目录
可随意转载! Update2022.07.19
前言
GAN系列算法要大数据、大算力,在前面课程中讲到了大算力的解决方案。本文作者采用监督学习生成大数据集,成功解决了GAN算法依赖大数据的问题,妙啊!
论文原标题:《DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort》
论文作者的想法究竟是什么呢?
作者观察到大量的数据中,如果我们能自动给它们标注语义(semantic)信息,那么算法可以更高效的学习。因此作者采用给10+图片(比如:头像)详细标注上语义分割信息,然后让算法根据这些语义分割信息自动去标注其他图片,把GAN大数据依赖问题,通过成熟的监督学习+语义分割网络转化成了一个小标注数据上的半监督学习问题。
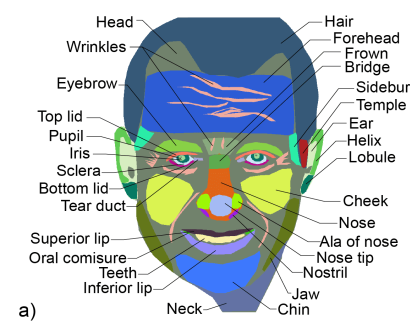
一、简介
DatasetGAN是一种对比学习(contrastive learning)。作者发现GAN系列算法需要依赖语义(semantic)特征,作者通过很少的语义标注图片数据就可以训练一个decoder,可以生成无限的带语义(semantic)标签的数据集。DatasetGAN不同于其他对比学习的地方是:它没有最小化对比损失函数(contrastive losses),而是用了GAN算法特征图(feature maps)中的语义知识。
注:对比学习 — 通过无监督的方式在成对数据上最小化特征的对比损失函数(contrastive losses)。
二、方法
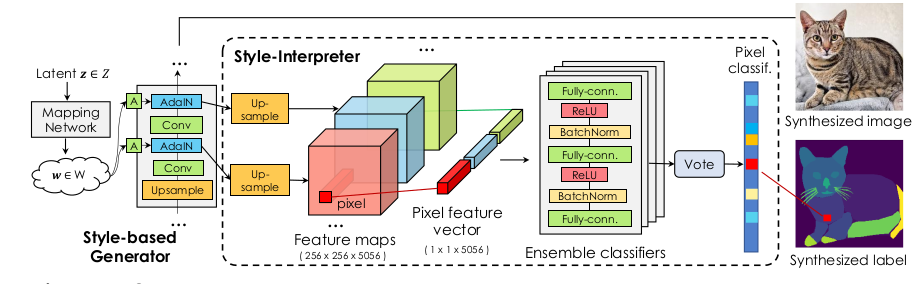
DatasetGAN用来生成成对的图片+标签数据。细化开就是:图片+语义分割 或者图片+关键点预测。
作者发现GAN的G算法在高维度的latent space中高度依赖语义分割知识。然后他就想到了利用少量的人类先验知识,所以就转化成了半监督学习。算法利用了StyleGAN的G,在它的特征向量上面写了一个MLP分类网络,取了个名字叫:”Style Interpreter”,用来匹配人工设置的语义标签。一旦”Style Interpreter”训练好,我们就把它当成了StyleGAN的语义标签生成分支(器)。
DatasetGAN用的是StyleGAN网络,而不是StyleGAN2网络(因为包含AdaIN子网络)。如上图,作者把K个AdaIN网络输出的特征图旁路了一份出来,称为:{S 0 , S 1 .., S k }。然后全部上采样到Sk的维度大小(1024),然后concat成一个3维向量,我们对这个三维数据使用简单的MLP分类网络预测标签。
注:在DatasetGAN的升级版本EditGAN中支持StyleGAN2。
三、应用
它可以做语义分割、关键点检测、单目3D重建。总之这篇论文和代码还是很有复现价值的。
四、源码解读
4.1 数据准备
- 下载数据集放入 datasetGAN/dataset_release中
- 下载预训练模型,放入checkpoints/stylegan_pretrain
- 把vscode的项目根目录指向datasetGAN_release/datasetGAN
- 虽然model和utils都在项目上一级目录,但是因为它们已经编译好了,还是可以被程序自动识别到
4.2 训练
python train_interpreter.py --exp experiments/<exp_name>.json 训练人脸的模型需要超过160G的内存,就算改配置的batch_size也没用,应该是代码设计的问题。
4.3 配置文件
{
"exp_dir": "model_dir/face_34",
"batch_size": 64,
"category": "face",
"debug": false,
"dim": [512, 512, 5088],
"deeplab_res": 512,
"number_class": 34,
"testing_data_number_class": 34,
"max_training": 16,
"stylegan_ver": "1",
"annotation_data_from_w": false,
#### 人工标注的imagex和对应的maskx.npy成对数据
"annotation_mask_path": "./dataset_release/annotation/training_data/face_processed",
"testing_path": "./dataset_release/annotation/testing_data/face_34_class",
"average_latent": "./dataset_release/training_latent/face_34/avg_latent_stylegan1.npy",
#### 也看不出来是个啥玩意
"annotation_image_latent_path": "./dataset_release/training_latent/face_34/latent_stylegan1.npy",
#### stylegan的预训练文件
"stylegan_checkpoint": "./checkpoints/stylegan_pretrain/karras2019stylegan-celebahq-1024x1024.for_g_all.pt",
"model_num": 10,
"upsample_mode":"bilinear"
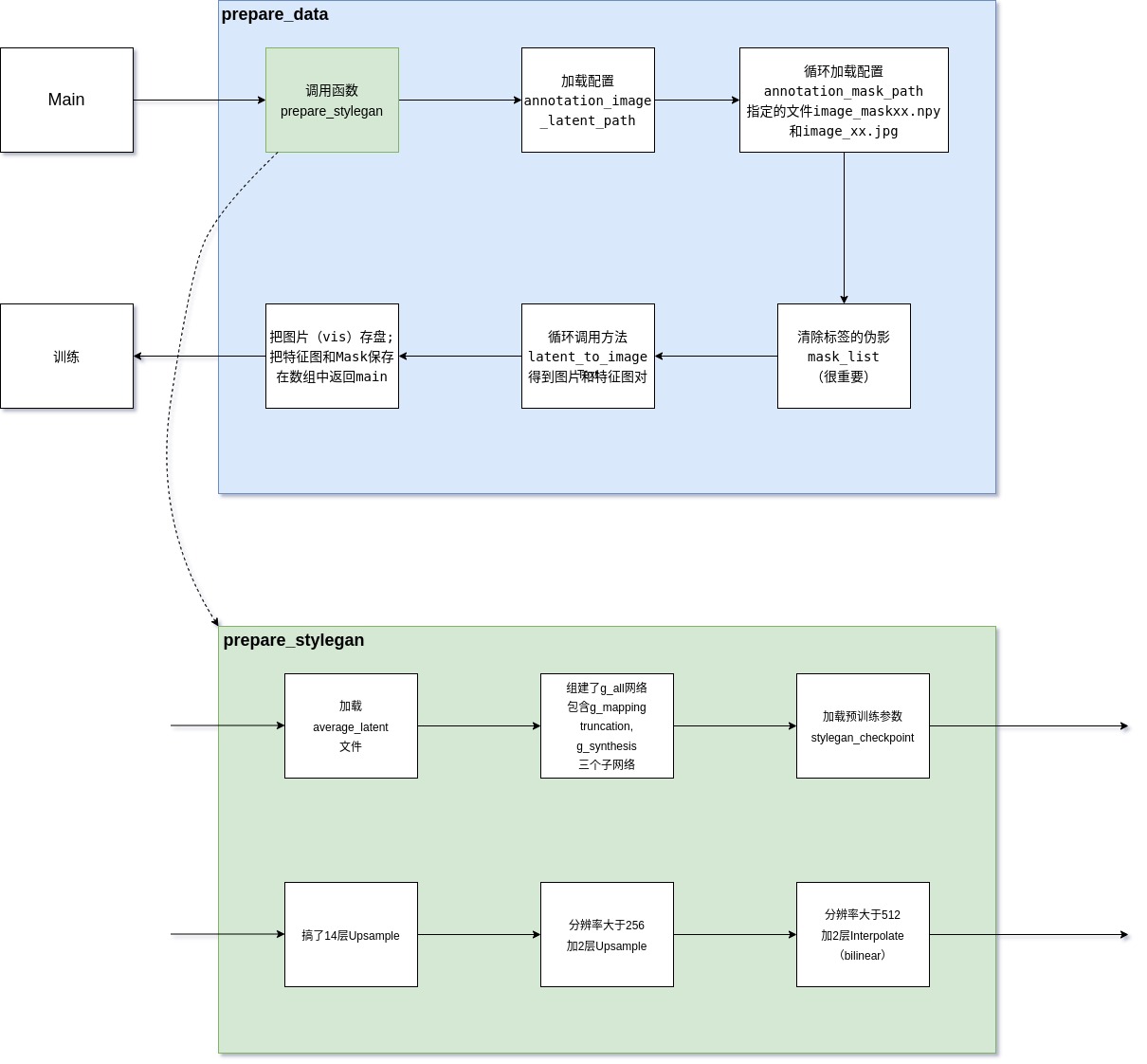
}4.4 prepare_data方法图解
4.5 算法精读
a)prepare_data精读
返回数据(all_feature_maps_train_all)很大,然后作者又包了一层,如下图:
train_data = trainData(torch.FloatTensor(all_feature_maps_train_all),
torch.FloatTensor(all_mask_train_all))这个地方会爆内存。修改后跑1024×1024的face_34高分辨率图片训练,内存占用40G左右。
latent_all = np.load(args['annotation_image_latent_path'])
# latent_all.shape
# torch.Size([16, 512])
# 循环16次初始化im_list和mask_list
# len(im_list)=16 len(mask_list)=16
# im_list[0].shape=(512,512,3) mask_list[0].shape=(512,512) all_mask.shape=(16,512,512)b) prepare_stylegan精读
avg_latent = np.load(args['average_latent'])
# avg_latent.shape
# (18,512)mode = args['upsample_mode']
# mode
# 'bilinear'定义了upsamplers(14+2+2=18个),解码器做上采样,恢复图片信息;(一般来说编码器做下采样,提取图片特征)
c) latent_to_image精读
这个方法在DatasetGAN、SemanticGAN、EditGAN中都有,其中EditGAN的版本格式最好。
从a)的latent_all中循环取latent_input(shape=[512]),同时传入g_all网络,upsamplers等
先判断是否适用参数use_style_latents,默认是否。然后会直接适用g_all的truncation生成style_latents(shape=[1,18,512])
#根据style_latents用生成网络获得img_list(shape=[1,3,1024,1024])和affine层(18个)
img_list, affine_layers = g_all.module.g_synthesis(style_latents)# 从affine的尺寸计算number_feature
# 8层x512 + 2层x256 + 2层x128 + 2层x64 + 2层x32 + 2层x16 = 5088
# 这个层设计跟upsamplers没有关系
# 定义affine_layers_upsamples(shape=[1,5088,512,512])
# 循环18次分段(channel)赋值
affine_layers_upsamples[:, start_channel_index:start_channel_index + len_channel] = upsamplers[i](affine_layers[i])# affine_layers_upsamples在prepare_data函数中就叫feature_maps(shape=[1,5088,512,512])
return img_list, affine_layers_upsamples# 循环给all_feature_maps_train(shape=(4194304,5088))赋值
# feature_maps(shape=[262144,5088]),其中512x512=262144
# 262144x16 = 4194304,其中latent_all=16d) pixel_classifier训练精读
这就是上面图中的(Ensemble Classifilers网络),它的分类数定义在配置
"testing_data_number_class": 34,for X_batch, y_batch in train_loader:
...
# x_batch, y_batch就是之前制作的train_data
y_pred = classifier(X_batch)
loss = criterion(y_pred, y_batch)算法结果:保存分类网络模型 pixel_classifier
五 训练与测试
5.1 训练
使用vscode打开子目录datasetGAN,创建下面的训练配置文件,使用Run –> Run without Debugging
{
"version": "0.2.0",
"configurations": [
{
"name": "Python: Current File",
"type": "python",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal",
"justMyCode": true,
"args": [
"--exp", "experiments/face_34.json"
]
}
]
}5.2 生成数据集
使用下面命令,生成语义标注数据集:
python train_interpreter.py \
--generate_data True --exp experiments/face_34.json \
--resume model_dir/face_34/ \
--num_sample 3生成位置:model_dir/face_34/samples
六 DatasetGAN应用举例
本节将使用DatasetGAN算法为DeepLabV3算法生成训练数据。
注:DeepLabV3是常见的图片语义分割算法,PaddleSeg中也有实现。
6.1 训练
python train_deeplab.py \
--data_path model_dir/face_34/samples \
--exp experiments/face_34.json 注:会下载deeplab算法预训练模型。
Save to: model_dir/face_34/deeplab_class_34_checkpoint_0_filter_out_0.000000/deeplab_epoch_19.pth训练代码细节如下:
...
# 加载本文生成的数据集
train_data = ImageLabelDataset(img_path_list=stylegan_images,
label_path_list=stylegan_labels, trans=trans_method,
img_size=(args['deeplab_res'], args['deeplab_res']))
train_data = DataLoader(train_data, batch_size=8, shuffle=True, num_workers=16)
# 下载deeplabv3_resnet101模型网络
classifier = torchvision.models.segmentation.deeplabv3_resnet101(pretrained=False, progress=False,num_classes=num_class, aux_loss=None)
...6.2 验证
python test_deeplab_cross_validation.py --exp experiments/face_34.json \
--resume model_dir/face_34/deeplab_class_34_checkpoint_0_filter_out_0.000000/ --cross_validate True cross validation mean: 0.006850441643981073
cross validation std: 0.00041275731314862506七、定制数据集生成器
7.1 训练自己的StyleGAN
datasetGAN/experiments/customized.json7.2 生成训练数据集
python datasetGAN/make_training_data.py --exp datasetGAN/experiments/customized.json --sv_path ./new_data这个脚本会在sv_path目录下生成:
- sample 图片
avg_latent_stylegan1.npylatent_stylegan1.npy
7.3 人工标注
按dataset_release中其他项目的格式去标注生成的数据并放入dataset_release目录即可。