目录
可随意转载。Update2025.01.12
一、论文概述
https://github.com/SamuelSchmidgall/AgentLaboratory
支持DeepSeekV3的版本 https://github.com/vishwamartur/AgentLaboratory/tree/integrate-deepseek-v3
1. Agent Laboratory 能为你做什么?
Agent Laboratory 的主要目的是协助人类研究人员实现研究想法。它接收人类产生的研究想法作为输入,输出研究报告和代码仓库。Agent Laboratory 框架,能够在 MacBook 以及 GPU 集群上运行。它使你能够专注于创意和批判性思维,同时自动化重复性和耗时的任务,如编码和文档撰写,加速科学发现并优化你的研究生产力。
2. Agent Laboratory 是如何工作的?
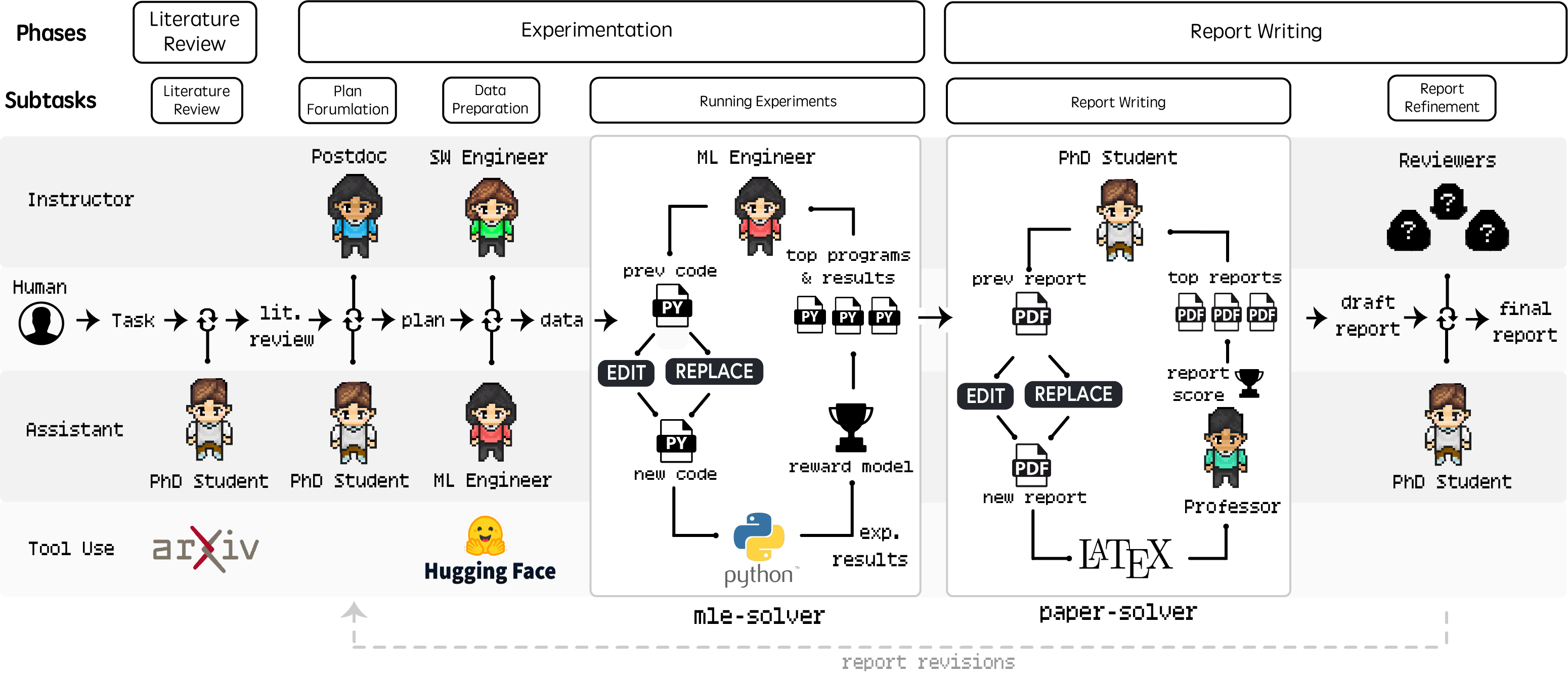
Agent Laboratory 通过三个主要阶段系统地指导研究过程:
(1)文献综述
(2)实验
(3)报告撰写
3. 解决ML问题
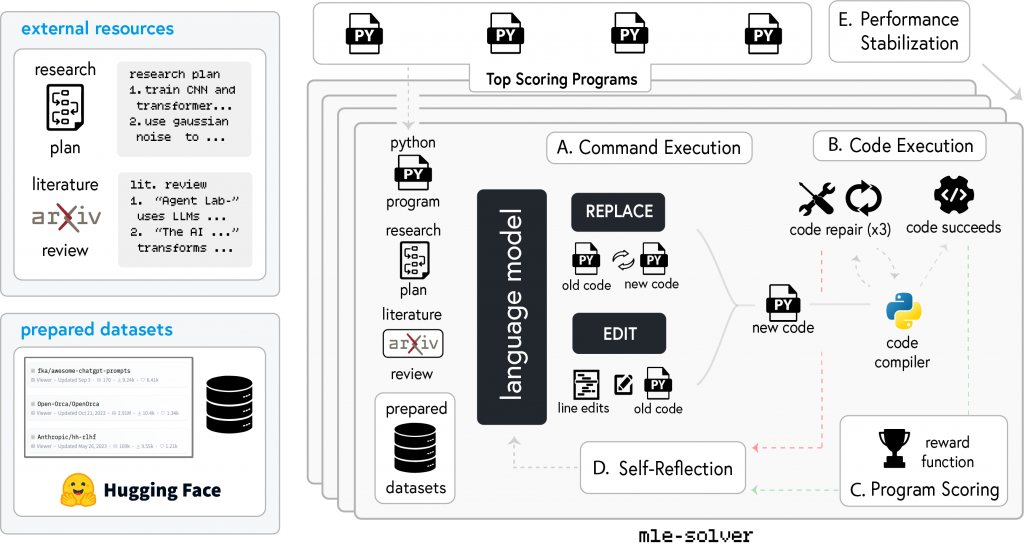
Agent Laboratory 通过 mle-solver 来实现这一点。这个工具作为一个通用的机器学习代码求解器,将前一阶段的研究方向作为文本输入,并迭代改进研究代码。为了实现这一目标,一系列顶级程序会根据输入(如任务指令、命令描述和提炼的知识)进行迭代调整,以根据评分函数改进实验结果。通过两个命令生成一系列更改:REPLACE(重写所有代码)和 EDIT(修改特定行)。成功编译的代码会根据分数更新顶级程序,而错误会触发最多三次修复尝试,然后尝试新代码。代理会在每一步进行反思以优化结果。
3.1 MLE-Bench 评估
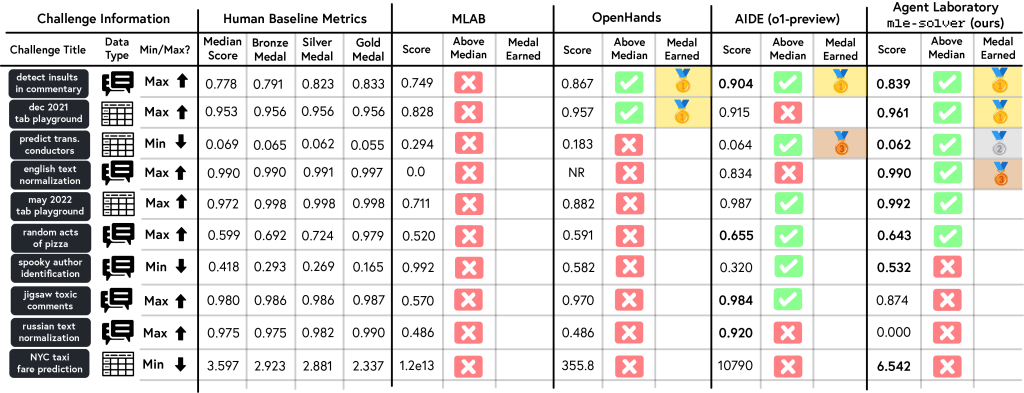
MLE-bench 是一个旨在评估代理处理现实世界机器学习任务的能力的基准测试。这个基准测试将代理性能与人类基线进行比较,使用 Kaggle 的奖牌系统对代理进行评分,并纳入机制以降低污染和抄袭风险。我们发现,Agent Laboratory 的 mle-solver 比其他求解器得分更一致且更高。
4. 撰写研究报告
第二步我们引入了 paper-solver 根据实验设计和结果生成研究报告。paper-solver 综合前一阶段的研究,为研究人员提供清晰的成就总结。输入包括研究计划、实验结果、衍生见解和文献综述,输出符合会议提交标准的学术论文格式。
5. 人工评估LLM生成的报告
本研究评估了三种语言模型后端——gpt-4o、o1-mini 和 o1-preview 生成的研究输出的人类感知质量,从三个维度进行评估:实验质量、报告质量和感知有用性。使用五个研究问题作为模板。
Agent Laboratory 自动生成了 15 篇论文,随后由 10 名志愿者博士生进行评审。这些评审者在 1 到 5 的量表上评估输出。结果显示:
o1-preview 在感知有用性(4.4/5)和报告质量(3.4/5)方面得分最高,尽管其实验质量略低(2.9/5)。
o1-mini 模型获得了最高的实验质量得分(3.2/5),在其他两个维度上表现一致。
相比之下,gpt-4o 总体得分最低,尤其是在实验质量(2.6/5)方面,尽管其有用性评级相对较强,为 4.0/5。
发现表明,每个LLM与研究人员对自主研究生成的期望的一致性存在显著差异。
6. 人类评审者对语言模型的评分
人类评审者使用 NeurIPS 风格的标准评估 Agent Laboratory 生成的论文,评估质量、重要性、清晰度、合理性、呈现和贡献。所有模型的得分都远低于被接受的 NeurIPS 论文的平均得分 5.9,表明在技术和方法论严谨性方面存在显著差距。这些发现强调了进一步完善 Agent Laboratory 以符合高质量研究出版物标准的必要性。
7. 大模型辅助提升质量
我们在大模型辅助(人类引导)模式下评估 Agent Laboratory。研究人员在实用性、继续使用的可能性、满意度和易用性方面对工具进行了评分,分别给出了 3.5/5、3.75/5、3.63/5 和 4.0/5 的评分,涵盖了自定义和预选主题。自定义主题通常获得了更高的评分,尤其是在实用性(+0.5)、继续使用(+0.5)和满意度(+0.25)方面,尽管易用性评分略有下降(-0.5)。预选主题在外部评估中表现更好,与自定义主题在自我评估中获得的更高评分形成对比。在评估论文质量时,大模型辅助模式的评分比自主模式有所提高,平均总分从 3.8/10 提高到 4.38/10(+0.58)。在质量(+0.75)、清晰度(+0.23)、合理性和呈现(+0.33)方面都有所提高,而在重要性(-0.05)和贡献(+0.03)方面的变化很小或有所下降。
8. 成本计算
Agent Laboratory 的运行时间和成本分析显示,gpt-4o 是最具计算效率和成本效益的模型,完成整个工作流程仅需 1165.4 秒,成本为 2.33 美元,显著优于 o1-mini 和 o1-preview。
o1-mini 和 o1-preview 分别需要 3616.8 秒和 6201.3 秒,成本分别为每个工作流程 7.51 美元和 13.10 美元。gpt-4o 在关键子任务(包括运行实验和报告撰写)的速度和成本方面表现出色,比其竞争对手快 3-5 倍,成本也远低于对手。
尽管有差异,所有模型都展现了高可靠性,gpt-4o 的成功率为 98.5%,o1-mini 和 o1-preview 的成功率为 95.7%。
二、深度探索-源码解析
在本地ubuntu上跑代码,访问huggingface和下载datasets有问题。通过增加http代理可以缓解,但是也没办法保证dataset一定有,最好建立私有的datasets才能保证AgentLaboratory高效(有效果)。