目录
前言
请勿转载,违法必究
英伟达2015年4月论文《Describe Anything: Detailed Localized Image and Video Captioning》https://github.com/NVlabs/describe-anything.git
解决问题:为图像和视频中的特定区域生成详细且准确的描述。
主要贡献:
- 为了解决高质量DLC数据稀缺的问题,我们提出了一个基于半监督学习(SSL)的数据管道(DLC-SDP)
- 创造了用于评估DLC的基准测试DLC-Bench
- 提出了一个为详细局部描述Detailed Localized Captioning (DLC)设计的模型Describe Anything Model(DAM)
注意:DAM是非商用协议,所以想直接抄袭的就不用看了
一、研究内容

二、代码解析
2.1 关键代码逻辑
dam\describe_anything_model.py中函数get_description最终调用get_description_from_prompt_iterator函数,构造输入参数:
generation_kwargs = dict(
input_ids=input_ids,
images=image_tensors,
do_sample=True if temperature > 0 else False,
use_cache=True,
stopping_criteria=[stopping_criteria],
streamer=streamer,
temperature=temperature,
top_p=top_p,
num_beams=num_beams,
max_new_tokens=max_new_tokens,
**kwargs
)然后调用DAM模型生成结果
...
else:
with torch.inference_mode():
output_ids = self.model.generate(**generation_kwargs)
outputs = self.tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0]
outputs = outputs.strip()
if outputs.endswith(stop_str):
outputs = outputs[: -len(stop_str)]
outputs = outputs.strip()
yield outputs2.2 参数解析
- input_ids由tokenizer_image_token函数从prompt处理而来。
- image_tensors由get_image_tensor函数从image_pil,mask_pil裁剪而来。
三、模型解析
3.1 视觉大语言模型VILA1.5-3b
经过分析,DAM nvidia/DAM-3B HuggingFace 依赖英伟达自家的视觉大语言模型 Efficient-Large-Model/VILA1.5-3b HuggingFace,如下图所示:
注意:llm,mm_projector,vision_tower文件夹与英伟达VILA1.5(类似qwen2.5-vl)是完全相同的,这些模型文件不属于DAM。
VILA1.5 基于LLAVA架构,这里不做延伸学习和深入代码剖析,直接跳过。
3.2 context_provider实现了DAM的核心逻辑
dam\model\llava_arch.py中encode_images_with_context函数,核心代码:
# Process the first 4 channels for all images: for image it's the image, for cimage it's the full image
vision_tower = self.get_vision_tower()
# Encode context images (full images)
image_features = vision_tower(images[:, :4, ...]).to(self.device)
# Each cimage has 8 channels (full and crop concatenated), cimage是image with context的缩写
cimage_concatenated = images[cimage_mask]
cimage_full_features = image_features[cimage_mask]
if context_provider.context_provider_type == "cross_attn_end_to_all":
cimage_features = self.context_provider(
cimage_full_features=cimage_full_features,
cimage_concatenated=cimage_concatenated,
vision_tower=vision_tower
).to(self.device)
elif context_provider.context_provider_type == "concat":
# Full features of cimages are computed but not used.
cimage_features = self.context_provider(
cimage_concatenated=cimage_concatenated,
vision_tower=vision_tower
).to(self.device)对应论文中的:
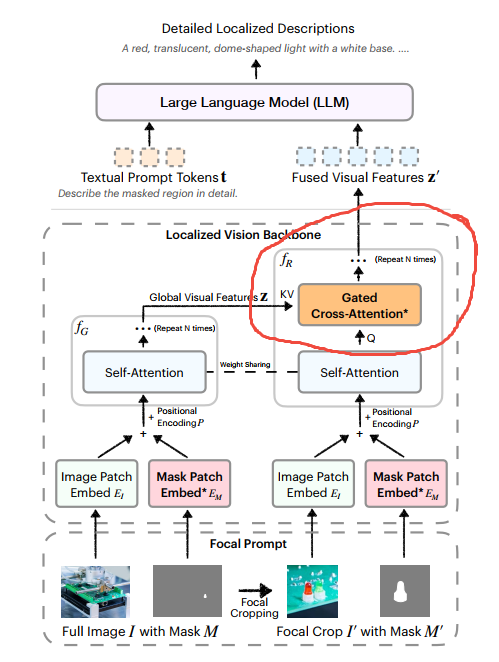
3.3 SAM(SAM2)的作用
给DAM做一个Mask,理论上用YOLO也可以。
四、YOLO+DAM魔改
TODO