目录
经典算法YOLOv3解析。
禁止转载,侵权必究
前言
系列教程中我们介绍了图形分类的经典算法。那么在实际生活中,经常碰到这样的需求,在图中找到物体并标出它的分类和位置。技术上应该怎么实现呢?
我们可以把这个问题分解为2步,第一步是找到物体在图像中的位置(ROI),第二步是图像分类。因此最早的目标检测算法由此产生,R-CNN、Fast R-CNN、Faster R-CNN、Mask R-CNN。这些算法统一归类为两阶段目标检测算法。
经过数据科学家不断探索,在两阶段算法基础上又出现了一阶段算法,也就是说同时完成位置定位(ROI)和图像分类,比如:SSD、 YOLO(v1、v2、v3)
YOLOv3算法原理
Ground Truth Box 真实框GTB
数据中人工标识的物体真实位置。(x1, y1, x2, y2)
Anchor Box 锚框AB
对图像均分,然后再每个小格画3个框,框的大小是预设的。简而言之,就是用超参数来画格子,以此格子为基础来算bounding box。
Bounding Box 边界框BB
Bounding box是算法目标,我们要通过算法,把基本的anchor box去逼近标注的ground truth box,得到包含物体的那些边界框,这些计算得到的边界框又叫预测框pred_box。
IoU
算法中计算边界框和真实框的覆盖程度,数值越大越好。
计算过程
- 把训练图划分成小方块,比如一张640×480的图片,按32×32尺寸大小,一共可以分成20×15个区域。
- 以每个小方块中心为AB的中心,生成超参数[w, h]指定的3个AB,一共生成20x15x3 = 900个AB
- 遍历GTB,转换为块坐标,比如第2行第10列,块坐标为[2, 10]
- 通过计算IoU找到GTB对应的AB,微调AB计算预测框[bx, by, bh, bw],让预测框逼近真实框
- 算法的设计者要求bx,by 不能离开划定的小方块,同时bh,bw不允许为负数。这个约束条件导致算法不好实现。好在算法设计者给我们提出了解决方案。通过计算一组参数[tx, ty, th, tw],只要求它们为实数即可。
- 经过上面步骤,问题转化为计算AB的标注向量:objectness(是否包含物体),[tx, ty, th, tw](AB和GTB重合时的位置参数),classification(分类标签)。
- 我们把和GTB计算所得IoU最大的AB的objectness标识为1,其他两个AB标识为0。(例外情况:如果某个AB的IoU>0.7 但不是此小方块中最大的AB,标识为-1)
- [tx, ty, th, tw]参数组需要满足让此AB和GTB重合,可表示为下面四个代数公式:
- tx = gtx – cx (tx是sigmoid函数)
- ty = gty- cy (ty是sigmoid函数)
- tw = log( gtw/pw ) (log为自然对数e)
- th = log( gth/ph ) (log为自然对数e)
- classification(类型标签)采用了one-hot向量。比如我有5个分类,向量形如[0,0,1,0,0]或者[0,1,0,0,0]
- objectness!=1的AB或者说方块,不需要计算[tx, ty, th, tw]和classification
最终,我们得到了训练集上的objectness标签,location标签,classification标签。
为啥是sigmoid函数和自然对数e? 因为:以上四个算式都符合算法设计者对参数的约束条件。因此它是不唯一但是合理的代数表示。并且方程组是有解的。
BackBone骨干网络
所谓backbone就是我们做图像分类任务中的网络中截取的一部分。我们可以把它作为特征图提取来用。这部分网络统称骨干网络。AlexNet,VGG,RestNet以及它们的变种都有被用作BackBone。
Darknet53骨干网络
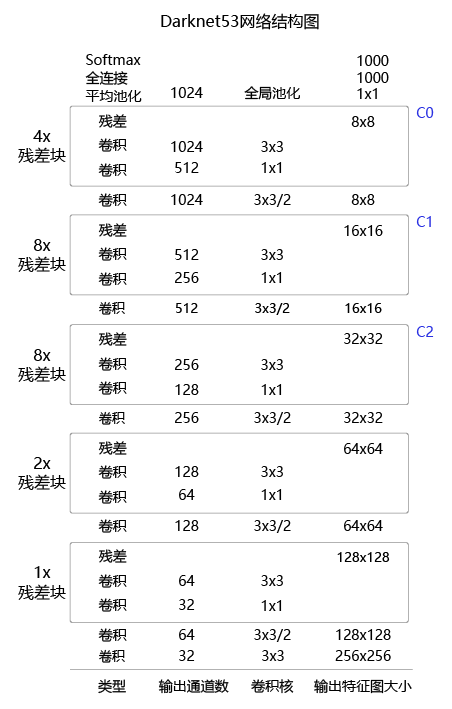
计算过程
以一张图片为例,原图表示为[1, 3, M, N],其中1表示一张图,3表示颜色通道,m = M/32 , n = N/32。其中32×32是我们划分AB时每个小方块的尺寸。
结合前面的分析,每个AB可以表示为位置4个维度,objectness1个维度,classification7个维度。总共12个维度表示一个AB。原图结合AB可以表示为数组:[1, 3×12, m, n] = [1, 36, m, n]
然而我们的Darknet53中C0的数组表示是:[1, 1024, m, n]。 因为它的输出通道为1024,stride为32。
为了能一步完成目标检测任务,我们需要通过一个叫YoloDetectionBlock的代码模块把1024个通道映射到AB区域上,也就是说要把1024个输出通道转换为36个输出通道使得算法能匹配每个AB所需要的特征图。同理C1,C2也是如此转换。
YoloDetectionBlock
我们仅仅以C0–>P0这个最基本的转换为例。下面的YoloDetectionBlock代码完成了从特征提取C0生成route(R0)和tip的工作。
注:route(R0)会用来跟C1做融合(concat)。
# 从骨干网络输出特征图C0得到跟预测相关的特征图P0
class YoloDetectionBlock(fluid.dygraph.Layer):
# define YOLO-V3 detection head
# 使用多层卷积和BN提取特征
def __init__(self,ch_in,ch_out,is_test=True):
super(YoloDetectionBlock, self).__init__()
assert ch_out % 2 == 0, \
"channel {} cannot be divided by 2".format(ch_out)
self.conv0 = ConvBNLayer(
ch_in=ch_in,
ch_out=ch_out,
filter_size=1,
stride=1,
padding=0,
is_test=is_test
)
self.conv1 = ConvBNLayer(
ch_in=ch_out,
ch_out=ch_out*2,
filter_size=3,
stride=1,
padding=1,
is_test=is_test
)
self.conv2 = ConvBNLayer(
ch_in=ch_out*2,
ch_out=ch_out,
filter_size=1,
stride=1,
padding=0,
is_test=is_test
)
self.conv3 = ConvBNLayer(
ch_in=ch_out,
ch_out=ch_out*2,
filter_size=3,
stride=1,
padding=1,
is_test=is_test
)
self.route = ConvBNLayer(
ch_in=ch_out*2,
ch_out=ch_out,
filter_size=1,
stride=1,
padding=0,
is_test=is_test
)
self.tip = ConvBNLayer(
ch_in=ch_out,
ch_out=ch_out*2,
filter_size=3,
stride=1,
padding=1,
is_test=is_test
)
def forward(self, inputs):
out = self.conv0(inputs)
out = self.conv1(out)
out = self.conv2(out)
out = self.conv3(out)
route = self.route(out)
tip = self.tip(route)
return route, tip再经过一层卷积就得到了P0,实现T0–>P0:
# 添加从ti生成pi的模块,这是一个Conv2D操作,输出通道数为3 * (num_classes + 5)
block_out = self.add_sublayer(
"block_out_%d" % (i),
Conv2D(num_channels=512//(2**i)*2,
num_filters=num_filters,
filter_size=1,
stride=1,
padding=0,
act=None,
param_attr=ParamAttr(
initializer=fluid.initializer.Normal(0., 0.02)),
bias_attr=ParamAttr(
initializer=fluid.initializer.Constant(0.0),
regularizer=L2Decay(0.))))
self.block_outputs.append(block_out)经过YOLOv3作者的精心设计经过网络转换后的数据含义如下:
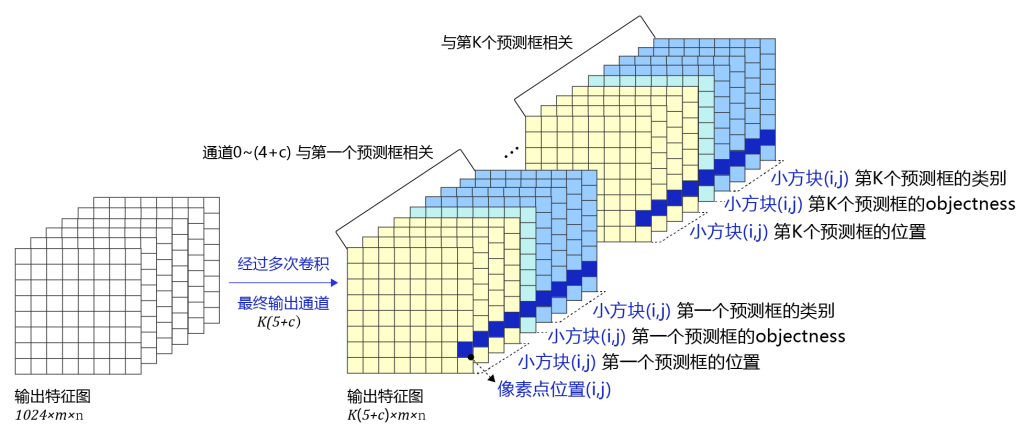
P0[t,0:12,i,j]与输入的第t张图片上小方块区域(i,j)(i, j)(i,j)第1个预测框所需要的12个预测值对应。
P0[t,12:24,i,j]P0[t, 12:24, i, j]P0[t,12:24,i,j]与输入的第t张图片上小方块区域(i,j)(i, j)(i,j)第2个预测框所需要的12个预测值对应。
P0[t,24:36,i,j]P0[t, 24:36, i, j]P0[t,24:36,i,j]与输入的第t张图片上小方块区域(i,j)(i, j)(i,j)第3个预测框所需要的12个预测值对应。
在P0中,P0[t,0:4,i,j]与输入的第t张图片上小方块区域(i,j)(i, j)(i,j)第1个预测框的位置对应,P0[t,4,i,j]P0[t, 4, i, j]P0[t,4,i,j]与输入的第t张图片上小方块区域(i,j)(i, j)(i,j)第1个预测框的objectness对应,P0[t,5:12,i,j]P0[t, 5:12, i, j]P0[t,5:12,i,j]与输入的第t张图片上小方块区域(i,j)(i, j)(i,j)第1个预测框的类别对应。
36个通道分成3组,每12个通道一组分别跟每个AB关联。
建立损失函数
我们有了训练集上的标签数据,又有了P0预测数据。那么我们就可以计算它们之间的损失函数了。
多尺度检测
因为我们有C0,C1,C2三个不同的尺度去计算特征图P0,P1,P2。其中C0最深,感受野最大,精度最高。但是它对小尺寸物体识别比较差。因此我们需要用C0–>P0的中间结果R0(因为R0数组做个简单的上采样大小就合适了)去和C1融合,既能够提供高精度,又能够在感受野比较小的区域识别小尺寸物体。同理C2。
Anchors依据的是COCO数据集中大小比较集中的9个尺寸,C0,C1,C2每个尺寸分别有3个AB。
下面是百度飞桨平台封装好的YOLOV3的损失函数调用方法:
def get_loss(self, outputs, gtbox, gtlabel, gtscore=None,
anchors = [10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326],
anchor_masks = [[6, 7, 8], [3, 4, 5], [0, 1, 2]],
ignore_thresh=0.7,
use_label_smooth=False):
"""
使用fluid.layers.yolov3_loss,直接计算损失函数,过程更简洁,速度也更快
"""
self.losses = []
downsample = 32
for i, out in enumerate(outputs): # 对三个层级分别求损失函数
anchor_mask_i = anchor_masks[i]
loss = fluid.layers.yolov3_loss(
x=out, # out是P0, P1, P2中的一个
gt_box=gtbox, # 真实框坐标
gt_label=gtlabel, # 真实框类别
gt_score=gtscore, # 真实框得分,使用mixup训练技巧时需要,不使用该技巧时直接设置为1,形状与gtlabel相同
anchors=anchors, # 锚框尺寸,包含[w0, h0, w1, h1, ..., w8, h8]共9个锚框的尺寸
anchor_mask=anchor_mask_i, # 筛选锚框的mask,例如anchor_mask_i=[3, 4, 5],将anchors中第3、4、5个锚框挑选出来给该层级使用
class_num=self.num_classes, # 分类类别数
ignore_thresh=ignore_thresh, # 当预测框与真实框IoU > ignore_thresh,标注objectness = -1
downsample_ratio=downsample, # 特征图相对于原图缩小的倍数,例如P0是32, P1是16,P2是8
use_label_smooth=False) # 使用label_smooth训练技巧时会用到,这里没用此技巧,直接设置为False
self.losses.append(fluid.layers.reduce_mean(loss)) #reduce_mean对每张图片求和
downsample = downsample // 2 # 下一级特征图的缩放倍数会减半
return sum(self.losses) # 对每个层级求和有了以上的基础代码,我们就可以开始训练AI识虫模型了。