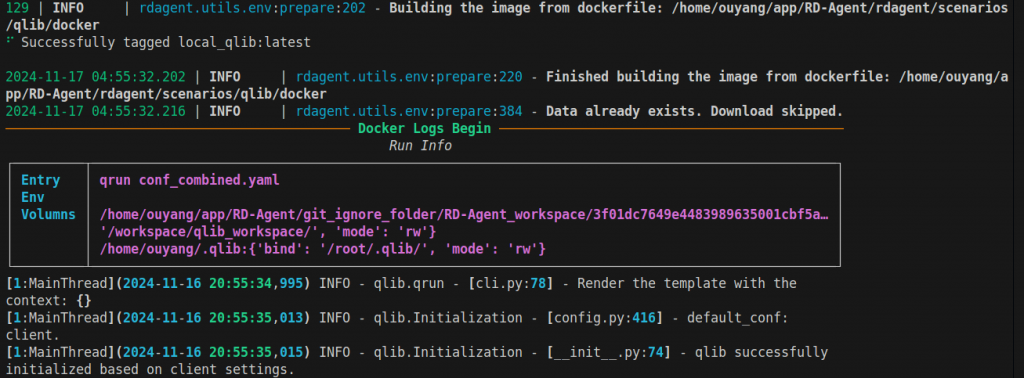
比如feedback阶段的GPT-4上下文简化如下:
{
"Observations": "新因子(MACD_30、Signal_Line_9 和 MACD_Histogram)在年化回报和信息比率上优于 SOTA,但最大回撤有所恶化。IC 值在当前和 SOTA 结果之间相似。",
"Feedback for Hypothesis": "使用 30 天 MACD 预测未来回报的假设得到了支持,因为这些因子在年化回报和信息比率上表现出色。然而,较高的最大回撤表明在降低风险方面仍需进一步优化。",
"New Hypothesis": "通过整合波动率调整的移动平均线或加入额外的平滑技术来优化 MACD 因子,以在降低风险的同时保持高回报。",
"Reasoning": "尽管年化回报和信息比率有所提升,但较高的最大回撤表明风险管理需要改进。通过对 MACD 加入波动率调整或平滑方法,可以在不牺牲回报的情况下减少风险。",
"Replace Best Result": "yes"
}
四、代码复现
论文部分内容依赖qlib库,而这个qlib库创建已经有三年时间,很复杂。因此,我从论文源码中提取了阅读PDF部分的代码(general_model),简单修改后,可复现成功论文效果。
4.x 异常问题总结
例如一、LLM返回的格式错误,报KeyError:
...
Please response the critic in the json format. Here is an example structure for the JSON output, please strictly follow the format:
{
"final_decision": True,
"final_feedback": "The final feedback message",
}
Role:user
Content: --------------Model information:---------------
name: Anti-Symmetric Deep Graph Network (A-DGN)
description: A framework for stable and non-dissipative Deep Graph Network (DGN) design, conceived through the lens of ordinary differential equations (ODEs). This approach mitigates the over-squashing phenomena in DGNs, enabling effective propagation and preservation of long-term node dependencies.
formulation: \frac{\partial x_u(t)}{\partial t} = \sigma\left((W - W^T - \gamma I)x_u(t) + \Phi(X(t), N_u) + b\right)
architecture: The architecture consists of multiple layers derived from the forward Euler discretization of the ODE. Each layer updates the node states iteratively, preserving long-term dependencies through anti-symmetric weight matrices. The generic form of the update function for each layer is x^l_u = x^{l-1}_u + \epsilon \sigma((W - W^T - \gamma I)x^{l-1}_u + \Phi(X^{l-1}, N_u) + b), where l denotes the layer index.
variables: {'\\hat{y}_u': 'The predicted output for node u', 'x_u(t)': 'The state of node u at time t', 'W': 'A weight matrix', 'b': 'A bias vector', '\\sigma': 'A monotonically non-decreasing activation function', '\\Phi(X(t), N_u)': 'The aggregation function for states of nodes in the neighborhood of u', 'N_u': 'The set of neighboring nodes of node u', 'I': 'The identity matrix', '\\gamma': 'A hyper-parameter for diffusion', '\\epsilon': 'The discretization step size'}
hyperparameters: {'learning_rate': '10^{-3}', 'weight_decay': '10^{-6}', 'number_of_layers': '1, 5, 10, 20', 'embedding_dimension': '10, 20, 30', 'activation_function': 'tanh', 'epsilon': '1, 10^{-1}, 10^{-2}, 10^{-3}', 'gamma': '1, 10^{-1}, 10^{-2}, 10^{-3}'}
model_type: Graph
--------------Model Execution feedback:---------------
Execution error: [Errno 2] No such file or directory: '/home/ouyang/app/SimpleAgent/model_execute_template_v1.txt'
Traceback: Traceback (most recent call last):
File "/home/ouyang/app/SimpleAgent/model.py", line 113, in execute
{(Path(__file__).parent / 'model_execute_template_v1.txt').read_text()}
File "/home/ouyang/anaconda3/envs/RDAgent/lib/python3.10/pathlib.py", line 1134, in read_text
with self.open(mode='r', encoding=encoding, errors=errors) as f:
File "/home/ouyang/anaconda3/envs/RDAgent/lib/python3.10/pathlib.py", line 1119, in open
return self._accessor.open(self, mode, buffering, encoding, errors,
FileNotFoundError: [Errno 2] No such file or directory: '/home/ouyang/app/SimpleAgent/model_execute_template_v1.txt'
--------------Model Code feedback:---------------
critic 1: The provided code includes a main function which attempts to save the output tensor to a file named "output.pth". However, the main function is not required as per the instructions.
critic 2: The forward method of the ADGNModel is correct in terms of processing the node features through the layers, but the final output should be reshaped to (batch_size, 1) directly instead of using mean. Ensure the output tensor shape is (batch_size, 1).
critic 3: The initialization of model_cls in the main function does not provide correct parameters as per the user's testing scenario. The user will initialize the graph model with `model = model_cls(num_features=num_features)`.
critic 4: The code tries to read a non-existent file `model_execute_template_v1.txt`, which is unrelated to the task of defining the model and should be removed. This is causing the execution error.
Suggestions:
1. Remove the main function and related code that saves the output tensor.
2. Ensure the forward method of ADGNModel reshapes the output to (batch_size, 1).
3. Ensure model_cls is initialized correctly as per the user's scenario.
4. Remove any extraneous code that attempts to read non-existent files or perform unrelated operations.
--------------Model value feedback:---------------
No output generated from the model. Skip value evaluation
2024-11-24 17:21:31.944 | INFO | oai.llm_utils:_create_chat_completion_inner_function:681 - Response:
{
"final the final_decision": false,
"final_feedback": "The provided model implementation has several in terms of modeling errors and extraneous file access code. Specifically, the main function should be removed as virtual work. Additionally at the critic points. The forward method needs to be corrected to reshape the output tensor to (batch_size, 1). in our model_cls initialization. Additionally as below's expected the final method as described. The non-existent file access code should be removed to fix the FileNotFoundError. Please update the model code accordingly."
}这是正常的,通常需要编写代码来容错,因为LLM不能100%保证跟随指令。
Paper2:RDAgent(Q)(2025)
一、研究内容
金融市场是高维度、非线性的动态复杂系统,它的研究正在从经验驱动向数据驱动转变。股票量化交易流程分成2大组成部分:
- 因子挖掘(facor mining)
- 模型开发(model innovation)
https://arxiv.org/abs/2505.15155
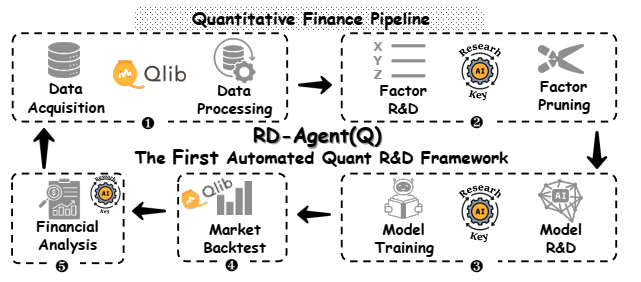
论文提出了研究内容RDAgent(Q):以数据为中心的多智能体框架,包含5个阶段:Specification, Synthesis , Implementation, Validation, Analysis。
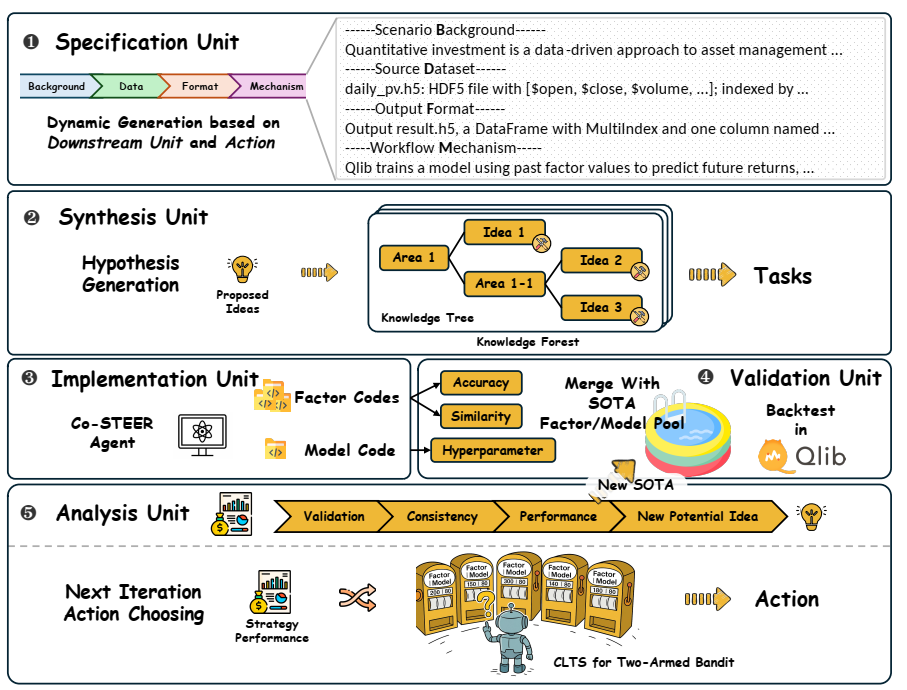
- Specification 形式化定义与统一接口,减少了组件间的歧义
- Synthesis 假设+实验,生成轨迹和经验;再假设+实验,以此类推,生成SOTA的解决方案,最后生成task为后续code做准备
- Implementation 将可执行任务转化为功能代码,论文提出了智能体Co-STEER,引入了知识库
- Validation 评估上一步生成的因子或模型的实际有效性。因子用qlib回测,模型也有类似回测流程
- Analysis 每次实验轮次后,它对当前假设 、特定任务 和实验结果 进行多维度评估。Analysis仅关注当前实验的局部视图,而Synthesis则维护对整个实验历史的全局视图。
二、实验部分
数据集:采用CSI 300 数据集,涵盖中国市场上 300 支大盘 A 股。时间跨度分为训练集(2008 年 1 月 1 日至 2014 年 12 月 31 日)、验证集(2015 年 1 月 1 日至 2016 年 12 月 31 日)和测试集(2017 年 1 月 1 日至 2020 年 8 月 1 日)。
对比基线:因子:Alpha 101、Alpha 158、Alpha 360 和 AutoAlpha;模型:机器学习模型(如线性模型、MLP、LightGBM 等)和深度学习模型(如 GRU、LSTM、Transformer 等)
评估方法:因子预测指标(包括信息系数 IC、IC 信息比率 ICIR、排名 IC 和排名 ICIR)以及策略性能指标(包括年化回报率 ARR、信息比率 IR、最大回撤 MDD 和卡尔马比率 CR)
主要结果
- RD-Factor(因子优化):RD-FactorGPT-4o和RD-Factoro3-mini在使用更少手工因子的情况下,超越了静态因子库(如Alpha 158/360),实现了更高的IC(高达0.0497)和显著提升的ARR(高达14.61%)。
- RD-Model(模型优化):固定因子进行模型优化时,RD-Modelo3-mini在基线中表现最佳,Rank IC达到0.0546,MDD为-6.94%。机器学习模型表现显著落后,凸显了其在捕捉金融市场噪声和非线性模式方面的局限性。有趣的是,时间序列预测模型(如PatchTST、Mamba)在两方面均表现不佳,显示出标准序列预测与股市动态之间存在根本性不匹配。专门的股票预测模型(如TRA、MASTER)在策略指标上表现优异,但在预测能力上落后,突出了稳健性(低MDD、高IR)与精确性(高IC)之间的权衡。结论是自适应模型配置,比机器学习和手工深度学习架构生成了更稳健、更敏感风险的预测结构。
- RD-Agent(Q)(联合优化):联合优化因子和模型,RD-Agent(Q)o3-mini实现了最高的整体性能:IC为0.0532,ARR为14.21%,IR为1.74,大幅超越了最强的基线方法(如Alpha 158、TRA)。这表明因子和架构的联合提炼释放了互补性改进,实现了可扩展且一致的阿尔法模型构建。