目录
可随意转载。Update2022.02.20
前言
基于信息论的算法是另外一个大类强化学习算法,它们属于off-policy和随机策略。我们常见的PPO算法属于on-policy算法,采样效率不高,在一些实际场景中不适用。DDPG属于off-policy和确定策略(deterministic policy)算法,采样效率高,但是确定策略只需要寻求其中一个解,可能陷入局部最优。来自伯克利大学的算法Soft Actor-Critic(SAC)属于这一类基于信息论的算法(off-policy + 随机policy)。官方算法论文有三篇:
2017年:Reinforcement Learning with Deep Energy-Based Policies (Soft Q-Learning)
2018年:Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
2019年:Soft Actor-Critic Algorithms and Applications
飞桨目前的实现是基于第二篇论文(2018年)
一、SAC算法原理
DQN算法的目标函数:

SAC算法的目标函数:

为什么除了奖励最大还要加上信息熵最大呢。因为信息论原理可以证明,信息熵越大,系统越混乱;缩小到RL领域,信息熵越大,动作越随机。SAC算法的基本思想是:最大化信息熵等同于尽可能的探索动作空间,获取最多的探索路径(trajectory)。
对比DDPG的deterministic policy,SAC的思路优点是什么呢?
- 随机policy可以学到更多路径,SAC算法可以作为其他高阶算法(HRL)的基础。
- 更强的探索能力。
- 更健壮。
其实在A3C/A2C算法中,已经加入了entropy。例如:飞桨PARL库代码(a2c.py)中:
# 分类分布
policy_distribution = Categorical(logits)
policy_entropy = policy_distribution.entropy()
entropy = paddle.sum(policy_entropy)
total_loss = (
pi_loss + vf_loss * self.vf_loss_coeff + entropy * entropy_coeff)Soft Q-Learning
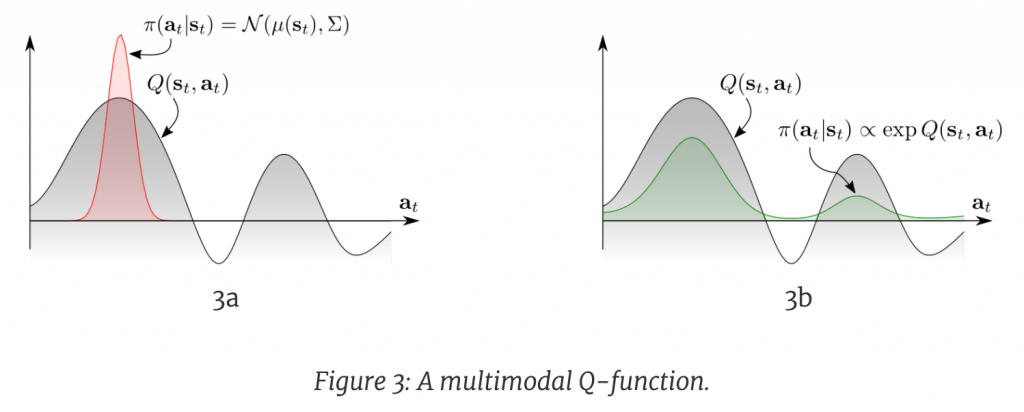
面对多模的(multimodal)的Q function,传统的RL只能收敛到一个选择(左图),而更优的办法是右图,让policy也直接拟合Q的分布。见下图:
二、飞桨的SAC库
2.1 机器人控制场景(Mujoco环境)
1. 下载模拟环境
可以直接使用pip上的Mujoco环境。因为它已经开源了。另外本文使用的是v3版本的环境 — Humanoid-v3。
2. 启动训练
# --env 是环境参数,表示启动哪一个训练环境
# --alpha 表示最大化熵和最大化奖励占学习的比例
python train.py --env Humanoid-v3 --alpha 0.23. main函数
env = gym.make(args.env)
# 这个参数是SAC算法特定的
env.seed(args.seed)
# 用到了PARL封装的连续动作类
env = ActionMappingWrapper(env)
# 状态空间和动作空间
obs_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
# 传统三件套model algorith agent
model = MujocoModel(obs_dim, action_dim)
algorithm = SAC(
model,
gamma=GAMMA,
tau=TAU,
alpha=args.alpha,
actor_lr=ACTOR_LR,
critic_lr=CRITIC_LR)
agent = MujocoAgent(algorithm)
# Q-Learning传统的rpm
rpm = ReplayMemory(
max_size=MEMORY_SIZE, obs_dim=obs_dim, act_dim=action_dim)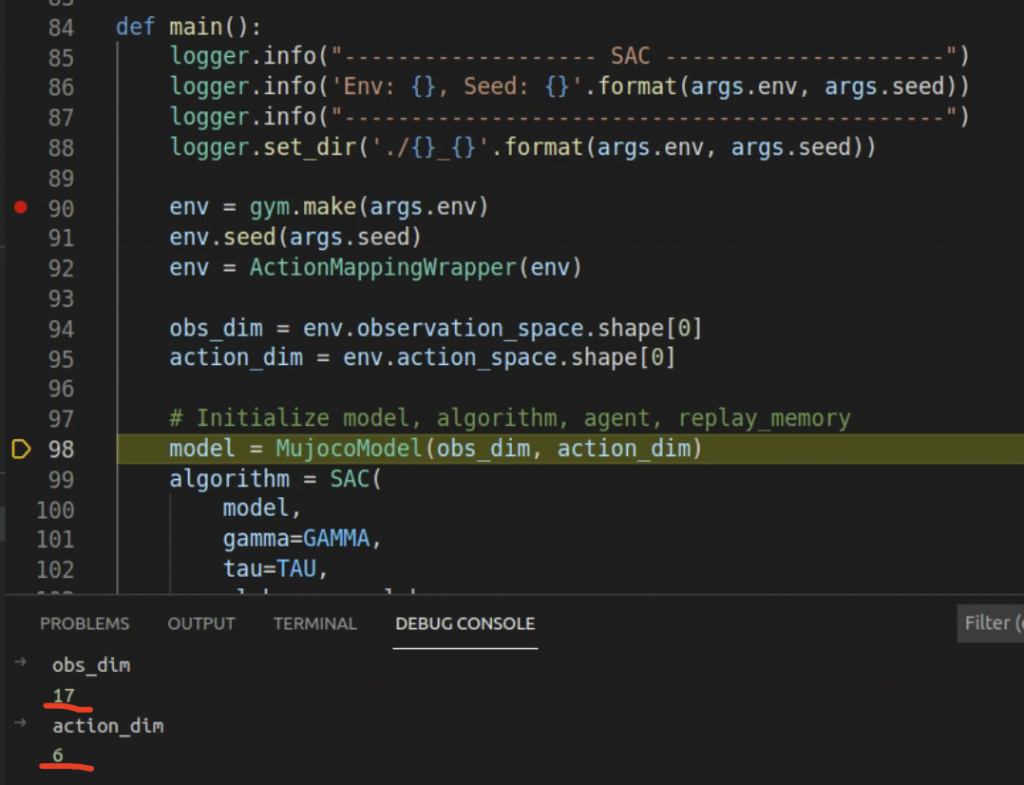
从状态和动作空间维度看,这个例子是一个非常简单的RL场景。
4. 训练函数run_train_episode
def run_train_episode(agent, env, rpm):
while not done:
# 选择动作
action = agent.sample(obs)
# step函数
next_obs, reward, done, _ = env.step(action)
# 写ReplyMemory
rpm.append(obs, action, reward, next_obs, terminal)
...
# 预填充一些再开始学习
if rpm.size() >= WARMUP_STEPS:
batch_obs, batch_action, batch_reward, batch_next_obs, batch_terminal = rpm.sample_batch(
BATCH_SIZE)
# 学习,注意这里的learn没有返回值
agent.learn(batch_obs, batch_action, batch_reward, batch_next_obs,
batch_terminal)
return episode_reward, episode_steps5. 网络模型mujoco_model.py
5.1 Actor_Model
动作网络是最简单的两层线性+Relu网络。
class Actor(parl.Model):
def __init__(self, obs_dim, action_dim):
super(Actor, self).__init__()
self.l1 = nn.Linear(obs_dim, 256)
self.l2 = nn.Linear(256, 256)
self.mean_linear = nn.Linear(256, action_dim)
self.std_linear = nn.Linear(256, action_dim)
def forward(self, obs):
x = F.relu(self.l1(obs))
x = F.relu(self.l2(x))
act_mean = self.mean_linear(x)
act_std = self.std_linear(x)
act_log_std = paddle.clip(act_std, min=LOG_SIG_MIN, max=LOG_SIG_MAX)
return act_mean, act_log_std5.2 Critic_Model
策略网络是双Q网络,三层线性+两层Relu
class Critic(parl.Model):
def __init__(self, obs_dim, action_dim):
super(Critic, self).__init__()
# Q1 network
self.l1 = nn.Linear(obs_dim + action_dim, 256)
self.l2 = nn.Linear(256, 256)
self.l3 = nn.Linear(256, 1)
# Q2 network
self.l4 = nn.Linear(obs_dim + action_dim, 256)
self.l5 = nn.Linear(256, 256)
self.l6 = nn.Linear(256, 1)
def forward(self, obs, action):
x = paddle.concat([obs, action], 1)
# Q1
q1 = F.relu(self.l1(x))
q1 = F.relu(self.l2(q1))
q1 = self.l3(q1)
# Q2
q2 = F.relu(self.l4(x))
q2 = F.relu(self.l5(q2))
q2 = self.l6(q2)
return q1, q22.2 模拟汽车驾驶场景(CARLA环境)
1.CARLA环境下载
2.创建解压缩目录(因为下载的文件是散开的)
mkdir CARLA_0.9.6
tar -zxf CARLA_0.9.6.tar.gz -C CARLA_0.9.63.编辑~/.bashrc,增加下面这一行:
export PYTHONPATH="${YOUR_FLODER}/CARLA_0.9.6/PythonAPI/carla/dist/carla-0.9.6-py3.5-linux-x86_64.egg:$PYTHONPATH"4.克隆飞桨PARL帮我们对接好的python操作CARLA游戏项目源码并安装:
$ git clone https://github.com/ShuaibinLi/gym_carla.git
$ cd gym_carla
$ pip install -r requirements.txt
$ pip install -e .5.检查是否安装成功:
pip list | grep gym_carla如果报remote的类找不到gym_carla, 请执行pip install -e . 然后再重新启动XPARL。
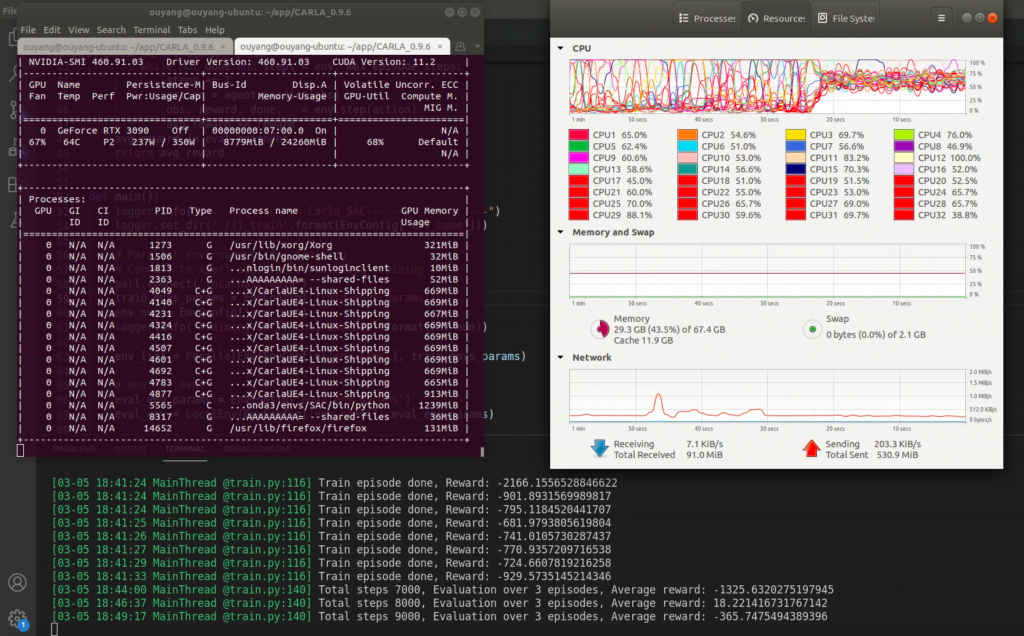
6. 分别开启多个游戏进程
编写shell脚本开启多游戏进程:
DISPLAY= ./CarlaUE4.sh -opengl -carla-port=2021 &
sleep 10
...7. 启动XPARL做并行训练
8.进入PARL项目的examples/CARLA_SAC目录并执行:
开启了10个无窗口游戏环境:8个做训练用,1个做评估用,1个做测试用。如下图:
主要代码逻辑如下:
def main():
# 连接XPARL集群
parl.connect('localhost:8080')
...
# 创建多个游戏环境
env_list = ParallelEnv(EnvConfig['env_name'], train_envs_params)
...
# 三件套
model = CarlaModel(obs_dim, action_dim)
algorithm = SAC(
model,
gamma=GAMMA,
tau=TAU,
alpha=ALPHA,
actor_lr=ACTOR_LR,
critic_lr=CRITIC_LR)
agent = CarlaAgent(algorithm)
# rpm,参考Q-Learning
rpm = ReplayMemory(
max_size=MEMORY_SIZE, obs_dim=obs_dim, act_dim=action_dim)
# 重置一下环境
obs_list = env_list.reset()
# 开启循环训练
while total_steps < args.train_total_steps:
action_list = [agent.sample(obs) for obs in obs_list]
next_obs_list, reward_list, done_list, info_list = env_list.step(action_list)
...
# 循环写入rpm
if not info_list[i]['timeout']:
rpm.append(obs_list[i], action_list[i], reward_list[i],next_obs_list[i], done_list[i])
...
# 暖机后开始学习
batch_obs, batch_action, batch_reward, batch_next_obs, batch_terminal = rpm.sample_batch(BATCH_SIZE)
agent.learn(batch_obs, batch_action, batch_reward, batch_next_obs,batch_terminal)
...
# 保存agent,这一步是SAC算法特别的地方
if total_steps > int(1e5) and total_steps > last_save_steps + int(1e4):
agent.save('./model/step_{}_model.ckpt'.format(total_steps))
last_save_steps = total_steps
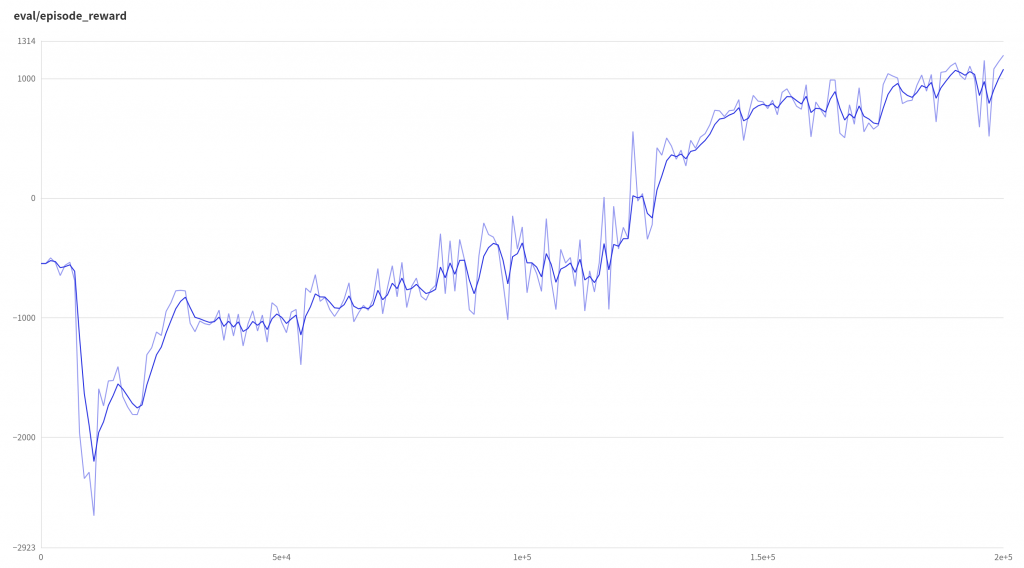
训练结果
评估结果
进入CARLA主目录,执行下面命令,开启游戏窗口,评估模型:
$ ./CarlaUE4.sh -windowed -carla-port=2039
运行PARL/examples/CARLA_SAC/evaluate.py, 效果如下
注意Ubuntu录制的mp4因为格式细节问题,在Windows和Mac系统打不开,需要使用以下命令转换:
ffmpeg -y -i input_file.mp4 -c:v libx264 -c:a aac -strict experimental -tune fastdecode -pix_fmt yuv420p -b:a 192k -ar 48000 output_file.mp4