目录
可随意转载! Update2022.08.06
前言
近几年,GAN领域发展速度很快,新的论文和产业实践层出不穷。本文用Paddle框架从源码级别复现了GAN系列算法,以供深入理解和产业实战。
一、GAN原理
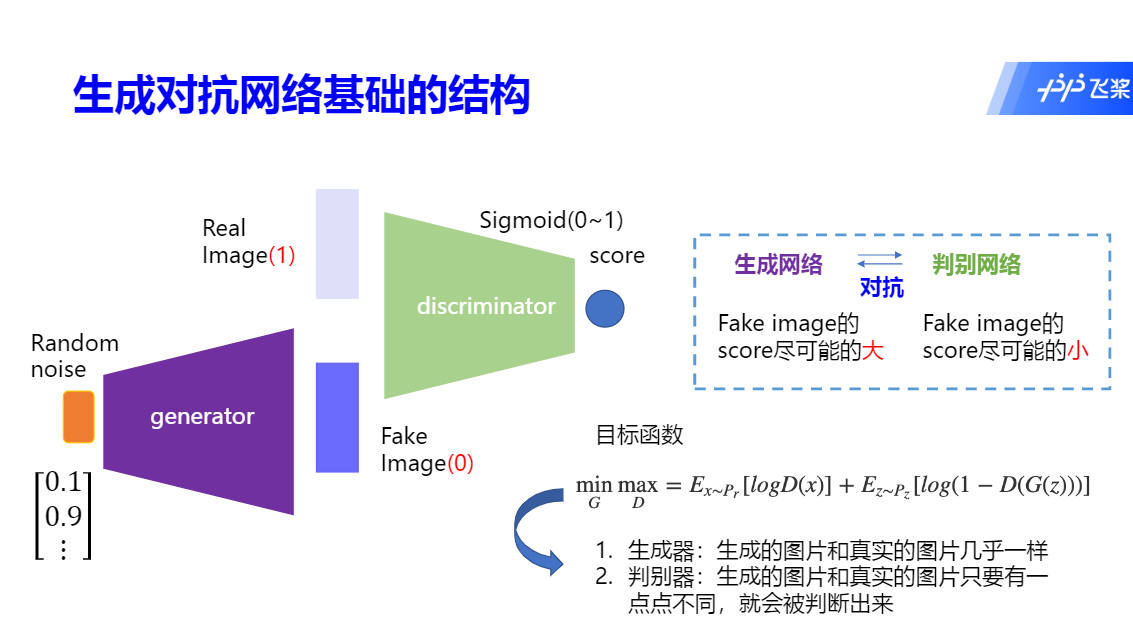
Generative Adversarial Network,生成对抗网络。采用了如下图的二元博弈(目标函数:最大化D的同时,最小化G)迭代计算找图片的纳什均衡。
二、GAN入门基础
1. GAN算法
最早的GAN算法作者是Ian Goodfellow,算法原理如下:
- 已知图片判别器D:真图输入D,返回真;噪声(noise)输入D,返回假
- 算法目标是:找到一个神经网络G,能够生成图片并让D返回真(骗过D)
- 这时提高难度,假定D也是神经网络,且参数未知,怎么解决?
- 万能的神经网络又一次被拿出来解决这个“鸡生蛋,蛋生鸡”的问题
- 只要把真图+noise一起输入D、G网络进行训练(网络参数),输出就是GAN模型
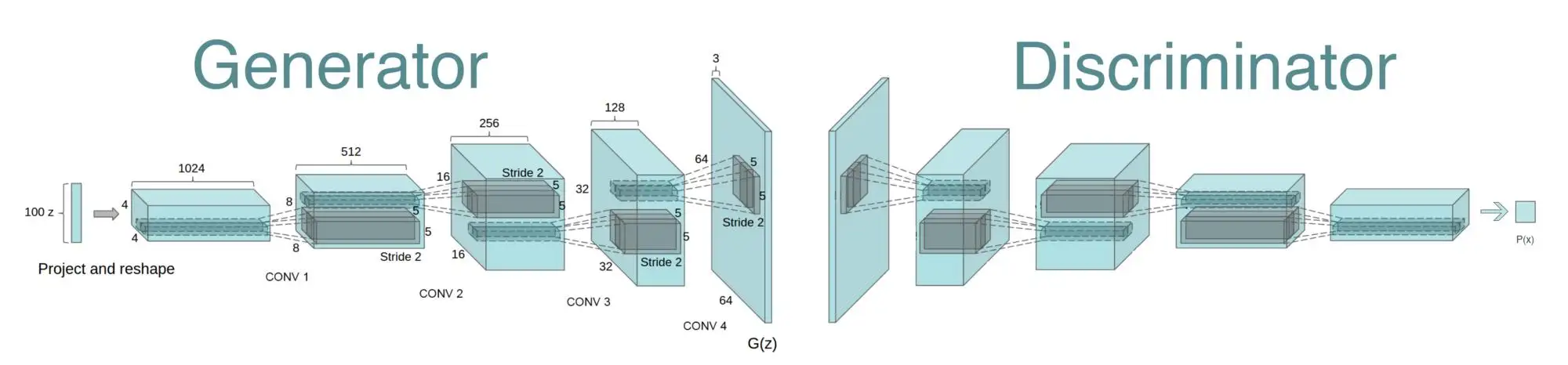
2. DCGAN算法
深度卷积GAN,特点:全卷积网络(无pooling),无监督学习。解决从大量无标签图片中学到表示(representation)的问题。
DCGAN得到了Ian Goodfellow等人的帮助。
作者在两个分类任务上与当时SOTA的算法做了比较:
- CIFAR-10数据集上与KMeans做比较
- SVHN数据集上做到了SOTA
这篇论文还有一个重要贡献是:它在第六章探讨了DCGAN网络的可解释性,这是后面latent space相关算法的理论基石。
6.1 走入隐空间
在Z空间中随机选了9个点做渐变(比如从0.1 –> 0.6 中间做插值)。可以看到Fig4-Line6(请查看原论文)从没有窗户逐渐变成了有窗户。第10行TV变成了窗户。因为生成图片是渐变的,因此可以断定DCGAN学到了表示而不是仅仅记住了训练图片。
6.2 可视化D网络特征
作者取了D网络最后一个卷积层的头6个特征,注意,bed的特征很少(在论文使用的LSUN数据集中,bed是很核心的物体)。作者还用了未经训练的随机过滤器作比较。发现头6个特征确实是提取的语义(不含bed,bed可能在其他特征输出中)。 如下图:

6.3 操纵G网络表示(representation)
6.3.1 遗忘某些对象
为了深入探查表示(representation),我们从G网络中移除了对象window。在150个样本数据中,手绘了52个window bbox。在第二层卷积上使用逻辑回归预测有没有window features(bbox中权重为正数,随机取样图片的其他部分权重为负数)。把所有权重为正的样本(200处)从空间位置移除,再随机生成新的样本。
在论文的Fig6中显示了移除掉window后,模型会用其他对象代替。这个实验证明了DCGAN在解耦features方面确实不错。
6.3.2 在人脸样本上做矢量计算
举例: NLP里面:国王,男人,女人,女王。这几个词(vector)embedding之后距离应该是接近的。在GAN的Z分布中也类似。作者发现单个样例不稳定,但是组合3个样例就非常稳定了,例如:
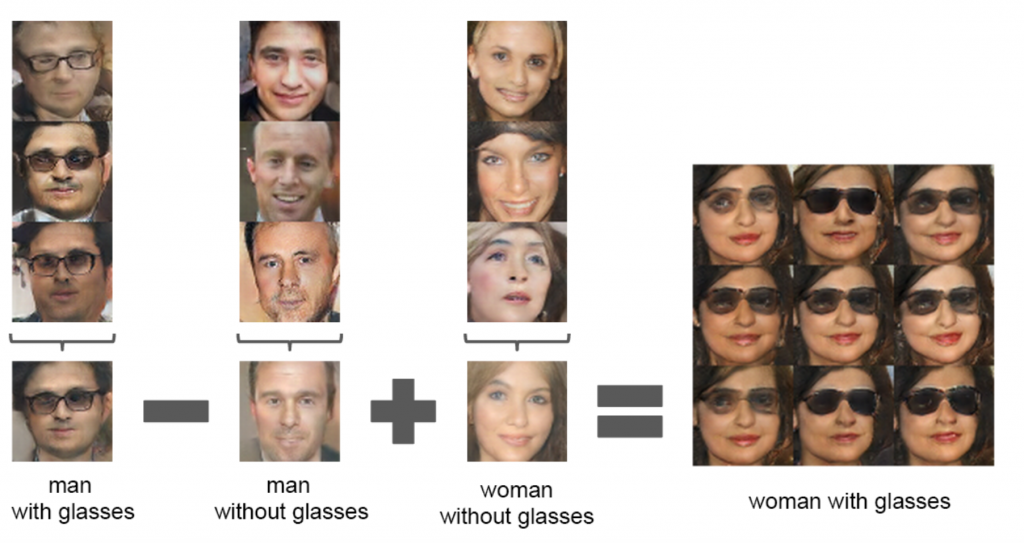
举例:人脸方向实验
作者取了4张图然后做了向量平均(下左),同理下右。简单在两个向量上做算术插值,可以看到人脸转向的过程(说明脸部方向feature被解耦出来了)。

这两点从实验中证明了z空间的feature map是解耦的,是可控制的。
三、StyleGAN系列
1. StyleGAN
StyleGAN发展简介:
StyleGAN(NVIDIA 2018) --> StyleGAN2(NVIDIA 2019) --> StyleGAN2_ADA(NVIDIA 2020)
--> pixel2style2pixel(pSp)(E Richardson 2021) 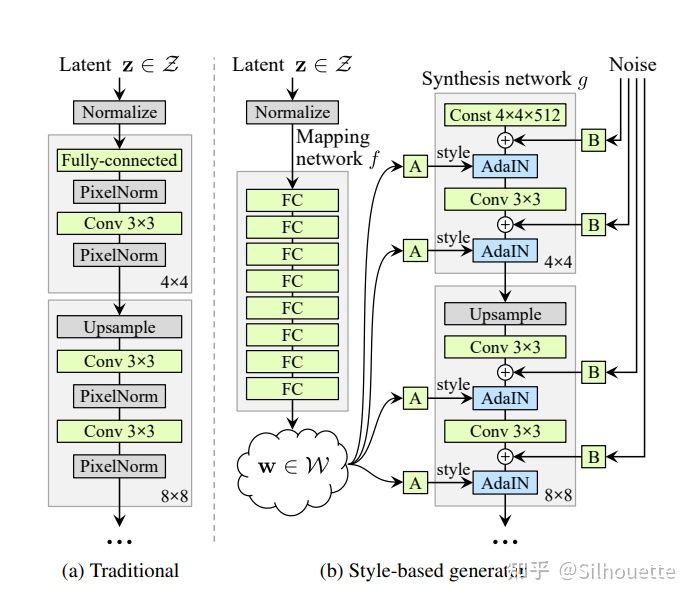
StyleGAN不仅仅是当年的SOTA论文,而且在特征空间解偶研究上开创了新天地,提出了GAN的效果评估标准:PPL、FID。 知乎大神详解StyleGAN&StyleGAN2
为什么要把Z空间转换为W空间?
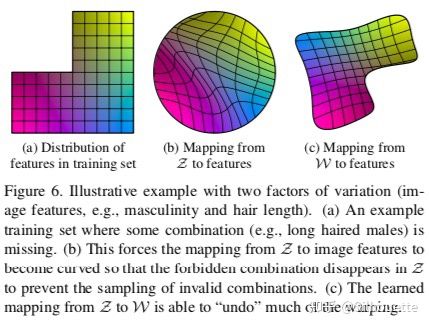
传统GAN直接把Z输入生成网络,这种方式隐含了条件:Z数据分布和训练数据相同。但是实际情况并不是这样,比如:我们期望生成图片 –> 男生+长发,它是二维的特征,如图a(它的数据分布不是正方形)。而我们一般要求训练数据分布均匀。因此使用传统GAN直接把Z输入生成网络显然无法表示这个小概率数据的分布。论文解释如下(其中a表示男生+头发长的数据分布,b表示被传统GAN扭曲后的数据分布,c表示把Z空间转换为W空间的数据分布):
为什么W空间输出通道数为18?
18通道计算公式是: log21024*2 -2 = 18。 其中1024是图片的分辨率。 实验证明w空间的低通道(低分辨率)对应高级style,比如脸方向和头发风格,w空间的高通道(高分辨率)对应细节style,比如头发颜色。
Affine具体做了什么?
Perceptual Path Length (PPL, 感知路径长度)
Perceptual loss主要用于分析图像之间高级特征的相似度,简单而言就是将两张待分析的图像送进一个预训练的模型里,得到各自的高级特征,随后计算特征之间的损失。通常该模型使用VGG架构,故又称为VGG loss,更关注高级特征,而不是某些像素的差别。
一个好style解耦是:在空间Z里随意找两个 z1,z2,取它们的插值t 生成图片应该和z1,z2生成的图片的Perceptual distance越小越好。
linear separability (线性可分性)
对于二分属性(男女),模型也要线性可分。
2. StyleGAN2
由于StyleGAN在神经网络结构方面的深入广泛研究,目前StyleGAN2算法已经成为了许多GAN系列算法的基础网络结构。比如pixel2style2pixel算法把原始图片编码成style vector并直接使用StyleGAN2的网络结构。
改进了网络结构解决了水滴状伪影
略
减少了正则化频率
提升性能
Path Length Regularization
作者希望在w向任何一个方向变化固定数值,图像属性发生的变化也是固定的(其实就是w的改变和方向无关性)。
解决Progressive Growing 网络问题
解决了增长式网络(先训练低分辨率Layers,在逐步增加高分辨率Layers)导致脸部特征变化不连续的问题。
图像映射回到latent space
给一张图片,我们可以将它embedding回latent space,修改latent code,再重新生成图片,达到编辑图像属性的目的(后续工作就是pSp这篇论文)。
3. StyleGAN2 ADA
可以在小数据集上使用的算法。pytorch版本官方源码
PaddleGAN中没有实现这个算法。
StyleGAN2的训练集至少要万/十万量级图片,否则就会过拟合,论文通过实验数据(FID指标)详细证明了这一点。但是大数据集在很多应用场景是很难做到的。我们自然想到了图像增强技术,就像我们在图片分类算法中那样做。经过实验,作者发现如果简单把图片做随机增强然后输入G网络中,那么经过G网络生成的数据分布会发生变化,这种现象被作者称为:leaking。
因此,作者采用了D增强的方法,也就是不改变G,而是修改了D网络。
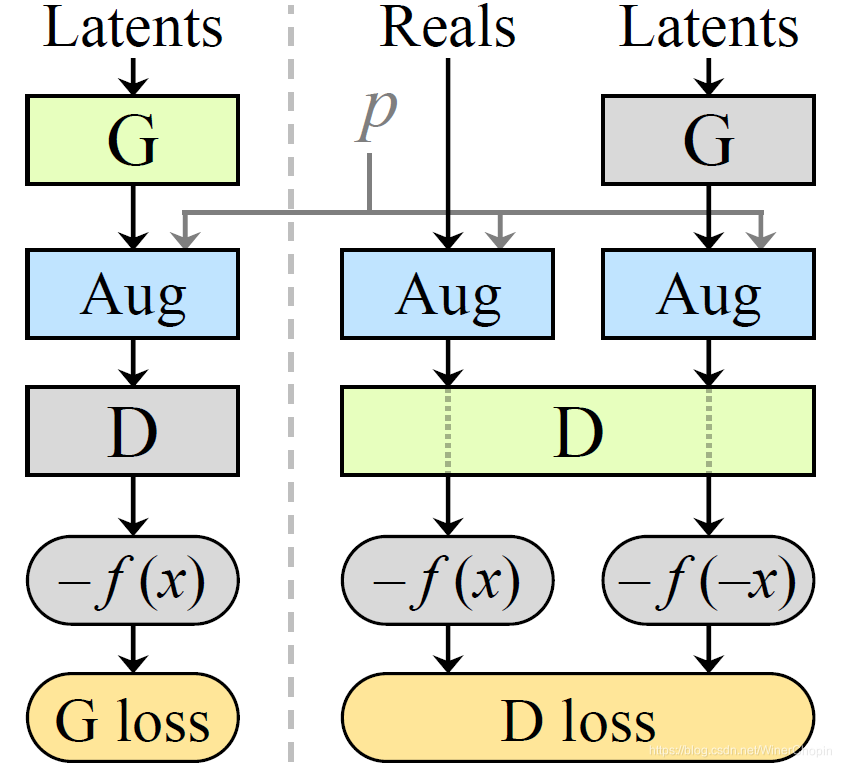
作者经过理论推导和实验得出了结论:随机增强概率p<0.8时,leaking不会发生(我的理解是:真实images输入网络次数100次,增广图片只要输入网络次数不超过80次,D网络是可以透过增强后的数据判别源数据分布)。作者取名叫:the practical safety limit
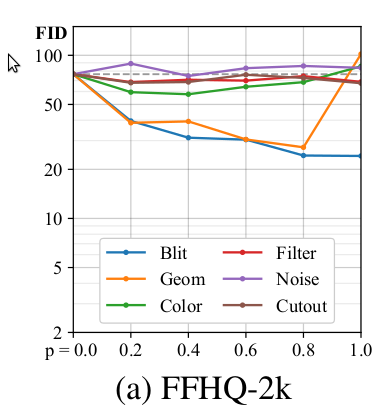
下图每条曲线是采用不同增广方法FID值(越小越好),说明在小数据量下,某些增广方法可以显著减少FID。
作者又做了一些实验:调整p值
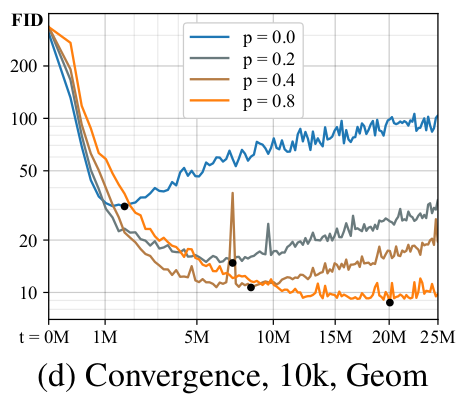
最终提出了本论文的方法论:ADA(Adaptive Discriminator Augmentation)。
如何使用自己的小数据集(2K) finetune 模型?
作者使用CELEBA-HQ 256X256预训练模型(或者LSUN DOG 256X256预训练模型)可以很好对FFHQ数据做finetune。
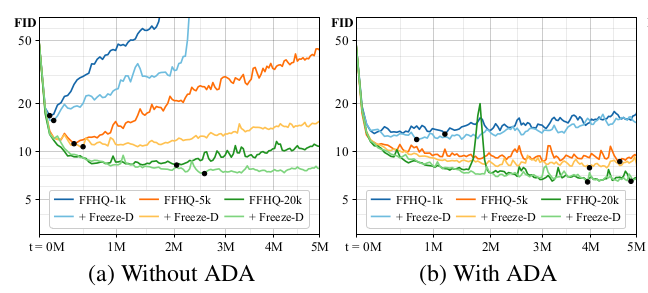
作者引入了Freeze-D:冻结D模块的高分辨率层。另外,作者发现在小数据集上用FID评估是不好的,引入了新的评估指标KID(kernel inception distance)。
4. Pixel2Style2Pixel(pSp)
来自论文:《Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation》
解决图像转换(StyleGAN Inversion)任务一般有两类方法:
- 优化latent code
- 写Encoder(类似:ALAE IDInvert)
pSp引入的一种新的encoder,直接生成W+空间然后输入到StyleGAN的生成器G中
AIStudio源码复现(复现了预测部分代码)
5. SemanticGAN
这篇论文来自NVIDIA多伦多研究所(和张量研究所),改造了StyleGAN2,在生成器和判别器网络种增加了semantic分支,可以同步生成语义分割图。
它借鉴了pSp,引入了FPNEncoder。
6. EditGAN
这篇论文来自NVIDIA多伦多研究所(和张量研究所),在SemanticGAN基础之上,引入了pixel_classifier。
四、Conditional GAN系列
这一系列算法的特点是需要成对数据(paired data)。人为改变输入条件,控制最终输出结果。
1. CGAN
条件GAN(conditional GAN)最基础的算法。条件可以是image,label,voice,sequence等等。
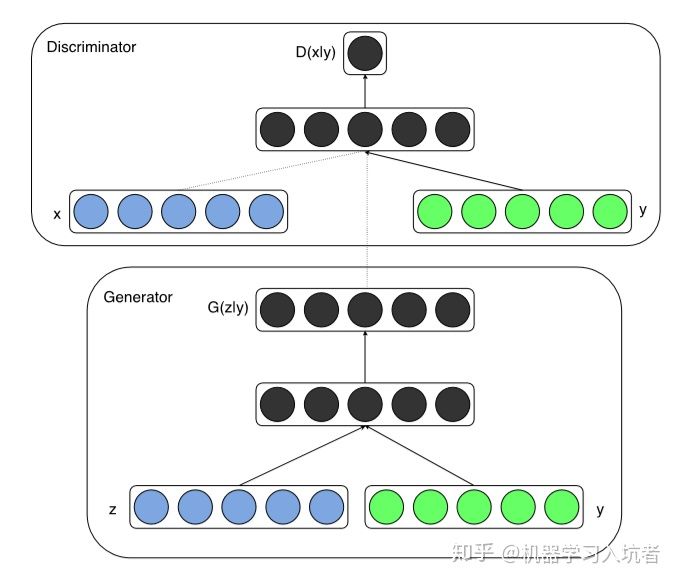
通过增加条件输入y来影响GAN的输出。输入y常常使用semantic label image/map。CGAN虽然简单,但是它为后续许多算法开启了一扇大门,科学家们开始研究如何控制GAN的输出。比如下面的StyleGAN。
2. Pix2Pix
这篇算法来自伯克利大学,特色是理论很强。
与StyleGAN系列不同,这一系列是CGAN算法的延伸,也需要成对数据,它主要关注pixel级别的image2image转换(还包括semantic2image、edge2image、图片上色)。
- 采用U-Net:在Encoder-Decoder网络基础上增加了多级skip connections,作用是shuttle info(比如传递颜色信息)。
- 采用L1 loss来保留原图的低频细节。
- 采用了patchGAN来保留原图的高频细节。把原图切分成N x N份,然后对每个patches判别真假,然后平均后得到整图的真假。
- 去掉了z噪声,使用dropout来增加输出的随机性。
为了保持图片pixel级一致,它采用了CGAN特色处理方法,代码如下:
# we use conditional GANs; we need to feed both input and output to the discriminator
fake_AB = torch.cat((self.real_A, self.fake_B), 1)
pred_fake = self.netD(fake_AB.detach())3. Pix2PixHD
对Pix2Pix算法的改进:
- 使用了coarse-to-fine网络,在多个分辨率上同时学习
- 配合提出了多尺度判别器
- 提出了物体边界图(Instance boundary map)
4. GauGAN(SPADE)
语义图(semantic labels)生成算法。
它的主要贡献是对Pix2PixHD算法进行了改进:
- 解决Norm Layer丢失图片细节问题,提出了新的Norm Layer: SPADE