目录
可随意转载 Update2024.06.21
发展历史
本文专业内容较多,没有论文&代码阅读能力的读者不用看了。
2022年4月,DALL E-2 来自OpenAI论文《Hierarchical Text-Conditional Image Generation with CLIP Latents》,本站翻译:unCLIP-使用CLIP隐码的文字引导图片生成
2022年5月,Imagen来自google的的论文《Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding》,使用了 T5(一种大语言模型)预训练模型代替CLIPx 模型做text encoder,因为text encoder是用现成的,所以算法更简单,且效果优于OpenAI的unCLIP算法(DALL E-2)。
Imagen开源版本:lucidrains/imagen-pytorch: Implementation of Imagen
2023年1月,google公司的论文《simple diffusion: End-to-end diffusion for high resolution images》分析了噪声的cosine scheduler效率问题、高分辨率下信噪比loss问题、Cascading DM改变分辨率时计算密度(flops/features),dropout,U-ViT替换U-Net等问题进行了实验,作者提出了简洁的高分辨率下的扩散算法(不同于LDM提出的在隐空间实现的扩散算法,展示了google的强大科研能力)。
2023年7月,开源模型SDXL在隐空间中,按simple diffusion的思路进行了优化并结合SDEdit做Refiner。但是它没有使用T5代替CLIPx(反映StabilityAI公司科研能力的差距)。
注:SDEdit(Stochastic Differential Editing)研究的是图片合成和编辑,类似PS。但是stable diffusion把它用来做img2img,先对图片做VAE编码得到init_latent,再用采样器的stochastic_encode做编码得到去噪中间值zx的目的(劫持)。
2023年9月,DALL E 3来自OpenAI的论文《Improving Image Generation with Better Captions》,论文发现训练的text-image数据集质量较差,导致T2I效果不如意,因此使用了google的CoCa数据集训练工具image captioner,用它自动生成的长的caption训练,并在推理时用gpt自动扩展用户的短caption,明显提升了(prompt following)效果。
2023年10月,华为和中科院论文PIXART-α采用了DiT(本站文章)为主干和T5预训练模型,并采用分阶段训练,降低了训练成本。
2023年12月,google公司发布了Imagen 2(闭源,没有任何技术报告!)
2024年1月, 华为和中科院论文《PIXART-δ: Fast and Controllable Image Generation with Latent Consistency Models》在 PIXART-α 基础上融入了LCM算法,进一步提升了推理的速度。
2024年2月,stabilityAI公司提出了Stable Cascade模型,它基于论文Würstchen v2架构(2023年6月)。
2024年2月,openAI发布了T2V模型Sora,技术要点猜测如下:使用了基于Patches的视频编码和解码网络(压缩);用了DiT;用了DALL E 3的captioner技术;用视频原始尺寸(大小)直接降维做训练;
2024年5月,腾讯混元文生图大模型开源,基于DiT架构,特点是支持中文提示词和多分辨率生成。
2024年6月,stable diffusion 3 Medium 模型参数(2B)开源,包含了三个不同的文本编码器 (CLIP L/14、OpenCLIP bigG/14和T5-v1.1-XXL) 、一个新提出的多模态 Diffusion Transformer (MMDiT) 模型,以及一个 16 通道的 AutoEncoder 模型 (与Stable Diffusion XL中的类似)。
Part1:论文《Imagen》
摘要
本论文介绍Imagen,一种照片级和深度语言理解能力的T2I(text-to-image)扩散模型。Imagen利用了LLM在理解文本方面的强大能力,并依赖于扩散模型在高保真图像生成方面的优势。我们发现是,LLM(例如T5),经过仅文本语料库的预训练,在编码文本以进行图像合成方面效果出奇地好:增加Imagen中的语言模型的大小,比增加图像扩散模型的大小更能提高样本保真度和图像文本对齐度。Imagen在COCO数据集上实现了新的最佳FID得分7.27,而且从未在COCO上进行过训练,人类评估者发现Imagen样本在图像文本对齐方面与COCO数据相当。为了更深入评估文本到图像模型,我们引入了DrawBench,这是一个全面且具有挑战性的文本到图像模型基准测试。使用DrawBench,我们将Imagen与包括VQ-GAN+CLIP,Latent Diffusion Models,GLIDE和DALL-E 2在内的最近方法进行比较,发现人类评估者在样本质量和图像文本对齐方面都更喜欢Imagen。
一、简介
最近,多模态学习已经受到了关注,T2I[53,12,57]和图像文本对比学习[49,31,74]处于最前沿。这些模型已经改变了研究社区,并通过创造性的图像生成[22,54]和编辑应用[21,41,34]吸引了广泛的关注。为了推动此项研究,我们发明了Imagen,这是一个T2I扩散模型,它结合了LLM[15,52]和当代先进的扩散模型[28,29,16,41],以在 T2I 合成中提供前所未有的照片真实度和深度语言理解能力。与CLIP等[例如,53,41]相比,Imagen发现是,LLM预训练模型对于T2I合成非常有效。
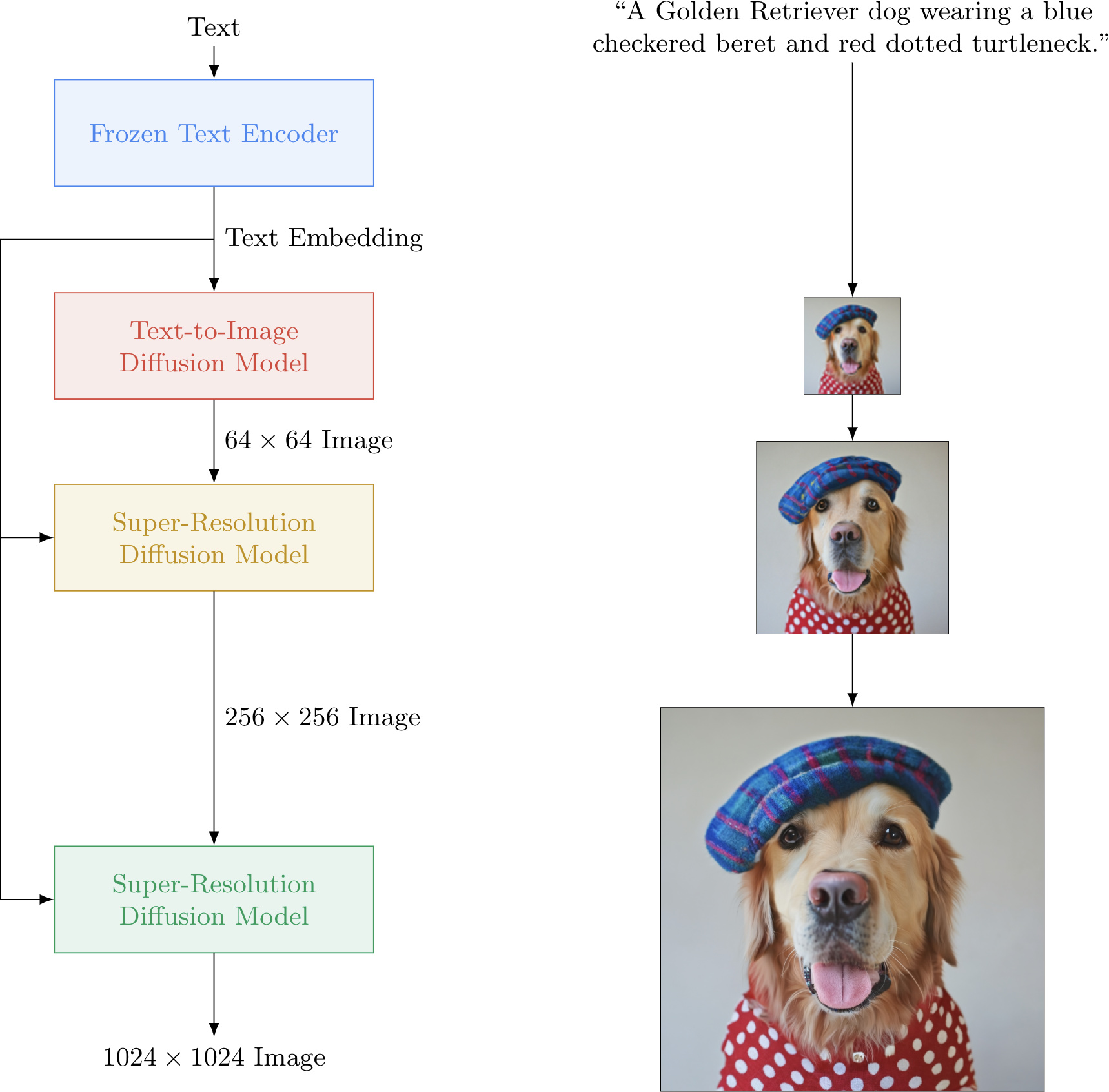
Imagen包括一个冻结的T5-XXL[52]编码器,用于将输入文本映射为一系列嵌入和一个64×64图像扩散模型,然后是两个超分辨率扩散模型,用于生成256×256和1024×1024的图像(见图A.4)。所有扩散模型都依赖于文本嵌入序列,并使用无分类器指导[27]。Imagen依赖于新的采样技术,以允许使用大的指导权重,而不会降低先前工作中观察到的样本质量,从而生成保真度更高,图像文本对齐度更好的图像。虽然概念上简单且易于训练,但Imagen产生了令人惊讶的强大结果。Imagen在COCO[36]上的表现优于其他方法,零样本FID-30K为7.27,显著优于先前的工作,如GLIDE[41](12.4)和DALL-E 2[54]的同时工作(10.4)。我们的零样本FID得分也优于在COCO上训练的最先进模型,例如,Make-A-Scene[22](7.6)。此外,人类评估者指出,来自Imagen的生成样本在图像文本对齐方面与COCO字幕上的参考图像相当。
我们引入了DrawBench,这是一个新的结构化的文本提示套件,用于文本到图像评估。DrawBench通过设计用于探测模型的不同语义属性的文本提示,使得对文本到图像模型的多维度评估
具有更深入的见解。这些包括组合性,基数,空间关系,处理复杂文本提示或含有罕见词汇的提示的能力,以及包括推动模型生成高度不可能的场景的创新提示,这些场景远远超出了训练数据的范围。通过DrawBench,大量的人类评估显示,Imagen在很大程度上优于其他最近的方法[57,12,54]。我们进一步展示了使用大型预训练语言模型[52]作为Imagen文本编码器的明显优点,而非如CLIP[49]这样的多模态嵌入。
本文的主要贡献包括:
- 预训练LLM模型对于T2I生成非常有效,而且,增大冻结文本编码器的大小比增大图像扩散模型的大小更能显著提高样本质量。
- 我们引入了动态阈值,这是一种新的扩散采样技术,可以利用大引导权重生成更真实和详细的图像。
- 我们强调了几个重要的扩散架构设计选择,并提出了Efficient U-Net,这是一种新的架构变体,它更简单,收敛更快且更节省内存。
- 我们在COCO上取得了新的最佳FID得分7.27。人类评估者发现,在图像文本对齐方面,Imagen与参考图像相当。
- 我们引入了DrawBench,这是一个新的全面且具有挑战性的文本到图像任务评估基准。在DrawBench的人类评估中,我们发现Imagen优于所有其他工作,包括DALLE-2。
二、Imagen
Imagen 由一个文本编码器构成,该编码器将文本映射到一系列嵌入,以及一系列条件扩散模型,这些模型将这些嵌入映射到逐渐增加分辨率的图像(参见图A.4)。在以下的小节中,我们将详细描述每一个组件。
2.1 预训练的文本编码器
文本到图像的模型需要强大的语义文本编码器,以捕获任意自然语言文本输入的复杂性和组合性。在当前的文本到图像模型中,对配对的图像-文本数据进行训练的文本编码器是标准的;它们可以从头开始训练,或者在图像-文本数据上进行预训练(CLIP)。图像-文本训练目标表明,这些文本编码器能产生对于文本到图像生成任务视觉语义有意义的表示。LLM可以是另一种选择,用于将文本编码为文本到图像生成。最近在LLM(如BERT,GPT,T5)上的发展已经在文本理解和生成能力上取得了巨大的突破。语言模型在比配对的图像-文本数据大得多的纯文本语料库上进行训练,因此接触到了非常丰富和广泛的文本分布。这些模型通常比当前图像-文本模型中的文本编码器大得多。因此,很自然地,我们会探索这两类文本编码器用于文本到图像的任务。图像探索了预训练的文本编码器:BERT,T5和CLIP。为了简单起见,我们冻结了这些文本编码器的权重。冻结有几个优点,比如离线计算嵌入,从而在训练文本到图像模型时几乎不需要计算或内存占用。在我们的工作中,我们发现有一个明确的信念,即提高文本编码器的规模可以提高文本到图像生成的质量。我们还发现,虽然T5-XXL和CLIP文本编码器在如MS-COCO这样的简单基准测试上表现相似,但人类评估者更喜欢T5-XXL编码器,而不是CLIP文本编码器,无论是在图像-文本对齐还是在DrawBench上的图像保真度上,这是一套具有挑战性和组合性的提示。我们将读者引向第4.4节以了解我们的发现的总结,并在附录D.1中进行详细的消融实验。
2.2 扩散模型-DM和无分类引导-CFG
我们简要介绍一下DM(详细的描述在附录A中) 。DM[63, 28, 65]是一类生成模型,它将高斯噪声通过迭代去噪过程转换为从学习的数据分布中的样本。这些模型可以是条件的,例如基于类标签、文本或低分辨率图像[例如16, 29, 59, 58, 75, 41, 54]。一个扩散模型xˆθ经过去噪目标形式的训练
Ex,c,ε,t[ wt||xˆθ(αtx + σt ε , c) − x||2 2 (1)
这里(x, c)是数据-条件配对,t ∼ U([0, 1]), ε ∼ N (0, I),αt, σt, wt是影响样本质量的t的函数。直观地说,xˆθ被训练成使用平方误差损失将噪声zt := αtx + σtε 降噪成x,以强调t的某些值。取样,例如祖先采样器[28]和DDIM [64],从纯噪声z1 ∼ N (0, I)开始,然后迭代生成点 zt1 , . . . , ztT ,其中1 = t1 > · · · > tT = 0,这些点的噪声含量逐渐减少。这些点是x预测xˆ t 0 := xˆθ(zt, c)的函数。
分类引导[16]是一种技术,可以在减少条件扩散模型中的多样性的同时改进样本质量,方法是在取样过程中使用来自预训练模型p(c|zt)的梯度。无分类引导(CFG)[27]是一种替代技术,它通过在训练过程中随机丢弃c(例如,以10%的概率),避免了这种预训练模型,而是共同训练一个扩散模型在条件和无条件目标上。取样是使用调整后的x预测 (zt − σ ε ˜ θ)/αt,其中
ε ˜θ(zt, c) = w ε θ(zt, c) + (1 − w) ε θ(zt) (2)
这里, ε θ(zt, c)和 ε θ(zt)是给定 ε θ := (zt − αtxˆθ)/σt的条件和无条件 ε -预测,w是引导权重。设置w = 1禁用无分类器引导,而增加w > 1增强了引导的效果。Imagen对于有效的文本条件化,严重依赖CFG。
2.3 大引导权重采样器
最近研究证实文本指导扩散[16, 41, 54],并发现增加引导权重可以改善图文对齐,但会损害图像保真度,产生高饱和度或不自然的图像[27]。我们发现这是因为高权重产生的train-test不匹配。算法要求采样步t的x的预测xˆt0 必须在训练数据x的bound(范围)内,即在[-1,1]之间,但是高权重会导致x的预测超出这个bound,由于采样过程的反复迭代累积错误,产生的图像就会出现不自然,甚至会发散。为了解决这个问题,我们研究了静态阈值和动态阈值。参见附录图A.31了解技术的参考实现,以及附录图A.9查看他们的效果的可视化。
静态阈值:我们将逐元素地将x预测裁剪到[-1,1]称为静态阈值。这种方法实际上在DDPM中已经使用过,但并没有被强调,据我们所知,其重要性在引导采样的上下文中尚未被研究。我们发现静态阈值对于使用大权重的采样至关重要,可以防止生成空白图像。然而,随着引导权重的进一步增加,静态阈值仍然会导致过饱和以及细节较少的图像。
注:DDPM中的静态阈值应该是下面一行(源代码链接):
def p_sample(self, denoise_fn, *, x, t, noise_fn, clip_denoised=True, repeat_noise=False):动态阈值:我们引入了一种新的动态阈值方法:在每个采样步骤中,我们将s设置为xˆ t 0中某个百分位数的绝对像素值,如果s>1,那么我们将xˆ t 0阈值到范围[-s, s],然后除以s。动态阈值将饱和像素(那些接近-1和1的像素)向内推,从而在每一步都积极防止像素饱和。我们发现,动态阈值在产生显著更好的照片写实性以及更好的图像-文本对齐方面,特别是在使用非常大的引导权重时,表现出色。
2.4 鲁棒的级联扩散模型
Imagen 使用一个基础的64×64模型和两个文本条件超分辨率扩散模型的管道,将一个64×64生成的图像上采样到一个256×256的图像,然后再到1024×1024的图像。使用噪声条件增强的级联扩散模型(cascaded diffusion model)在逐步生成高保真度图像方面非常有效。此外,通过噪声级别条件化,让超分辨率模型知道添加的噪声量,显著提高了样本质量,并帮助提高超分辨率模型处理由低分辨率模型缺陷的鲁棒性[29]。Imagen 对两个超分辨率模型都使用噪声条件增强。我们发现这对生成高保真度图像至关重要。 给定一个条件的低分辨率图像和增强级别(又名aug_level)(例如,高斯噪声或模糊的强度),我们用增强(对应于aug_level)破坏低分辨率图像,并将扩散模型条件化为aug_level。在训练期间,aug_level是随机选择的,而在推理期间,我们扫描其不同的值以找到最佳的样本质量。在我们的情况下,我们使用高斯噪声作为一种增强形式,并应用保持方差的高斯噪声增强,类似于扩散模型中使用的前向过程(附录A)。增强级别使用aug_level ∈ [0, 1]指定。参见图A.32了解参考伪代码。
注:Jonathan Ho等人2022年著作《Cascaded diffusion models for high fidelity image generation》;中文翻译。简单说就是:
- 定义:高分辨图片x0,低分辨率版本图片z0
- 定义pθ(z0)为低分辨率下的扩散模型,在低分辨率图z0上训练扩散模型
- 定义超分模型 pθ(x0|z0) ,训练低分辨率图z0提升分辨率到x0的扩散模型(对,也是扩散模型,原因可以看LDM github)
显而易见,Cascaded DM可写为:pθ(x0) = ∫pθ(x0|z0)pθ(z0) dz0,还可以推导出解决条件引导生成的性能更好的方法:先在低分辨率做条件引导生成pθ(z0|c),然后在做超分 pθ(x0|z0, c) ,并且在一个算法内完成全部需求。
2.5 神经网络架构
基础模型:我们从[40]中调整U-Net架构,用于我们的基础64×64文本到图像扩散模型。网络通过池化嵌入向量对文本嵌入进行条件化,添加到扩散时间步嵌入中,类似于[16, 29]中使用的类嵌入条件化方法。我们通过在多个分辨率上的文本嵌入上添加交叉关注[57],进一步对整个文本嵌入序列进行条件化。我们在附录D.3.1中研究了各种文本条件化方法。此外,我们发现对于关注和池化层中的文本嵌入,层正则化[2]大大提高了性能。
超分辨率模型:对于64×64→256×256超分辨率,我们使用从[40, 58]调整的U-Net模型。我们对这个U-Net模型进行了几个修改,以提高内存效率,推理时间和收敛速度(我们的变体在步数/秒上比[40, 58]中使用的U-Net快2-3倍)。我们将这个变体称为Efficient U-Net(有关更多详情和比较,请参见附录B.1)。我们的256×256→1024×1024超分辨率模型在1024×1024图像的64×64→256×256剪裁上进行训练。为了方便这一点,我们移除了自我注意层,但我们保留了我们发现至关重要的文本交叉关注层。在推理过程中,模型接收完整的256×256低分辨率图像作为输入,并返回上采样的1024×1024图像作为输出。注意,我们对两个超分辨率模型都使用了文本交叉关注。
Part2:论文《SDXL》
下面的内容不是逐字逐句翻译,总体上看SDXL论文是一篇工程改进的paper。
二、架构
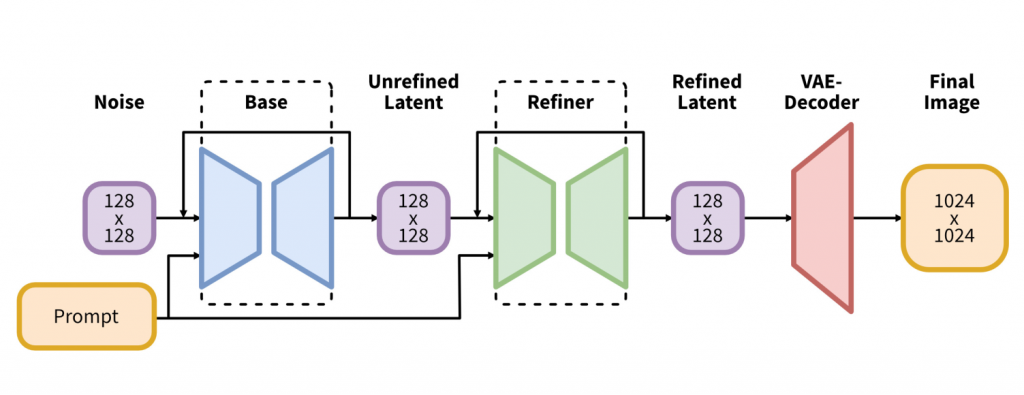
2.1 架构
随着扩散模型的发展,底层架构不断演变:从添加self-attention和改进的upscale层 [5],到T2I合成的cross-attention [38],再到纯transformer架构 [33]。 我们遵循这一趋势,并根据《simple diffusion》的方法将transformer计算的大部分转移到UNet的低层特征中。
2.2 微条件
用图片尺寸作为条件
SD训练的问题是为了训练512×512的图,只能丢弃小于这个分辨率的训练数据。SDXL的方法是在训练中将图像的h和w作为模型csize = (horiginal, woriginal)的额外调节条件。使用傅立叶特征编码(Fourier feature encoding)进行独立embedding,将其添加到时间步的embedding中来输入模型。模型已经学习将csize条件与分辨率相关的图像特征关联起来,这可以用来修改对应于给定提示的输出的外观。在推理阶段,用户可以通过这种大小调节来设定图像的期望分辨率。
用裁剪参数做条件
为了将图片统一大小,预处理时会用到裁剪(比如:裁掉了半个头)这些样本造成不好的效果。 为了解决这个问题,我们提出了另一种简单而有效的条件方法:在数据加载过程中,我们均匀地采样裁剪坐标ctop和cleft,并将它们通过傅立叶特征嵌入的方式作为条件参数输入到模型中,类似于上述的尺寸调节。然后使用串联的嵌入ccrop作为额外的条件参数。 注意,上述两种方法可以组合,将其添加到UNet中的时间步嵌入之前,沿着通道维度连接特征嵌入(如论文中的算法1所示)。
2.3 多比例调解
实际世界的数据集包括各种大小和纵横比的图像。扩散模型常见分辨率是512×512或1024×1024像素的正方形图像,但这是相当不自然的。我们在预训练模型在固定的纵横比和分辨率后,将多纵横比训练作为微调阶段,并将其与上述条件技术通过channel axis的concat起来。
注:论文中提供了傅里叶特征编码,条件组合channel axis的concat源码。
2.4 训练了一个新的VAE
SDXL-VAE比SD的有提升
三、 Refiner
用高分辨率,高质量的图片训练了Refiner。使用论文《SDEdit》的方法做img2img,它可以提高详细背景和人脸样本的质量。
代码实操
stabilityai/stable-diffusion-xl-base-1.0 base模型可以单独使用也可以和refiner模型结合使用。
stabilityai/stable-diffusion-xl-refiner-1.0 refiner模型可以用来改进图片。
sdxl-all.ipynb – Colab SDXL的使用方法和效果,使用了refiner在耳朵和眼睛细节有明显提升
Part3: 论文《PixArt》两篇
下面的内容不是逐字逐句翻译,
一、简介
先前的论文和实验证明,T2I应该分解成三个子任务:
- 学习自然图像的像素分布:从低分辨率的class分类引导扩散初始化
- 学习文本图像对齐:用加过captions的数据集训练图文对齐模型
- 提高图像的美学质量:在高质量图片上做美学fine-tune
引入了DiT,并使用重参数(re-parameterization)技术使得T2I条件生成可以复用用class标签的预训练的生成模型(之前有论文说到,class标签可以有效提升FID,并且数据丰富)。
用llava给SAM数据集加captions(类似 DALLE 3的image captioner),解决LAION数据集被广泛诟病的标注不详细的问题。
二、修改DiT
class PixArtBlock(nn.Module):
"""
A PixArt block with adaptive layer norm (adaLN-single) conditioning.
"""
def __init__(self, hidden_size, num_heads, mlp_ratio=4.0, drop_path=0., window_size=0, input_size=None, use_rel_pos=False, **block_kwargs):
super().__init__()
self.hidden_size = hidden_size
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
# 改为了WindowAttention
self.attn = WindowAttention(hidden_size, num_heads=num_heads, qkv_bias=True,
input_size=input_size if window_size == 0 else (window_size, window_size),
use_rel_pos=use_rel_pos, **block_kwargs)
self.cross_attn = MultiHeadCrossAttention(hidden_size, num_heads, **block_kwargs)
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
# to be compatible with lower version pytorch
approx_gelu = lambda: nn.GELU(approximate="tanh")
self.mlp = Mlp(in_features=hidden_size, hidden_features=int(hidden_size * mlp_ratio), act_layer=approx_gelu, drop=0)
# 增加了DropPath
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.window_size = window_size
# 论文作者把这个算子叫adaLN-single
self.scale_shift_table = nn.Parameter(torch.randn(6, hidden_size) / hidden_size ** 0.5)
def forward(self, x, y, t, mask=None, **kwargs):
B, N, C = x.shape
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = (self.scale_shift_table[None] + t.reshape(B, 6, -1)).chunk(6, dim=1)
x = x + self.drop_path(gate_msa * self.attn(t2i_modulate(self.norm1(x), shift_msa, scale_msa)).reshape(B, N, C))
x = x + self.cross_attn(x, y, mask)
x = x + self.drop_path(gate_mlp * self.mlp(t2i_modulate(self.norm2(x), shift_mlp, scale_mlp)))
return x对比DiTBlock 源码,我们在 DiT 块中加入了MultiHeadCrossAttention,使模型可以从语言模型中提取的文本嵌入进行交互。为了方便预训练权重,我们将交叉注意力层中的输出投影层初始化为0,有效地作为一个恒等映射,保留了对后续层的输入。
我们发现在AdaLN中,线性投影占了大量参数(27%)。我们的T2I 模型没有使用class标签作为条件,所以我们提出了 adaLN-single减少了参数量。
重参数技术:所有的E(i)都被初始化为可以产生与选定的t (经验上,我们使用t=500) 相同的S(i)的DiT(没有c的)的值。这种设计有效地将特定层的多层感知机(MLP)替换为全局多层感知机和特定层的可训练嵌入,同时保持与预训练权重的兼容性。
点评:
| 模型 | Unet参数量 | Text-Encoder名称和参数量 | 说明 |
| SD1.5 | 860M | OpenAI CLIP ViT-L/14 428M | openai/clip-vit-large-patch14 |
| SD2.0 | 865M | OpenCLIP ViT-H/14 986M | laion/CLIP-ViT-H-14-laion2B-s32B-b79K |
| SDXL | 2.6B | OpenAI CLIP ViT-L/14 + OpenCLIP ViT-bigG/14 | laion/CLIP-ViT-bigG-14-laion2B-39B-b160k |
| PixArt | 0.6B | T5(4.3B) | google/t5-v1_1-xxl |
SDXL的Unet参数量比SD大了3000倍; PixArt的DiT参数量比SD大了700倍。
Part4:Stable Diffusion Cascade
这篇技术报告来自2023年6月的论文Wuerstchen。
论文《Wuerstchen》主要贡献:
- 三阶段的架构,在42:1的压缩下进行T2I训练,包括2个条件隐空间扩散和一个latent to image 解码器
- 42:1高压缩的T2I训练的高性能
- 一个基于自动化和人类辅助的验证方法
- 公开源码和pretrained权重
训练阶段A:还是训练VAE,用的还是VQGAN
训练阶段B:用了EfficientV2_S( 在ImageNet 1K上训练 )做语义压缩
训练阶段C:16个ConvNeXt(没有下/上采样),应用时间步和text条件
点评:
Jonathan Ho 早在2020年就提出来了Cascade的方法;低分辨率下隐空间训练(LDM方法)也已经是共识了(simple diffusion除外);Wuerstchen论文早在2023年6月就提出来了,论文发现在高分辨率下扩散效果不行,就转向低分辨扩散。直接用EfficientV2压缩了42倍,也不需要用Unet进一步降低分辨率了,也算是工程上的创新优化。其中用到的ConvNeXt来自META的著名论文(本站翻译)
本来SD就已经包含了VAE,CLIP,Unet三个模型了,SDXL又增加了Refiner,stable cascade又将Unet改为EfficientV2_S(预训练)+ConvNeXt模型,这个技术路线肯定是倒退的。
从架构上DiT肯定是优于Unet,性能上PCA肯定是优于VAE的,不理解StabilityAI公司这时候炒剩饭有什么意义。
Part5:Stable Diffusion 3
SD3技术报告:地址
5.1 损失函数的论证和优化
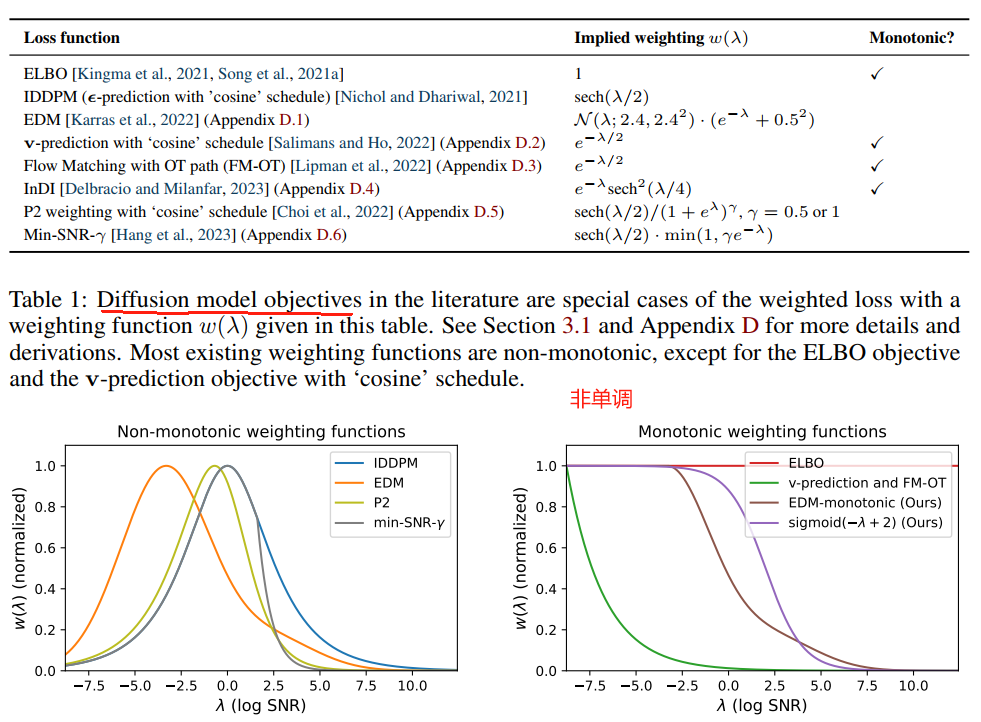
谷歌的论文《Understanding diffusion objectives as the elbo with simple data augmentation》从ELBO理论高度统一了各种扩散模型的损失函数,得出了看似不同的损失函数本质是带权重的ELBO变体(尤其是单调权重函数w,本质是ELBO+高斯扰动)。论文得出了各个权重(weight)值:
得出了统一的损失函数公式(带权重w),本文没有copy此公式。
论文概要:扩散和去噪是二维联合概率密度Path(x,t)的一种特例,因此训练过程可以用RF做损失函数,会更快更好(下面的论文比上面论文更早发表,请仔细看图,其中包含了RF方法)
SD3论文参考了Meta论文《FLOW MATCHING FOR GENERATIVE MODELING》通过边缘密度函数和Conditional Flow Matching(CFM)推导了SD3自己的损失函数RF‘,并按照统一的损失函数公式给出了这个RF’下的权重Wt 和信噪比λ与偏置b的数学关系:
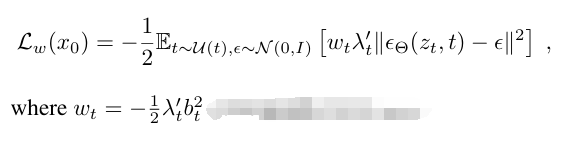
注:RF损失函数优化主要目的是秀肌肉了,因为RF损失函数影响模型训练收敛速度,普通开发者玩不起从0训练,只能看个热闹。
5.2 采样方法的优化
采取了Meta论文的分析结论,简单列举了Rectified Flow(RF),EDM,Cosine,Linear(LDM中默认的)几种去噪scheduler方法,最终SD3改进了RF调度器。
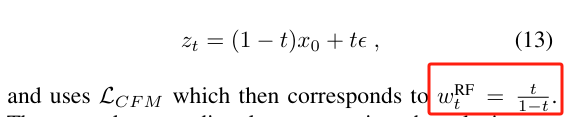
SD3论文发现RF损失在所有时间步上均匀采样,觉得不好改为带密度的采样(保证中间部分采样更多,本质是加权)。其中一种加权算法是对数正态分布(logit-normal distribution),但是这个分布在0和1这两个端点上值趋近于0,又搞了一些花样保证端点不为0。然后还考虑了在RF损失采用中再引入cos方法。
注意:采样器的各种论文本来就很多了,SD3又整了一个活。
5.3 去噪扩散模型网络架构
首先从Unet切换到了DiT框架,这个在之前部分已经论证过基于Transformer架构的优点,就不赘述了。
IP-Adapter论文已经发现了CrossAttention的缺陷,它采用了解耦的CrossAttention,InstantID论文也采用了解耦的CrossAttention。SD3中更进一步,重新设计了CrossAttention,新的网络结构如下:
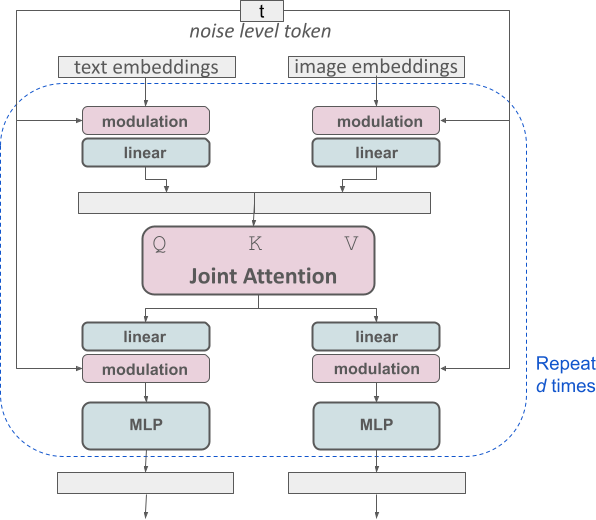
注:网络结构创新应该是相当硬核了,非常牛逼
5.4 其他创新
改进了VAE,加大了latent channels (d=16)。这个结论在L-DAE解构扩散模型实现自监督学习这篇文章中有更详尽的分析。
长文字的好处之前已经论述过了,SD3也发现了并使用了CogVLM做captioner。这个CogVLM是清华系的,给中国人长脸了。