目录
可随意转载 Update2022.01.13
前言
人工智能领域发展极为迅猛,Facebook AI Research FAIR研究院绝对是不可忽视的一个团队。才进入2022年,它又出了新论文。通过大量实践证明ConvNeXt在目标检测和图像分隔领域优于Swin Transformer,众所周知,Conv是传统CV基石,大家对它也相对熟练,本文值得一读。以下是论文原文
摘要
人工智能繁荣的2020年代始于ViTs,Transformer取代了传统的卷积神经网络在图像分类领域成为了SOTA。ViTs在目标检测方向遇到了困难,很快Swin Transformer(简称:Swin-T)引入了一些传统的卷积神经网络结构使得Transformer成为了CV领域广泛使用的backbone网络。然而Swin-T这种混合结构主要还是靠Transformer的强大能力。这篇论文中我们重新设计了一个纯粹的卷积神经网络,展现了传统卷积神经网络的强大能力。我们从ResNet出发改造卷积神经网络,对比ViTs,找出使得它强大的几个关键的网络组件。论文的结果我们自称为:ConvNeXt。它完全由卷积网络组成,在精度和scalability方面可以同Transformer系列模型竞争,在ImageNet数据集Top-1精度上达到了87.8%,在COCO数据集做目标检测和ADE20K数据集做图像分割优于Swin Transformer。同时,我们还保持了神经网络的简洁性、标准以及效率。
简介
2010这十年,深度学习发生了巨大的进步。最大的驱动力就是神经网络,尤其是卷积神经网络(ConvNet)。视觉识别的工作也从特征工程转移到了神经网络设计。尽管神经网络的反向传播理论早在1980年代就已被发明。但是直到2012年才看到它在视觉特征学习方面的潜力。AlexNet带领大家进入了ImageNet竞赛的时代。像VGG、Inceptions、ResNet、DenseNet、MobileNet、EfficientNet、RegNet等代表性的卷积神经网络在各方面都大放异彩。
卷积网络的成功并非偶然,在CV领域滑动窗口是视觉处理固有的策略。卷积神经网络的几个内在特性决定了它很适合这个领域,在目标检测领域,平移不变性(translation equivariance)也极为重要,这些都是卷积神经网络的优势。由于是以滑动窗口方式使用,计算可以共享所以比较高效。几十年来,大家一直这样使用ConvNet,比如在数字、人脸、行人等有限分类上。在2010年代,目标检测用卷积神经网络做它的backbone,就在同时NLP(自然语言处理)领域走出了一条截然不同的路,它用Transformer替代RNN成为了主流的backbone。尽管这两个领域有所不同,但自从ViTs在CV领域首次引入了Transformer,改变了CV领域以卷积神经网络为主流的传统,这两个截然不同领域惊人的融合了。ViTs对原始Transformer改动很小。ViTs借助了更大的模型和数据集,精度显著的超出标准ResNet。这些图像分类领域的新成绩令人鼓舞,但CV不仅仅是图像分类。在之前的介绍中讲到很多CV都在用滑动窗口和卷积,没有卷积神经网络做backbone,ViTs在很多领域并不好用。最大的挑战在于:ViTs的全局注意力设计对于大尺寸输入来说复杂度很高(因为是平方关系),对于ImageNet上的分类任务来说还行,对于高精度的图片就很难了。
分层Transformer被引入来解决这些问题,比如:滑动窗口策略、本地窗口注意力。这种方法是卷积神经网络中的传统做法。Swin-T就是这样一个典型,它证明了Transformer可以被作为通用backbone,在图像分类以外的CV任务中实现SOTA。Swin-T的成功从另一个角度证明了传统卷积仍然有用。从这个角度延伸去想,Swin-T的诸多优点的终点指向了传统卷积神经网络。因为Swin-T的这些优势都是有代价的:滑动窗口注意力机制算力成本很高;使用循环shift可以优化但设计太复杂。从另一个角度看,传统卷积神经网络直接就能满足此类需求。卷积神经网络落后的原因是Transformer的多头自注意力组件的强大scaling能力,而不是卷积本身。
不同于卷积神经网络在过去十年的发展,ViTs是一个不同的方向。在最近的文献中,通常会(拿Swin-T和ResNet)做系统性比较。ConvNet和分层Transformer有相同和不同的地方:它们都有归纳偏置(inductive bias),但是在训练以及宏观/微观的网络设计上都非常不同。这篇论文中,我们研究了架构差异,试图找到导致两类网络性能差异的变量。我们试图架起Transformer系列网络出现后,卷积神经网络继续向前发展的桥梁(含义是:并不是ConvNet不行,大家却都研究Transformer去了),并测试了卷积神经网络的极限。
我们从一个最简单的ResNet50出发,一步步将它改造成类似分层Transformer结构(比如Swin-T)。关键问题是:如何用Swin-T的优秀设计改造传统卷积神经网络?
我们发现了几种导致性能差异的关键组件,着手对传统卷积神经网络进行改造,并提出了名叫ConvNeXt的纯卷积神经网络。我们在各种视觉任务上评估它:ImageNet上的图像分类;COCO上的图像检测/分类;ADE20K上的语义分割。令人惊讶的是ConvNeXt在所有基准测试中的准确性、scalability和健壮性都能与Swin-T媲美,同时它还保持了卷积神经网络的高效率,以及卷积神经网络的训练/测试的简单性。
我们希望这些观察和讨论能够引起一些共鸣,并为传统卷积神经网络求关注。
改造ConvNet:蓝图
在本节中,我们模仿Swin-T演示了从ResNet到ConvNeXt的改造轨迹。我们从算力(FLOP)角度选择了2个模型。一个是ResNet50/Swin-T,算力约束为(4.5×10 9次方);第二个是ResNet200/Swin-B,算力约束为(15×10 9次方)。为了简化起见,我们直接展示第一个模型(ResNet50)的结果。更高容量模型的的结论在附录C。
我们研究了Swin-T不同于传统卷积神经网络的设计,并把它们抄了过来。先从ResNet50出发,先用ViTs的训练量来训练ResNet50,可以得到一个改进的效果作为baseline。我们做了以下的设计改进:
- 宏观修改
- 网络加深加宽
- 逆瓶颈
- 更大的卷积核
- 微观修改
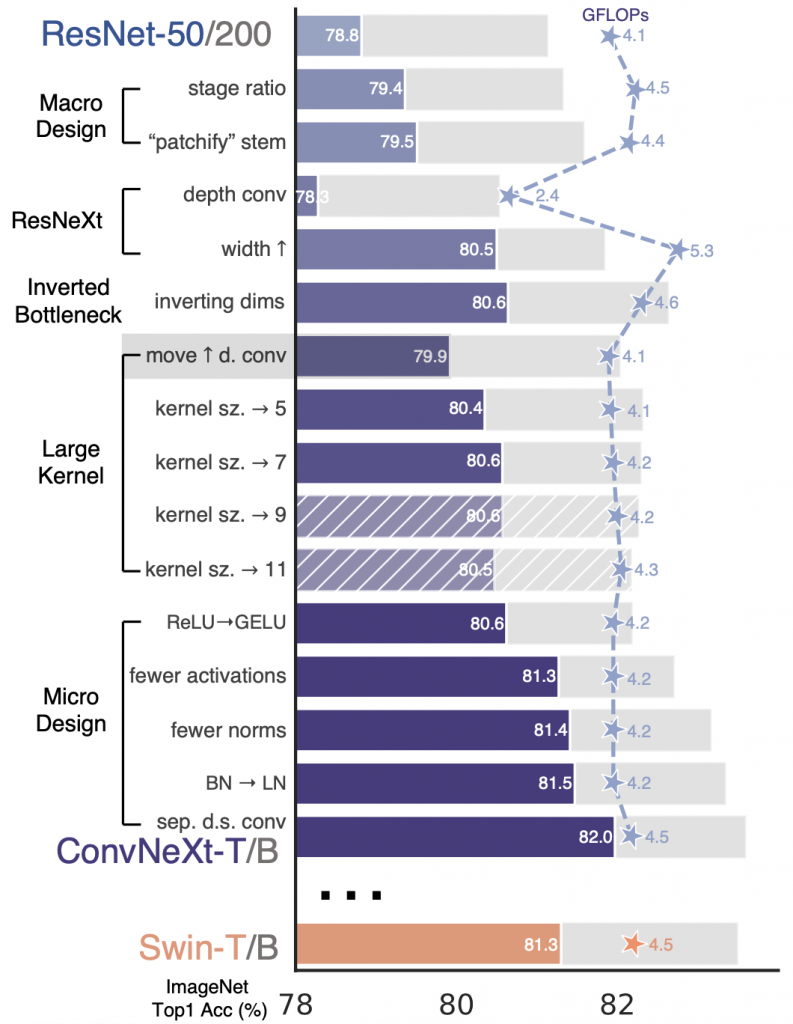
改造轨迹如下图所示:
训练技巧
除了网络模型外,怎么训练也会影响结果。比如用Adam W优化器,这跟优化策略和超参数有关。因此我们第一步就用了这个优化器来改进ResNet50。最近有一篇文章写了如何用这些训练技巧来改进ResNet50(参考链接[76])。在本文中我们采用的技巧是:
- 将训练Epoch数从90增加到300;
- 优化器从SGD改为AdamW;
- 更复杂的数据扩充策略,包括Mixup,CutMix,RandAugment,Random Erasing等;
- 增加正则策略,例如随机深度[7],标签平滑[8],EMA[9]等。
仅仅优化了训练技巧可以把ResNet50的精度从76.1% 提升到78.8%(+2.7%)。
宏观修改
stage内的块比例:
VGG提出了把骨干网络分成若干个网络块的结构,每个网络块通过池化操作将Feature Map降采样到不同的尺寸。在VGG中,每个网络块的网络层的数量基本是相同,但之后的很多工作经验指出当深层的网络块层数更多时,模型的表现更好。例如,ResNet50中共有4个不同的网络块,每个网络块又有若干个不同的基础层,一般是由卷积,BN等操作组成,它的每个网络块的层数是 (3, 4, 6, 3)。在Swin-T中,这个Block的比例是 1:1:3:1而对于更大的模型来说这个比例是1:1:9:1。我们把ResNet50的块比例从(3, 4, 6, 3)提升到了(3, 3, 9,3),它的精度就从78.8%提升到79.4%(注意:调整块比例后,算力FLOP也增加了,因此精度增加的部分功劳来也自算力的增加)。
patchify stem:
ResNet50的stem cell通常使用7×7的卷积核,步长为2,加上最大池化将原始图像尺寸降采样4倍。ViTs中更激进,它采用了一个14×14或者16×16的卷积核并且设置对应的步长做无覆盖卷积操作,叫做Patchify(补丁化)卷积。Swin-T把这部分叫做stem层,它是位于输入之后的一个降采样层(patch size = 4)。在ConvNeXt中,Stem层改为卷积核大小4,步长4的无覆盖卷积,这一改造将准确率从79.4%提升至79.5%。
DW卷积
在何恺明2017年的一篇论中提到:ConvNeXt的指导性原则是使用分组卷积,扩展模型的宽度。更具体的说,我们把瓶颈块的3×3卷积替换成了分组卷积。因为分组降低了FLOP(算力),我们加大了网络宽度以弥补神经网络容量的损失。
DW卷积:它先在每个通道上应用卷积核再融合所有通道,因此它的分组数等于通道数。DW卷积在MobileNet和Xception上很流行,而且它在功能上类似Transformer的自注意机制中的加权sum(只在每个通道内部做混合,可以减少FLOP并且提高精度)。
为了对齐Swin-T效果,我们把ResNet的通道数从64增加到了96,这些改造将准确率提升到了80.5%,同时FLOP也增加到了5.3G。
逆瓶颈
如图4(下面)中所示,Transformer块使用了逆瓶颈(MLP的宽度比输入大4倍)。有趣的是这种设计在MobileNet V2和后续几种卷积神经网络的设计中已经十分流行了。如下图所示,采用逆瓶颈FLOP减少了,精度却从80.5%增加到了80.6%。
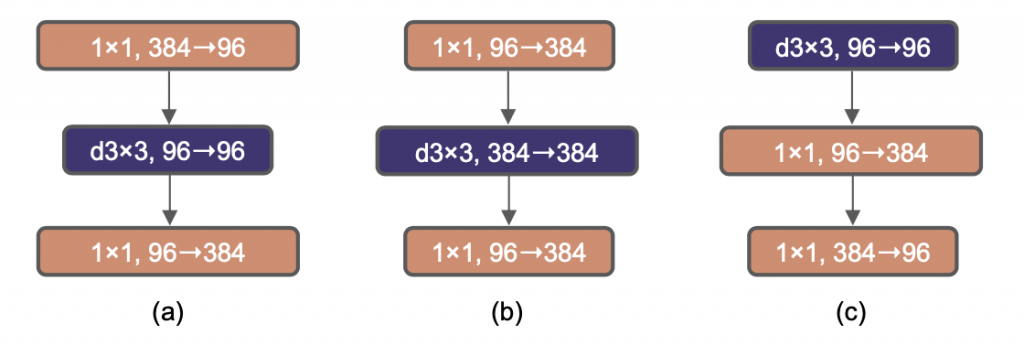
使用更大的卷积核
过去,VGGNet的“黄金”卷积核大小是3×3,而Transformer是非局部自注意力的,作用是每一层都有全局的感受野。Swin-T中引入了局部自注意力,使用了更大的7×7卷积核。因此本文也模仿它使用了7×7卷积核。
将上图的深度卷积向上移动了一层(c)。Transformer中的MSA层在MLP层的前面,因为我们用了逆瓶颈,复杂、低效的MSA层(大卷积核)通道数少(宽度小),而高效的1×1卷积将完成繁重的工作(宽度大)。这么改动以后FLOP降低到4.1G,精度下降到79.9%。
使用了7×7的卷积核,精度上升到80.6%。
微观设计
我们将在微观层面研究卷积神经网络和几个基于Transformer的神经网络的区别,尤其是在Layer设计上。
把ReLu替换成GELU
Gaussian Error Linear Unit可以认为是ReLu的更平滑的变体。在BERT、GPT-2和ViTs中用得都很好。把它替换上,精度保持不变(80.6%)。
更少的激活函数
相比卷积神经网络,Transformer神经网络的激活函数较少。Transformer有K/Q/V线性Embedding层,映射层,MLP中有两个线性层,请注意在MLP中只有一个层使用了激活函数。传统上ConvNet中每个卷积层后都会跟一个激活函数。仿效Transformer,除了两个1×1 conv层之间的激活层,我们去除了所有其他激活层。改完后精度提高了0.7%,至81.3%。
更少的归一化层
我们移除了两个BN层,只在1×1卷积层之前保留一个BN层,改造后精度提升至81.4%,精度已经超越了Swin-T。我们每个块的BN层比Transformer要少了,原因是我们发现:在块头增加BN层并不能提升精度。
用LN替换BN
精度提升到了81.5%
分离下采样层
在ResNet中空间下采样是通过在stage头的3×3,步长2残差块(和1×1,步长2 短连接)而Swin-T中是在stage中间直接加了一个独立的下采样层。我们模仿Swin-T,使用了2×2 步长2的空间下采样层。进一步的研究发现,在每次下采样的时候加上LN(或者BN)有助于稳定训练。比如在Swin-T中在每次下采样前加了LN,stem后加了LN,最终全局池化后加了LN。模仿它改造后精度可以提升到82%,高于Swin-T的81.3%。
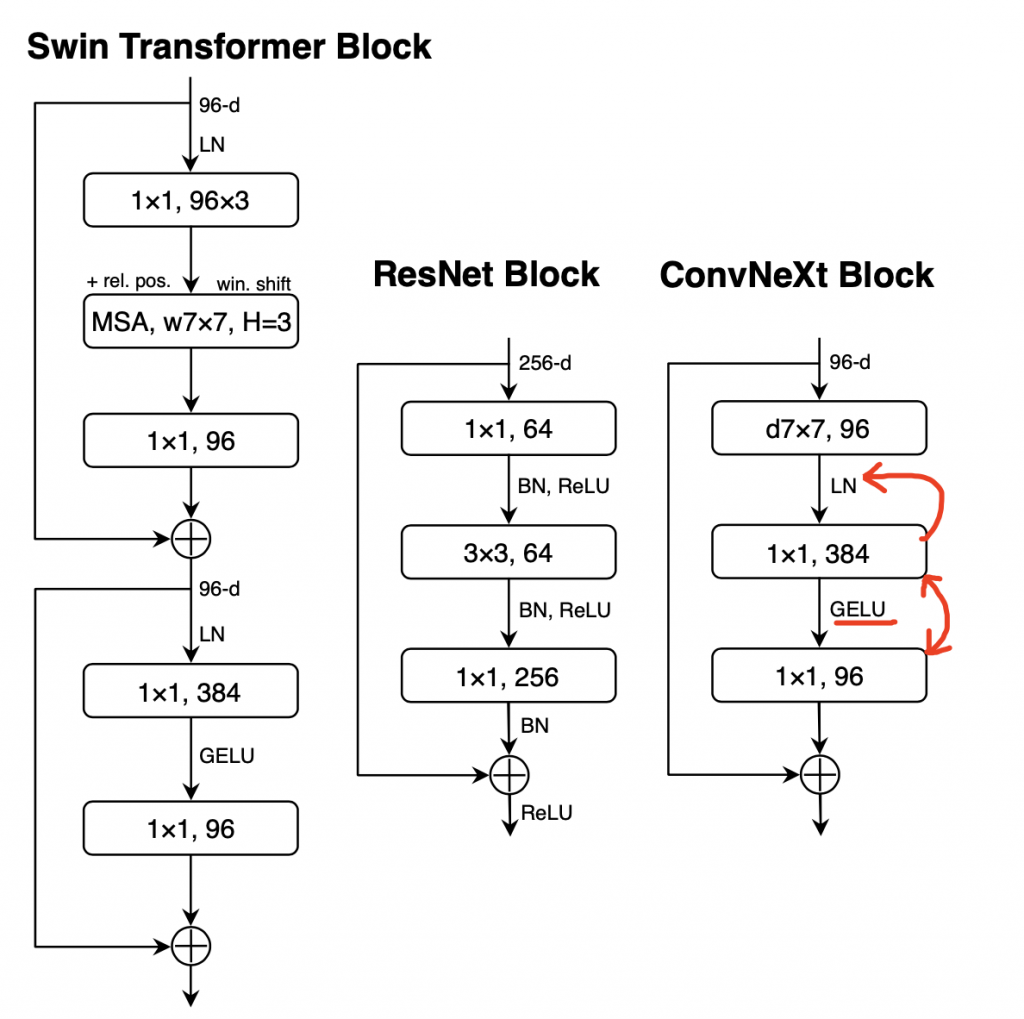
(图4)两个1×1 conv之间加了GELU,之前加了LN
总结
经过第一个“play through”,我们引出了ConvNeXt — 一个纯粹的卷积神经网络。所有改造都不是什么新奇的东西,并且不需要引入Swin-T中的某些特殊网络结构,例如:shifted window attention 或者 relative position biases。
这个结果虽然令人鼓舞,但是目前还只是在小规模数据上,而Swin-T的强大的scaling能力并没有被对比过。
ConvNeXt能否在目标检测、语义分割上和Swin-T竞争呢?
下一节,我们将在数据和模型大小上放大ConvNeXt,并在一系列的视觉识别任务上对这个问题进行进一步评估。