目录
可随意转载!Update2022.05.17
前言
通用人工智能(AGI)一直以来是人类的梦想,Deepind又一次走到了拓荒的最前列,它发明了Gato — 一种多模态、多任务、多领域的通用策略。只需要一个神经网络、一种参数权重就可以玩Atari、标注图片、聊天、机器人控制。下面是论文原文。
一、简介
使用多模态的神经网络模型有巨大的好处,可以避免手调参数,可以大大增加训练数据。另一个角度看,从科学上通用模型也比专用模型能更好的利用计算资源。
本文我们介绍一个通用人工智能体—Gato,它可以做人机对话、标注图片、机器人控制、玩Atari游戏、虚拟环境中导航、接受指令等等。
众所周知,没有任何智能体可以超越它的训练分布,本文验证了一种假设我们在大量数据上训练的通用智能体只需要很少的额外数据就可以在新的任务上获得成功。我们假设有这样的智能体:仅仅通过缩放数据、训练轮数和参数规模,在保持性能的同时不断扩大训练分布,去努力覆盖更多任务、行为和兴趣。其中自然语言是跨领域训练的基础。
Gato的目标是训练的模型可以控制真实的机器人,目前我们的模型参数是12亿。随着硬件的提高和模型架构的改进,还能涨点。为了简单,Gato使用了监督学习,当然并没有限制它不能用在线和离线强化学习。
二、模型
Gato的指导设计原则是尽可能广泛地使用各种相关数据,包括图像、文本、本体感觉、关节力矩、按钮按下和其他离散和连续的观察和行动。为了方便计算机处理这些多模态数据,我们把数据拍平成了token,然后就可以上Transformer了。在部署期间,对token进行采样,根据上下文,它们被组合成对话回应、字幕、按键或其他动作。在以下小节中,我们将介绍Gato怎么做token、网络架构、loss函数,以及部署。
2.1 做token
有很多种做token的方法,比如使用计算机的二进制字节流,我们探讨一种在当前的软硬件条件下适用Gato的最佳方法。
- 文字使用了SentencePiece算法,把32000个单词放入了Integer(范围:0~32000)
- 图片用了ViT算法中的16X16 patches,归一化到-1 ~ 1之间并除以4(patches 16个平方根)
- 离散值:比如Atari游戏中的按钮点击事件被token成了一串Integer(范围:0~1024)
- 连续值:先拍平成一行Float数值并归一化到-1 ~ 1之间,然后统一放入到1024个桶中,然后再偏移到32000~33024范围内。
做完token以后,我们使用下面的规则排序:
- 文本做token的顺序与原始输入文本的顺序相同。
- 图片的patches安光栅顺序做token
- 张量用行的顺序做token
- 嵌套结构按key的字典顺序做token
- 智能体的时间步按: obs+分割符+action
- episode中的时间步按:时间先后顺序做token
2.2 token embedding和设定输入目标
经过上面的步骤我们可以对输入进行embedding,我们对每个token使用参数化的embedding函数f (·; θ e )生成模型的输入。要对多模态的输入进行有效的学习,需要针对不同输入来源做处理:
- 文本类型输入:把输入通过查找表嵌入到经验向量空间。可学习的position encoding依据时间步的先后顺序也添加了进来。
- 图片类型输入:用上一步生成的patches用ResNet处理后得到向量(每个patch一个),图片内的position encoding我们也通过可学习的方法添加进来
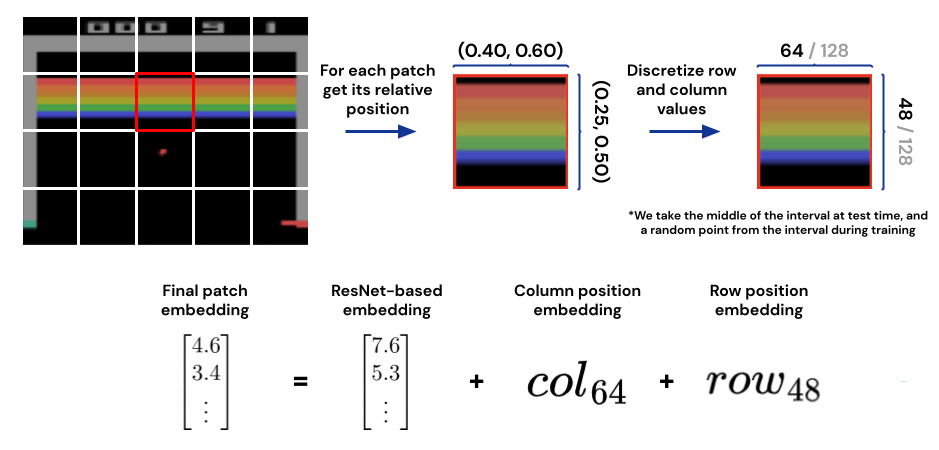
在自回归建模中,每一个token都可能是前面tokens的潜在目标。文本token,动作token都可以直接设定为目标。图片和智能体的obs在Gato中不会被预测,因此他们的目标在计算损失函数的时候要用Mask掩盖起来。