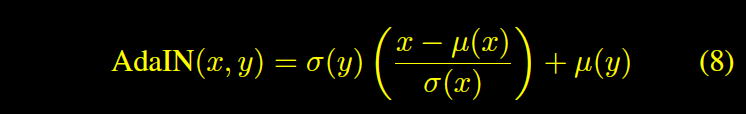目录

可随意转载! Update2022.08.11
前言
图片风格迁移(Style Transfer)最近5年非常火,它的前序技术叫纹理迁移(Texture Transfer)是图形学的一个重要分支,一般的方法是:先做纹理迁移,再做图像重建(Image Reconstruction)。
大神Gatys把神经网络引入了纹理迁移领域,利用VGG分类算法(附录)做图片高层语义的提取,然后训练过程中同时最小化原图和风格图的内容+风格相似性,图片重建得到迁移结果。
具体来说,Gatys提出了Gram矩阵,利用Grams矩阵特性优化风格相似。同时用VGG优化内容相似。经过多轮训练迭代内容和风格同时相似,这就是神经风格迁移(Neural Style Transfer)。
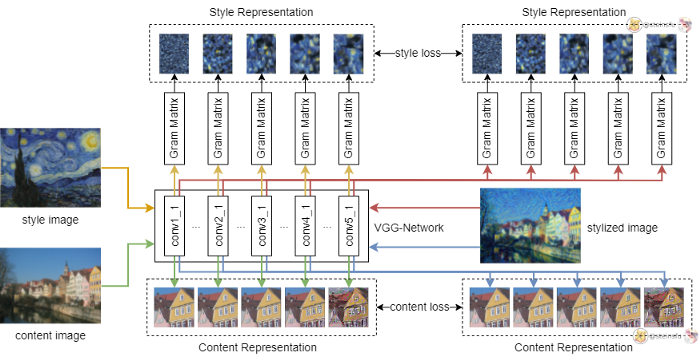
为什么Gram矩阵能表示(represent)风格?
论文《Demystifying Neural Style Transfer》的解释是:最小化Gram矩阵等同于最小化最大均值差异(maximum mean discrepancy, MMD)。通俗的说,最小化Gram矩阵就是最小化原图和风格图的激活分布(activation distributions),而这个激活分布就是style。
MMD:对于分布f1、f2,假如MMD=0,那么f1和f2就是同分布。
BN模块的均值和方差(mean & variance)正好包含了MMD的性状,因此最小化L2 Norm等同于最小化Gram矩阵。
网上StyleGAN pytorch版本比较多,本文以代码比较清晰、比较流行的rosinality版本为例。
一、G网络解读
1. style模块
这个style模块就是Z空间转W空间的网络。由一个PixelNorm接n_mlp个(8)EqualLinear。
layers = [PixelNorm()]
for i in range(n_mlp):
layers.append(
EqualLinear(
style_dim, style_dim, lr_mul=lr_mlp, activation="fused_lrelu"
)
)
self.style = nn.Sequential(*layers)注意:这个不是StyleConv
注意:StyleGAN2不需要PixelNorm,这个实现应该是多余了。
2. G网络尺寸
从4×4 逐步递增到1024×1024,这里是定义了以尺寸为key的map,在后面组建StyleBlock的时候会用到。
self.channels = {
4: 512,
8: 512,
16: 512,
32: 512,
64: 256 * channel_multiplier,
128: 128 * channel_multiplier,
256: 64 * channel_multiplier,
512: 32 * channel_multiplier,
1024: 16 * channel_multiplier,
}self.channels[4]等于512。
3. conv1(StyleConv)
是StyleConv(上图的灰色块),具体是ModulatedConv2d + NoiseInjection组合
self.conv1 = StyledConv(
self.channels[4], self.channels[4], 3, style_dim, blur_kernel=blur_kernel
)4. ToRGB
在PGGAN中使用的是1×1的conv,目的是保证输出到下一层的通道数是3。这里改成了ModulatedConv2d(请看下面的函数解析部分),作用跟原来1×1卷积相同。
self.to_rgb1 = ToRGB(self.channels[4], style_dim, upsample=False)class ToRGB(nn.Module):
def __init__(self, in_channel, style_dim, upsample=True, blur_kernel=[1, 3, 3, 1]):
super().__init__()
...
self.conv = ModulatedConv2d(in_channel, 3, 1, style_dim, demodulate=False)
self.bias = nn.Parameter(torch.zeros(1, 3, 1, 1))
def forward(self, input, style, skip=None):
out = self.conv(input, style)
out = out + self.bias
...5. G block
17层noise,16层StyleConv,8层ToRGB
每个Block由2个StyleConv和1个to_rgb构成。
# 4x4,8x8,16x16,32x32,64x64,128x128,256x256,512x512 总共8个block
# 17层对应4x4~1024x1024共9种分辨率
for layer_idx in range(self.num_layers):
res = (layer_idx + 5) // 2
shape = [1, 1, 2 ** res, 2 ** res]
self.noises.register_buffer(f"noise_{layer_idx}", torch.randn(*shape))
# i取值范围[3,10]
for i in range(3, self.log_size + 1):
# 这里用到了前面定义的channels map,比如2的三次方:8
out_channel = self.channels[2 ** i]
# 8个style_block
self.convs.append(
StyledConv(
in_channel,
out_channel,
3,
style_dim,
upsample=True,
blur_kernel=blur_kernel,
)
)
# 8个style_block
self.convs.append(
StyledConv(
out_channel, out_channel, 3, style_dim, blur_kernel=blur_kernel
)
)
# 8个ToRGB
self.to_rgbs.append(ToRGB(out_channel, style_dim))
二、工具类/方法解读
EqualLinear模块
出自progressiveGAN,跟F.linear基本一样只是改成了高斯weight。
ConstantInput
高斯常量输入
self.input = ConstantInput(self.channels[4]) ModulatedConv2d
考虑到最上图c部分,modulation、conv、norm组合,就是这个函数。modulation缩放了特征图等同于修改了conv的权重参数。IN的目的应该是归一化这个缩放,作者假定输入激活层是独立同分布(i.i.d),归一化目标可以直接用下面标准差实现:
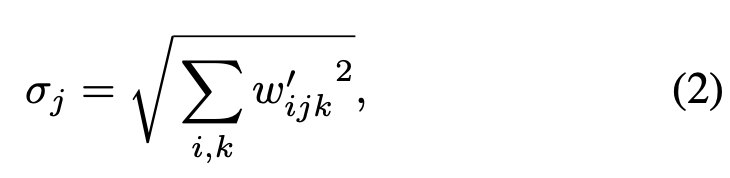
以上就是这个函数的原理。
Blur
《Making Convolutional Networks Shift-Invariant Again》论文参数了信号处理中利用低通滤波(low-pass filtering)消除混叠(anti-aliasing)的常见方法(Blur),并证明了在CNN中它也是很有作用的。
Upsample/Downsample
make_kernel
upfirdn2d
NoiseInjection
todo
FusedLeakyReLU
todo
附录
Norm为什么可以影响Style,什么是AdaIN?(英文)
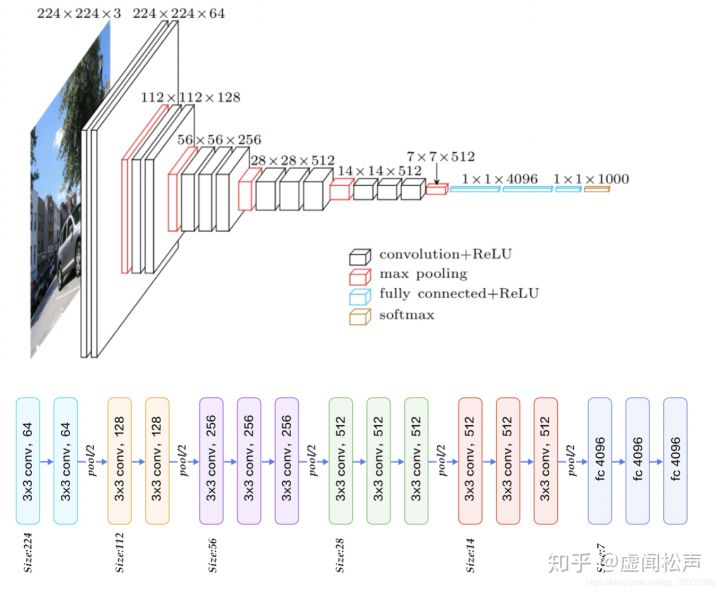
VGG网络结构
各种Norm理解

BN
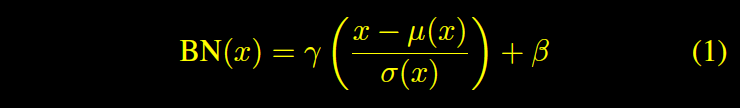
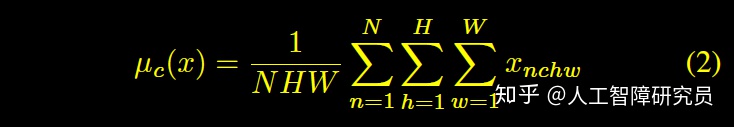
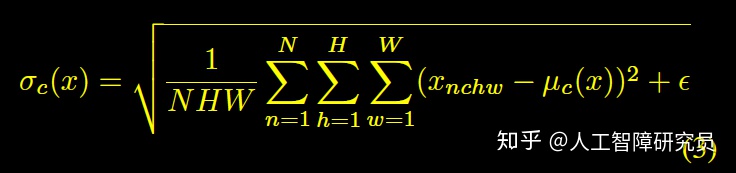
IN
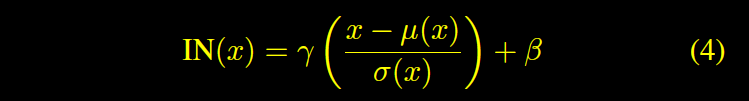
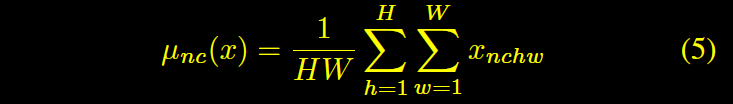
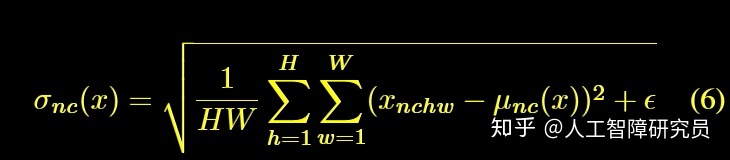
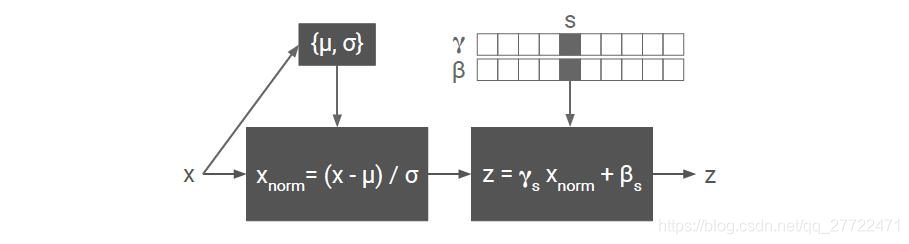
CIN
条件IN。
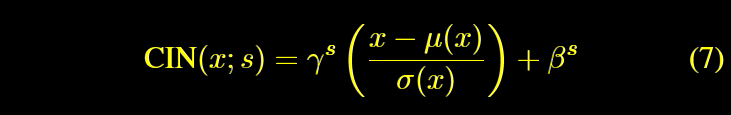
AdaIN
自适应IN,可以迁移任意多个styles。
将Content image的feature 转换,使其与style image的feature有相同的方差和均值即可实现style transfer