目录
可随意转载!Update2022.02.04
前言
论文原文标题:UPDeT: Universal multi-agent reinforcement learning via policy decoupling with transformers
论文作者:Siyi Hu, Fengda Zhu,Xiaojun Chang, Xiaodan Liang
下面是论文翻译。
摘要
一般来说,当前MARL(Multi-Agent Reinforcement Learning 多智能体强化学习)训练模式是:每个模型要从零开始训练。比如《星际争霸2》 3m vs 3m 和5m vs 6m 必须要分别训练,原因是模型的input和output是固定维度的,学习到的经验无法被积累、迁移到新的模型。本篇论文探索一个通用的、可满足多种需求的多智能体框架(UPDeT)。不同于RNN,我们利用基于Transformer的模型,解耦了输出策略分布和输入观察(observation,简称obs),生成了灵活的决策。对比标准的Transformer,我们进一步放松了动作空间维度限制,可解释性也更高。它在MARL中泛化性更好,一次训练可以同时处理多个任务。在更大规模的MAgent环境中实验结果表明,它比传统的算法在性能和训练速度上都提升了10倍,GitHub源代码在这里。
1.简介
MARL解决的是交互场景决策问题,具体包括机器人控制(Hester et al 2010),游戏(Mnihet al. 2015),自动驾驶(Bojarski et al 2016),找人(Chang et al. 2010),视觉语言导航(Zhu et al. 2020)。但是多智能体协作是一个长期的难题,并且它又在很多现实问题的关键路径上,比如多人游戏(Peng et al. 2017)和人口动态研究(Yang et al. 2017)。
已经有很多模型被提出来,比如:动作-值函数模型(Sunehag et al. 2017; Rashid et al. 2018; Du et al. 2019; Mahajan et al. 2019 Hostallero et al 2019 Zhou et al 2020, Yang et al. 2020)。然而这些模型表现能力差,无法共享(或者迁移)模型结构因为他们把观察(obs)作为了模型整体的一部分。他们认为神经网络可以自行解耦观察(obs)和策略。这种方法把其他agent或者环境中信息混合处理,最常见的问题是把观察(obs)作为输入(Rashid el al. 2018; Du el al. 2019; Zhou el al. 2020)。此外,这种方法忽略了每个动作背后的物理含义。多智能体观察(obs)和输出之间有密切关联,如果不把观察(obs)和其他输入参数分离,那么agent的个体Qi可能误导全局Q函数。更糟糕的是,传统模型要求输入输出维度都是固定的(Shao et al. 2018; Wang et al. 2020)。这使得算法迁移变得不可能,在现实问题中成为巨大的限制条件。
我们的目标是开发一个不限制输入/输出维度、具有通用性、可解释的,可以优化单任务场景最终性能,多任务场景可以做迁移学习的MARL算法。如下图:

受到Self-Attention机制的启发(Vaswani et al. 2017),我们提出了基于Transformer的算法,取名叫UPDeT,该算法有以下四个优点:
- 训练好以后,可以四处部署
- 策略解耦后算法表达能力更健壮
- 算法可解释性更强
- 可以泛化在任何MARL领域
我们把不同维度大小的个体观察数组(individual observation)称为“observation-entities”(简称OE)。
策略解耦的具体办法是:
用Transformer函数来处理OE。接着依据动作和OE的对应关系,把动作空间划分成多个action-group(简称AG)。这样我们就得到了OE-AG Pair。
下一步,用Self-Attention学习Pair中的OE和其他OE的关系。通过使用self-attention map和对OE的embedding操作,UPDeT框架在action-group级别优化策略。这就是策略解耦。结合了策略解耦和Transformer的UPDeT框架显著优于传统RNN。
在UPDeT算法中,不需要为新的任务引入新的参数。我们还证明了有且仅有在OE与AG相匹配的解耦策略下UPDeT框架才能学到具有高迁移能力的强表征。最后,我们建议把UPDeT算法插入您现有的算法中,不需要改变整体结构也能够带来显著的最终性能提升,尤其在业务场景复杂情况下。
我们的主要贡献在于:
- 算法在最终性能上远超RNN
- 算法迁移能力强,可以同时处理多个不同任务
- 算法的学习速度大多数情况下比RNN快10倍
2.相关工作
回顾其他先贤的工作,然后说自己是在多智能体强化学习领域第一个用transformer做到同时处理多个不同任务的。另外算法的策略解耦可以做强化学习迁移,更贴合现实需求。
3.具体方法
我们先介绍符号定义和基本任务设定。然后描述MARL中的基于transformer的个体函数和策略解耦。最后我们引入了不同的时间单位,将我们的UPDet吸收到Dec-POMDP中。
3.1符号和任务设定
MARL定义
CTDE定义
3.2基于transformer的个体Q函数
3.2.1 数学公式
我们用self-attention来算全局Q 。第一步,把不同维度的obs用语义embedding来处理。例如:agent( ai)在时刻 t 观察其他k个agent得到k个obs {oi,1 , …, oi,k },所有obs可以用语义embedding层E来表示成如下形式:

i是智能体的下标,i ∈ {1, …, n}。下一步,所有n个智能体的每个step的q函数可用如下公式表示:

在上面的公式中,我们引入了参数hit-1 ,代表t-1时刻的隐藏状态,因为POMDP决策高度依赖历史信息。eit 表示公式(1)中obs embedding,uit 是候选动作,uit∈ U。全局Q函数可以用个体q函数表示为:

Fi是每个agent(ai )的信用分配函数。由论文(Rashid et al. 2018; Sunehag et al. 2017)定义。例如在VDN中F被定义成算术和:
F(q1t , .. , qnt) = Σi=1n qit
3.2.2 用self-attention实现Q函数
原始的Self-Attention计算公式如下:
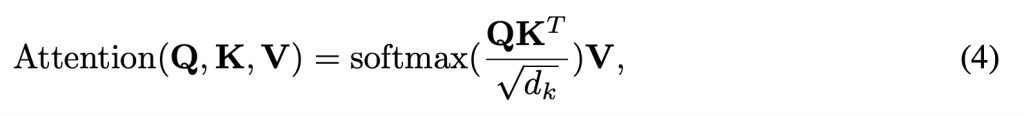
在本文的算法中,我们使用self-attention从Embedding和全局状态中学习特征和关系。为了学习到分布式多个agent的独立策略,我们为每个agent(ai)定义了Ki,Qi,Vi,下一步我们假定Ril = Ki = Qi = Vi 其中 l∈{1,…,L}是transformer网络层的编号,然后我们可以得出算法的transformer定义:
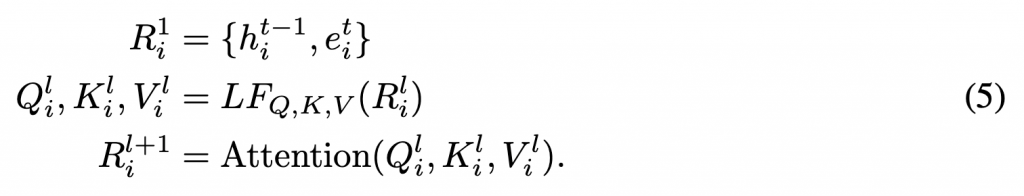
LF是用来计算K,Q,V的线性函数。最后用下面公式映射(project)最后一层RiL(网络层号为L)的结果得到Qi函数(P是线性函数)
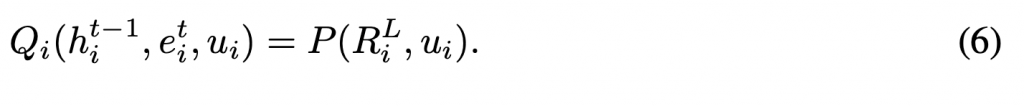
3.3 策略解耦
上面一节的个体Q函数无法解决策略分布问题。公式(6)的P函数必须要处理各种维度的输入输出并且具有强大的表达能力。利用输入输出的相关性,我们设计了本算法的最关键部分策略解耦P函数。
策略解耦P函数的三大目标:
- AR – 不限制动作策略维度 标准的transformer的约束是:输出维度要小于等于输入维度。这在MARL中是不能接受的,因为动作空间可能大于entity空间。
- MA – 模型一次可处理多个任务 需要相对固定的网络结构而不是引入新的参数,不幸的是这跟第一点难以两全的。
- EXP – 模型可解释性提升 用解释性更好的策略生成网络替代RNN。
基于上面三个原则,我们相应提出了三种策略解耦方法,分别取名叫做Vanilla(原始),Aggregation(聚合) 和 Universal(UPDeT)。如下图:
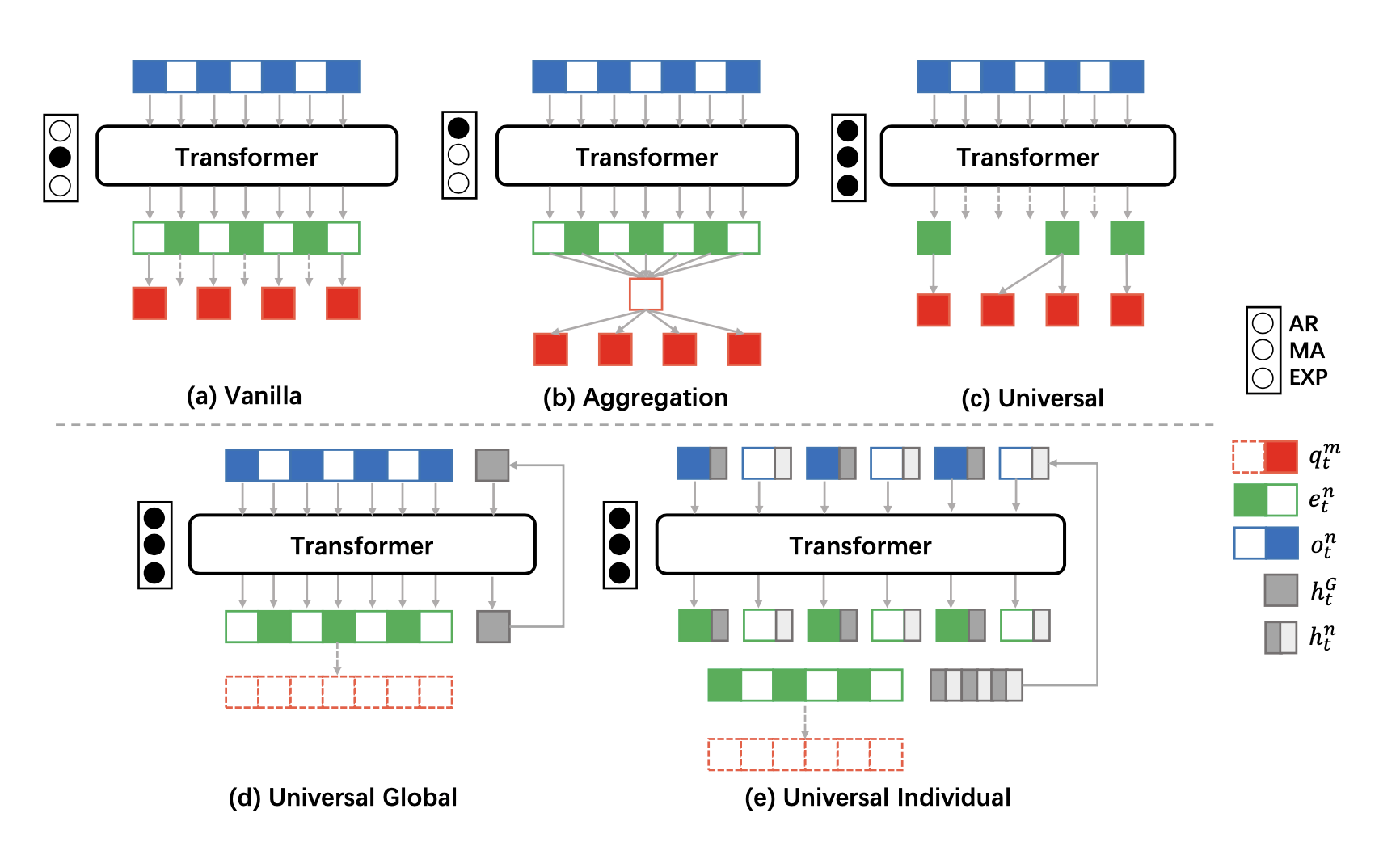
符号含义:
AR:动作空间限制。 MA:一次执行多个任务。 EXP:可解释性
黑点表示满足对应原则
o: obs e: embedding q: Q值函数 h: 隐藏状态层
其中Vanilla,Aggregation只是用来作对比,我们主要讲UPDeT。
任务是:公式(5)中指出的Transformer最后一层RiL的特征OE。
挑战是在特征OE和动作策略分布两者之中建立强关联。
UPDet首先的想法是将输入OE和对应的动作(output policy part)匹配。这种情况在MARL中很常见,比如两个agent交互(协作或者竞争)。一旦我们匹配上了特征OE和动作,我们可以大大减少用self-attention学习表征的算力负担。另外,考虑到一个OE可能关联多个动作,我们把动作空间切分成动作组(AG),和OE关联的动作都放到一个AG组里。处理流程请看下图左边。为了满足上面的第1,2个原则,我们设计的映射函数考虑了2个策略:
- 如果动作组的动作大于1个会增加一个共享的全连接层将输出映射到动作编号维度
- 如果特征没有对应的动作组,直接抛弃
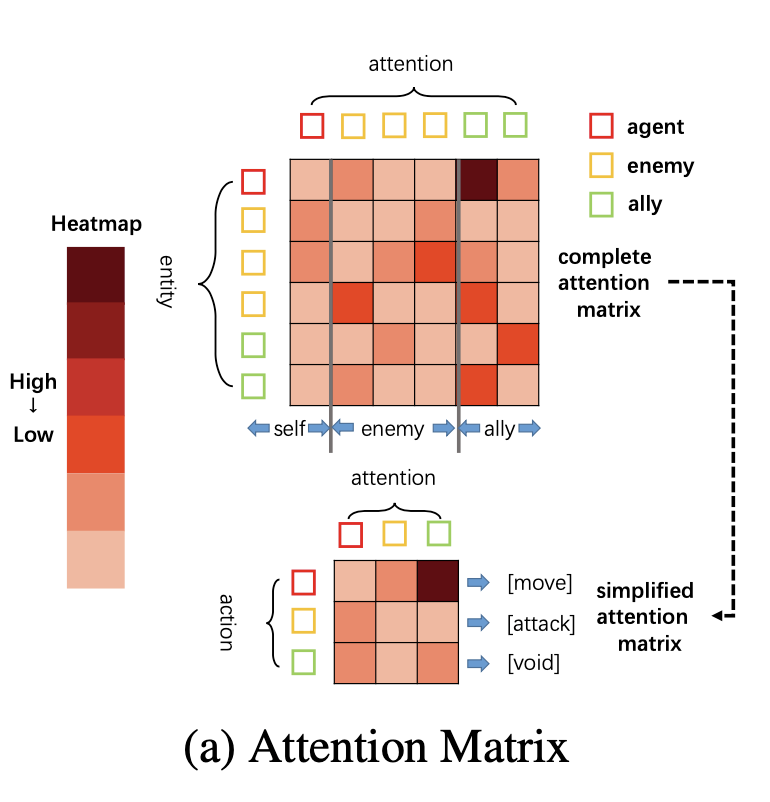
这两点请看下图右边。显而易见,UPDet算法既没有限制动作维度,又没有引入新的参数。一个模型就可以处理不同的任务。那么关于上面的原则3,映射函数匹配相应的特征和动作组即可满足原则3。我们将在4.4节讨论:我们可以用attention的热力图来分析策略的可解释性。
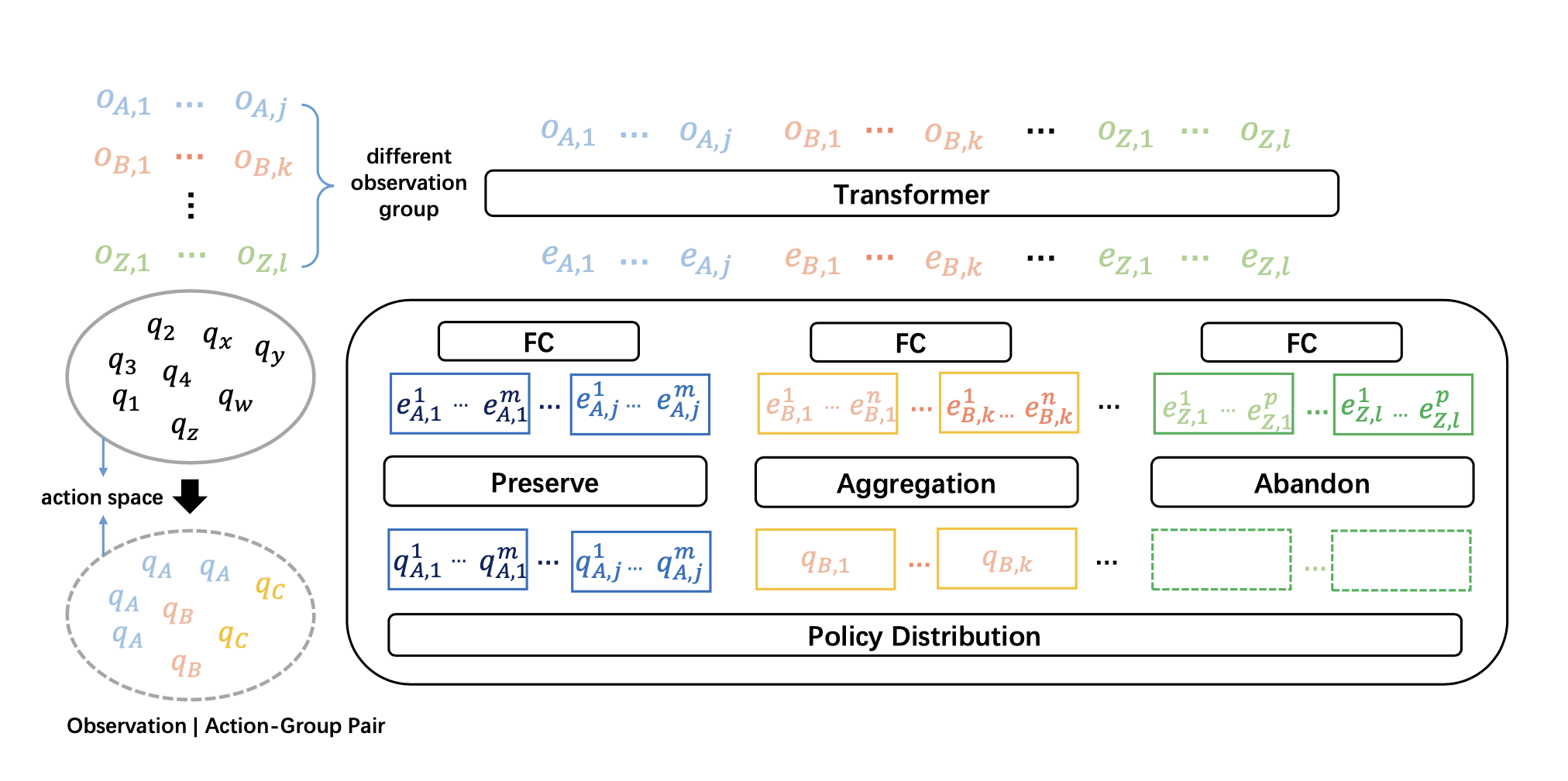
左边的含义:把q分成了a,b,c三个组(自己,盟友,敌人)
右边的含义:把Observation通过Transformer转换成了Embedding,然后把Embedding映射到Policy。映射内部有丢弃(abandon)、聚合(aggregation)、保留(preserve)三种操作。

把虚线框住的绿色的两个embedding丢弃了。
把橙色的三个embedding用平均值函数聚合成了1个。
红色的embedding没变,所有动作策略都保留下来了。
3.4 时间单元架构(TEMPORAL UNIT STRUCTURE)
注意,基于transformer的个体Q函数(即使用上策略解耦)如果没有历史信息的话,仍然无法处理部分可观察决策过程(POMDP)。在论文Dec POMDP(Oliehoek et al. 2016)中讲到每个agent通过策略πa (ua | τa )(其中u是历史动作空间,τ是历史动作-观察联合空间)应用GRU或者LSTM算法。而我们则是通过一个隐藏层来获取动作-观察历史信息。然后,transformer和隐藏层的结合在理论上没有得到充分研究,在本节中,我们提出了处理UPDeT算法中隐藏层2种方法:
- 全局 时间单元把隐藏层当成transformer block的额外输入。和公式5一个意思。R1 = { hgt-1, e1t } 和 { hGt, eLt } = RL 。这里我们忽略了下标i可使用G来表示“全局”概念。这个全局时间单元是简单而且有效的,实践中具有稳健的高性能。
- 个体 时间单元认为隐藏层是每个独立entity的一部分。换句话来说,每个输入维护了自身的隐藏层,输出给下一步时映射了一个新的隐藏层作为下一时刻的输入。这种方法把全局隐藏层拆分到个体中,是一种更精确管理历史信息的手段。我们用j来给entity计数,输入和输出的关系可以表示为R1 = { h1t-1,…hjt-1 e1t } 和{ h1t,…hjt ,eLt } = RL 。然而,这种方法增加了算力负担,我们会在4.1.2中进一步讨论。
3.5 优化器
我们在DQN(Mnih et al. 2015)中用的是TD方差作为优化器,来最小化下面的公式:
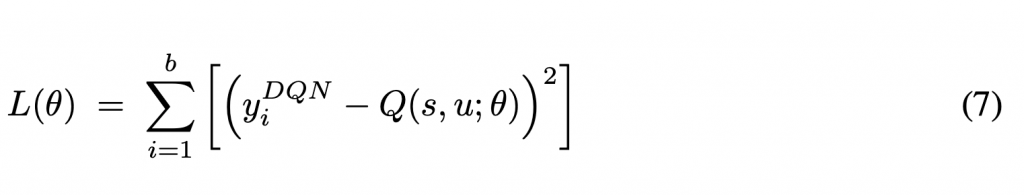
公式中b表示batch大小,在部分可观察场景下,agent可以受益于动作-观察历史信息。Hausknecht&Stone(2015)提出了DRQN(Deep Recurrent Q-networks)来解决顺序DP问题。对于我们来说,我们把GRU(Chung et al. 2014),LSTM(Hochreiter & Schmidhuber 1997)这部分替换成了基于transformer的时间单元来训练整个模型。
4. 星际争霸2实验
本节,用星际争霸2环境评估算法UPDeT。我们将对比在单一任务场景下对比传统RNN算法和UPDeT算法,同时测试UPDeT模型的迁移能力。实验结果表明UPDeT有显著提升。
4.1 单一任务场景
MARL实验中评估了三种算法分别是VDN,QMIX,QTRAN。这三个算法被选中是因为他们比其他算法(COMA, IQL)都强。我们把UPDeT算法和这三种算法结合,以证明我们的算法比GRU强。(注:因为原算法的agent部分是GRU,这里的意思是用policy decoupling with transformer替换GRU,算法整体结构还是不变)
4.1.2 实验结果
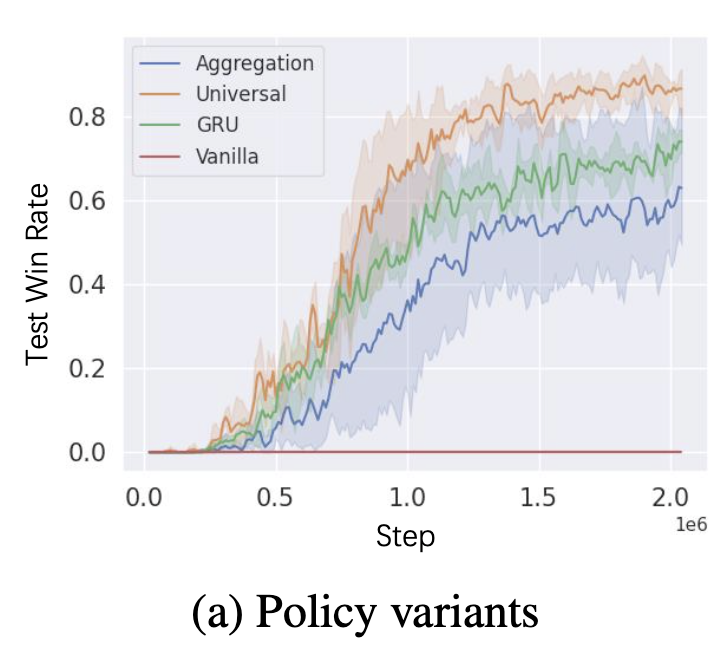
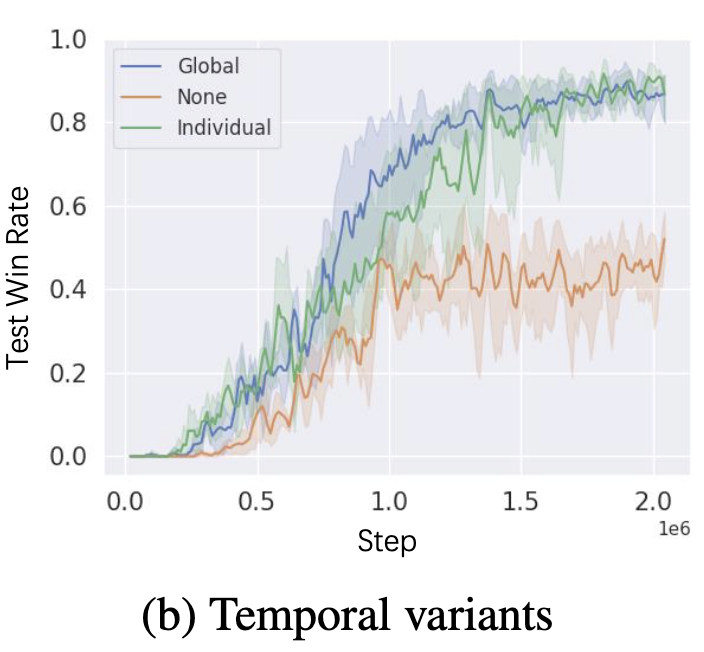
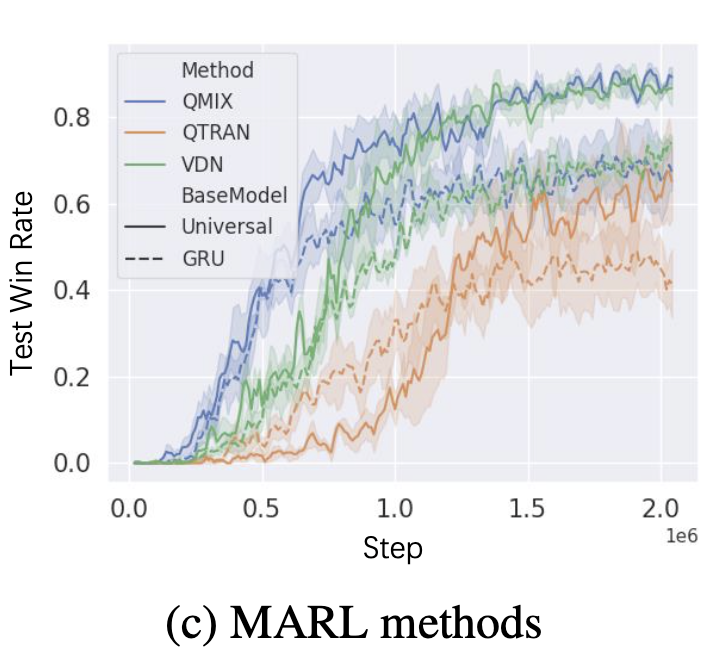
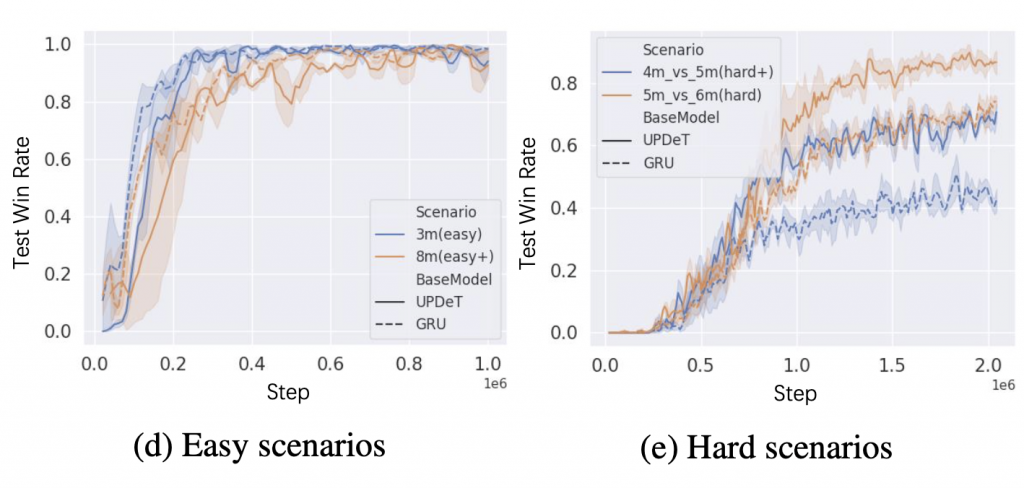
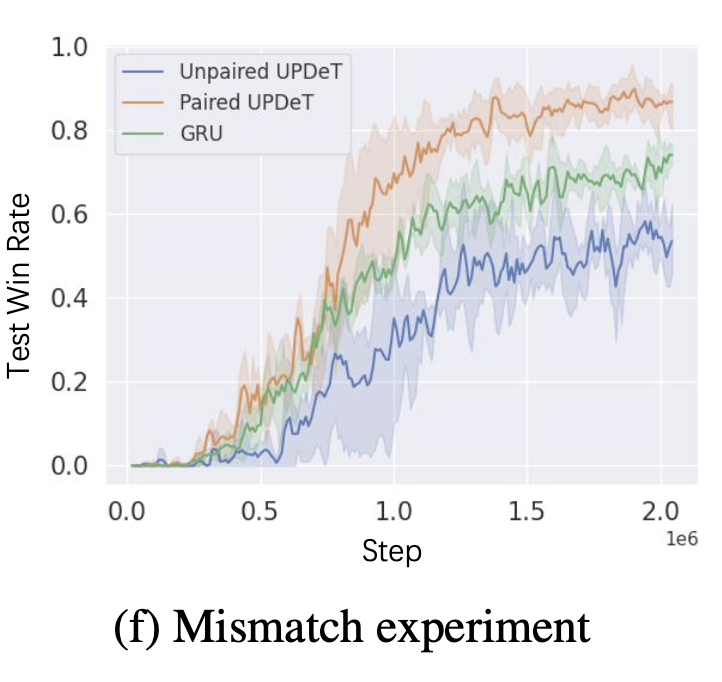
4.2 多任务场景
注意:这个多任务指的是: 3m vs 3m, 5m vs 6m同时加入到训练中。
本节,我们要对比UPDeT和传统RNN模型的迁移能力。过程设计如下:先训练3m vs 3m ,然后把得到的预训练模型训练5m vs 5m 和 7m vs 7m。最后又做了一个7m vs 7m 的预训练模型来训练3m vs 3m。整个过程中UPDeT的模型结构保持不变。作为对比的RNN模型,因为输入输出维度必须要改,所以我们在训练过程中保留了GRU的模型参数没动,改了输入输出层,以便算法可以跑通。请看下面的图。使用了预训练模型的UPDeT算法比同样的GRU算法快10倍,比从头训练快100倍。另外在没有做finetune的情况下,算法也显示出了泛化能力说明算法确实学到了健壮的策略。
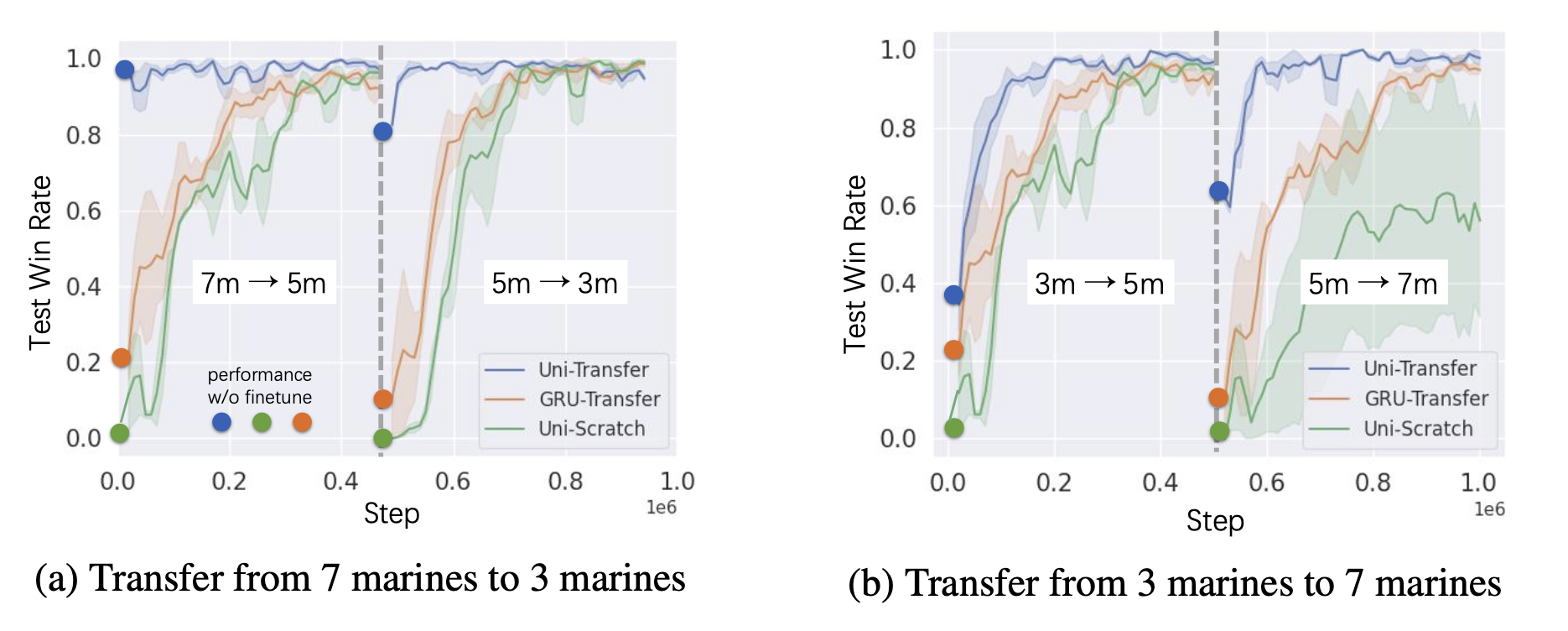
每个训练过程一共有1M的steps,在step 0 和 step 500k 我们从预训练模型做finetune。圆点表示不做finetune的迁移训练效果(这种情况下,数据会停在那个点上不变)。
4.3 在大数据及MAS上实验
为了评估大规模场景中的模型性能,我们在SMAC的10m vs 11m和20m vs 21m场景以及MAgent环境中的64 vs 64战斗游戏中测试了我们提出的UPDeT(Zheng et al.(2017))。最终结果见附录E。
4.4 基于attention的策略:一个分析
UPDeT在SMAC多智能体挑战中取得的显著性能改进可归功于transformer块和策略解耦。本节主要是讨论attention机制如何帮助大家获得健壮的、可解释的策略。这里拿3m vs 3m来举例(attention矩阵大小6 x 6),如下图把原始attention矩阵分组
下图显示三个不同阶段,包括游戏开始、攻击和生存,以及它们相应的attention矩阵和输出决策。
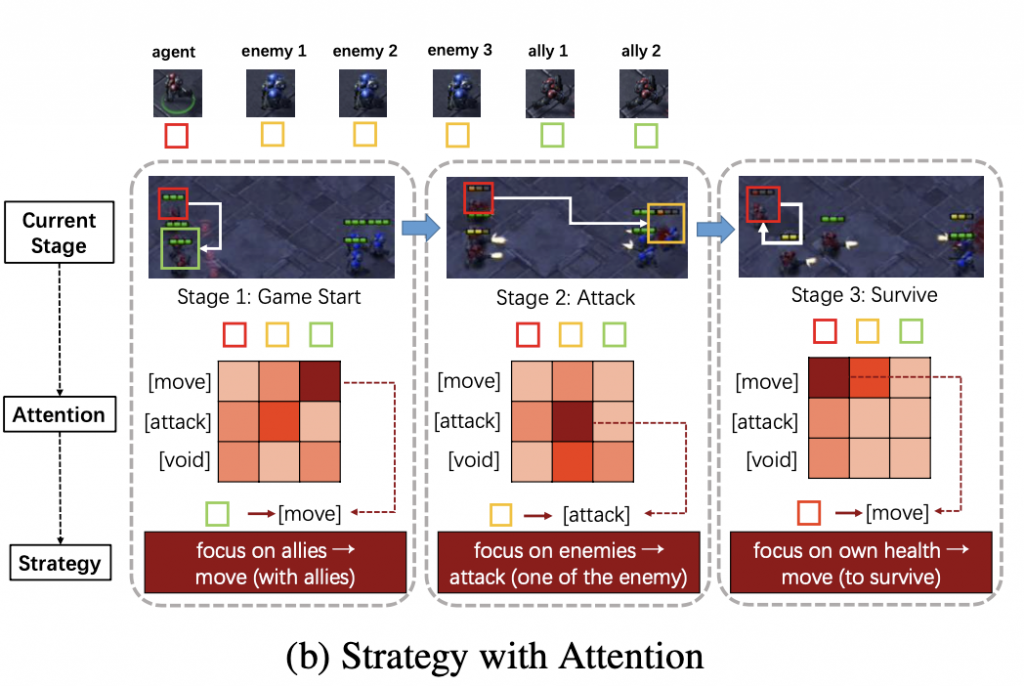
在攻击阶段,最高的注意力在矩阵的[2,2](编号从1开始),这表明敌人现在在agent的攻击范围内;因此,agent会攻击敌人以获得更多奖励。令人惊讶的是agent会选择攻击生命值最低的敌人。也就是说通过attention机制,算法知道去避免长期的惩罚而选择击杀生命值最低的敌人。
在生存阶段,agent的健康值较低,这意味着它需要避免受到攻击。最受关注的是[1,1](编号从1开始),这清楚地表明,在当前情况下,最重要的事情是活着。只要自己还活着,当敌人攻击盟友而不是agent自身时,他仍然有机会回到前线并获得更多奖励。
综上所述,UPDeT的self-attention和策略解耦在attention权重和最终策略之间提供了强大而清晰的关系。这种关系可以帮助我们更好地理解基于attention分布的策略是怎么生成的。这里呈现了一个有趣的想法:如果我们能够找到attention矩阵和最终策略之间的强映射,那么可以以无监督的方式修改agent的特性。
5.结论
本文提出了UPDeT,扩展了MARL领域范围,可以插入现有的任何算法中,并且强过基于GRU的算法。因为有了迁移学习的能力,比从头训练快100倍。另外比基于RNN的算法训练起来快10倍。下一步我们的目标是写一个集中式的函数,利用self-attention来优化MARL领域的全流程。
附录A SMAC环境简介
SMAC动作空间包括:4个移动方向,k个攻击(根据地图设定的敌人数),停止和无动作。每一个step,agents接收到联合团队奖励(对敌军的总伤害和敌军对我军的总伤害)。agent定义了以下几个属性:HP,CD,兵种,最后动作,相对距离(部分可观察)。敌军定义的属性类似(除了CD)。部分可观察(包括敌军和我军)是用一个圆,数据里面包含了敌我agents。
源码分析

- 程序入口在run.py的run_sequential方法
def run_sequential(args, logger):
...
# Transformer结构从这里开始
# 多agent控制类mac ==> multi-agent controllers
mac = mac_REGISTRY[args.mac](buffer.scheme, groups, args)
...
# 初始化runner
# runner有两种形式:一种叫EpisodeRunner,另外一种叫ParallelRunner
# 其中EpisodeRunner等同于PARL的train.py中的循环训练函数(run_episode)
# 把mac作为参数传递进去
runner.setup(scheme=scheme, groups=groups, preprocess=preprocess, mac=mac)
...
# 集中式学习
# 把mac作为参数传递进去
# 在config/algs目录中定义配置,有多种Learner
# 比如QLearner类包含两种算法vdn、qmix的Learner实现
learner = le_REGISTRY[args.learner](mac, buffer.scheme, logger, args)
...
# 循环
while runner.t_env <= args.t_max:
# 执行训练-run
episode_batch = runner.run(test_mode=False)
...
if buffer.can_sample(args.batch_size):
...
# 执行学习-train
learner.train(episode_sample, runner.t_env, episode)
...args参数是: 主配置文件的初始配置 + SMAC的星际争霸2参数。
2. 多agent控制类 multi-agent controllers
controllers目录的basic_controller.py文件:
from components.action_selectors import REGISTRY as action_REGISTRY
...
class BasicMAC:
def __init__(self, scheme, groups, args):
...
# 在config/algs目录中定义了用哪种action selector,比如QMIX用的是:“epsilon_greedy”
# 在components目录的action_selectors.py中指定为EpsilonGreedyActionSelector类
self.action_selector = action_REGISTRY[args.action_selector](args)
...
def select_actions(self, ep_batch, t_ep, t_env, bs=slice(None), test_mode=False):
...
# 调用了自己的forward方法
agent_outputs = self.forward(ep_batch, t_ep, test_mode=test_mode)
# 调用了component目录中对应ActionSelector的方法
chosen_actions = self.action_selector.select_action(agent_outputs[bs], avail_actions[bs], t_env, test_mode=test_mode)
return chosen_actions
def forward(self, ep_batch, t, test_mode=False):
# 基于RNN的agent
...
# 基于Transformer的agent
else:
# 预处理obs
agent_inputs = self._build_inputs_transformer(ep_batch, t)
# 调用agent类(例如:UPDeT)的forward
agent_outs, self.hidden_states = self.agent(agent_inputs,
self.hidden_states.reshape(-1, 1, self.args.emb),
self.args.enemy_num, self.args.ally_num)
# 调整数组维度,传递给动作选择器
return agent_outs.view(ep_batch.batch_size, self.n_agents, -1)
def _build_inputs_transformer(self, batch, t):
inputs = []
raw_obs = batch["obs"][:, t]
# 把最后一列换到最前面
arranged_obs = th.cat((raw_obs[:, :, -1:], raw_obs[:, :, :-1]), 2)
# 数组结构--->[自己+敌人+盟友]
reshaped_obs = arranged_obs.view(-1, 1 + (self.args.enemy_num - 1) + self.args.ally_num, self.args.token_dim)
# 下面两句没有也没关系
inputs.append(reshaped_obs)
inputs = th.cat(inputs, dim=1).cuda()
return inputs
# 定义了各类agent,比如updet agent
def _build_agents(self, input_shape):
self.agent = agent_REGISTRY[self.args.agent](input_shape, self.args)5m vs 6m环境下_build_inputs_transformer中变量的尺寸如下:
raw_obs: [1, 5, 55]
arranged_obs: [1, 5, 55]
reshaped_obs: [5, 11, 5]
inputs: [5, 11, 5]3. Agent
在modules/agents目录的updet_agent.py 文件中。
源码理解
- 策略解耦
通过上面的”_build_inputs_transformer”函数,预处理obs得到了inputs,然后用Transformer处理inputs得到outputs,outputs可以解偶成3个部分(Figure 7),在下面代码中只处理了Main Agent和enemies的Qi,抛弃了alliens的Qi,其中enemies的Qi用了简单的算术平均(公式(3))。
class UPDeT(nn.Module):
def __init__(self, input_shape, args):
...
# 定义Transformer
self.transformer = Transformer(args.token_dim, args.emb, args.heads, args.depth, args.emb)
# 定义线性层
self.q_basic = nn.Linear(args.emb, 6)
...
def forward(self, inputs, hidden_state, task_enemy_num, task_ally_num):
# inputs用Transformer处理得到outputs(Figure 7--Raw)
outputs, _ = self.transformer.forward(inputs, hidden_state, None)
# Main Agent的个体Q
q_basic_actions = self.q_basic(outputs[:, 0, :])
...
# Enemies的个体Q
for i in range(task_enemy_num):
q_enemy = self.q_basic(outputs[:, 1 + i, :])
...
5m vs 6m 场景下,UPDeT类中forward方法的各个变量的尺寸:
inputs: [5, 11, 5]
hidden_state: [5, 1, 32]
outputs: [5, 12, 32]: self + enemies + aliens + hidden = 1 + 6 + (5-1) + 1
q_basic_actions: [5, 6]
h: [5, 1, 32]
q_enemy: [5, 6]
q_enemies: [5, 6]
q: [5, 12]2. 动作选择
class EpsilonGreedyActionSelector():
def __init__(self, args):
self.args = args
self.schedule = DecayThenFlatSchedule(args.epsilon_start, args.epsilon_finish, args.epsilon_anneal_time,
decay="linear")
self.epsilon = self.schedule.eval(0)
# 根据Transformer处理过的q,选择动作
def select_action(self, agent_inputs, avail_actions, t_env, test_mode=False):
# Assuming agent_inputs is a batch of Q-Values for each agent bav
self.epsilon = self.schedule.eval(t_env)
if test_mode:
# Greedy action selection only
self.epsilon = 0.0
# mask actions that are excluded from selection
masked_q_values = agent_inputs.clone()
masked_q_values[avail_actions == 0.0] = -float("inf") # should never be selected!
random_numbers = th.rand_like(agent_inputs[:, :, 0])
pick_random = (random_numbers < self.epsilon).long()
random_actions = Categorical(avail_actions.float()).sample().long()
picked_actions = pick_random * random_actions + (1 - pick_random) * masked_q_values.max(dim=2)[1]
return picked_actions效果测试
基于CPU(机器配置)跑5m VS 6m,结果如下:
[INFO 07:57:51] my_main Recent Stats | t_env: 2042563 | Episode: 85593
battle_won_mean: 0.3959 dead_allies_mean: 4.0531 dead_enemies_mean: 4.8739 ep_length_mean: 25.4066
epsilon: 0.0500 grad_norm: 6.6271 loss: 0.6557 q_taken_mean: 1.8970
return_mean: 13.7802 return_std: 5.1571 target_mean: 1.8870 td_error_abs: 0.5135
test_battle_won_mean: 0.9187 test_dead_allies_mean: 2.4312 test_dead_enemies_mean: 5.8875 test_ep_length_mean: 26.1250
test_return_mean: 19.2396 test_return_std: 2.4479
[INFO 07:58:05] my_main Updated target network
[INFO 08:04:12] my_main Updated target network
RequestQuit command received.
Closing Application...